 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAMOS: A Hierarchical Vision-Language-Action Model for Capability-Modulated and Steerable Navigation
Oct 23, 2025A fundamental challenge in robot navigation lies in learning policies that generalize across diverse environments while conforming to the unique physical constraints and capabilities of a specific embodiment (e.g., quadrupeds can walk up stairs, but rovers cannot). We propose VAMOS, a hierarchical VLA that decouples semantic planning from embodiment grounding: a generalist planner learns from diverse, open-world data, while a specialist affordance model learns the robot's physical constraints and capabilities in safe, low-cost simulation. We enabled this separation by carefully designing an interface that lets a high-level planner propose candidate paths directly in image space that the affordance model then evaluates and re-ranks. Our real-world experiments show that VAMOS achieves higher success rates in both indoor and complex outdoor navigation than state-of-the-art model-based and end-to-end learning methods. We also show that our hierarchical design enables cross-embodied navigation across legged and wheeled robots and is easily steerable using natural language. Real-world ablations confirm that the specialist model is key to embodiment grounding, enabling a single high-level planner to be deployed across physically distinct wheeled and legged robots. Finally, this model significantly enhances single-robot reliability, achieving 3X higher success rates by rejecting physically infeasible plans. Website: https://vamos-vla.github.io/
Long Range Navigator (LRN): Extending robot planning horizons beyond metric maps
Apr 17, 2025A robot navigating an outdoor environment with no prior knowledge of the space must rely on its local sensing to perceive its surroundings and plan. This can come in the form of a local metric map or local policy with some fixed horizon. Beyond that, there is a fog of unknown space marked with some fixed cost. A limited planning horizon can often result in myopic decisions leading the robot off course or worse, into very difficult terrain. Ideally, we would like the robot to have full knowledge that can be orders of magnitude larger than a local cost map. In practice, this is intractable due to sparse sensing information and often computationally expensive. In this work, we make a key observation that long-range navigation only necessitates identifying good frontier directions for planning instead of full map knowledge. To this end, we propose Long Range Navigator (LRN), that learns an intermediate affordance representation mapping high-dimensional camera images to `affordable' frontiers for planning, and then optimizing for maximum alignment with the desired goal. LRN notably is trained entirely on unlabeled ego-centric videos making it easy to scale and adapt to new platforms. Through extensive off-road experiments on Spot and a Big Vehicle, we find that augmenting existing navigation stacks with LRN reduces human interventions at test-time and leads to faster decision making indicating the relevance of LRN. https://personalrobotics.github.io/lrn
Demonstrating Wheeled Lab: Modern Sim2Real for Low-cost, Open-source Wheeled Robotics
Feb 11, 2025
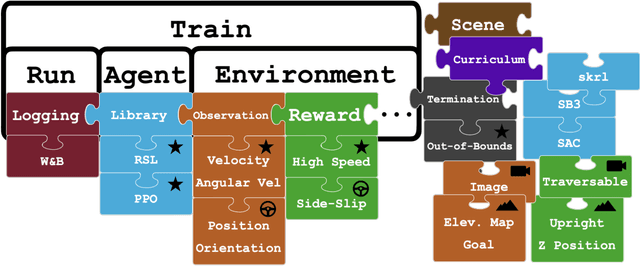

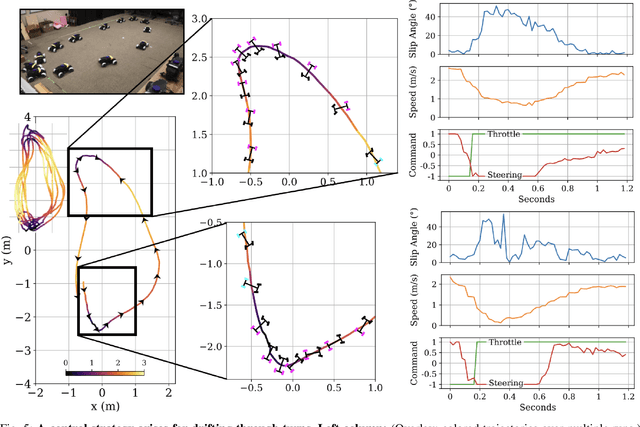
Simulation has been pivotal in recent robotics milestones and is poised to play a prominent role in the field's future. However, recent robotic advances often rely on expensive and high-maintenance platforms, limiting access to broader robotics audiences. This work introduces Wheeled Lab, a framework for the low-cost, open-source wheeled platforms that are already widely established in education and research. Through integration with Isaac Lab, Wheeled Lab introduces modern techniques in Sim2Real, such as domain randomization, sensor simulation, and end-to-end learning, to new user communities. To kickstart education and demonstrate the framework's capabilities, we develop three state-of-the-art policies for small-scale RC cars: controlled drifting, elevation traversal, and visual navigation, each trained in simulation and deployed in the real world. By bridging the gap between advanced Sim2Real methods and affordable, available robotics, Wheeled Lab aims to democratize access to cutting-edge tools, fostering innovation and education in a broader robotics context. The full stack, from hardware to software, is low cost and open-source.
Agile Continuous Jumping in Discontinuous Terrains
Sep 17, 2024



We focus on agile, continuous, and terrain-adaptive jumping of quadrupedal robots in discontinuous terrains such as stairs and stepping stones. Unlike single-step jumping, continuous jumping requires accurately executing highly dynamic motions over long horizons, which is challenging for existing approaches. To accomplish this task, we design a hierarchical learning and control framework, which consists of a learned heightmap predictor for robust terrain perception, a reinforcement-learning-based centroidal-level motion policy for versatile and terrain-adaptive planning, and a low-level model-based leg controller for accurate motion tracking. In addition, we minimize the sim-to-real gap by accurately modeling the hardware characteristics. Our framework enables a Unitree Go1 robot to perform agile and continuous jumps on human-sized stairs and sparse stepping stones, for the first time to the best of our knowledge. In particular, the robot can cross two stair steps in each jump and completes a 3.5m long, 2.8m high, 14-step staircase in 4.5 seconds. Moreover, the same policy outperforms baselines in various other parkour tasks, such as jumping over single horizontal or vertical discontinuities. Experiment videos can be found at \url{https://yxyang.github.io/jumping\_cod/}.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Stein Variational Probabilistic Roadmaps
Nov 04, 2021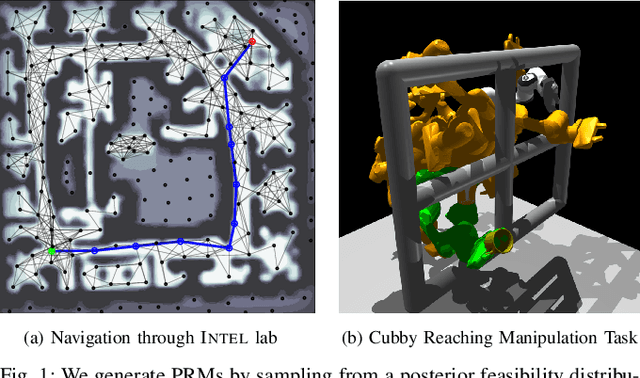
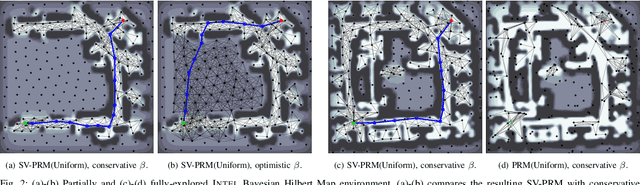
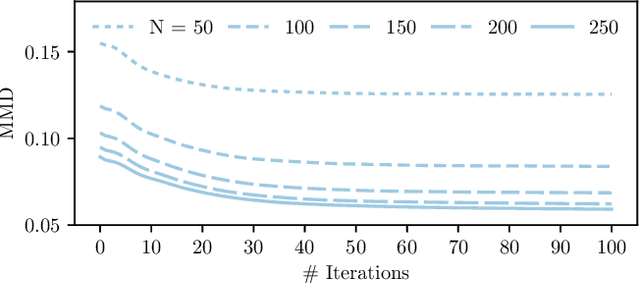
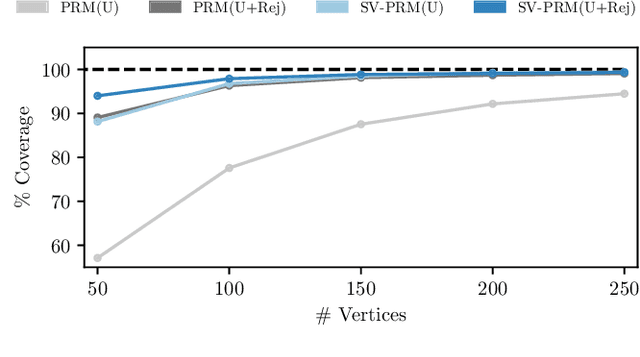
Efficient and reliable generation of global path plans are necessary for safe execution and deployment of autonomous systems. In order to generate planning graphs which adequately resolve the topology of a given environment, many sampling-based motion planners resort to coarse, heuristically-driven strategies which often fail to generalize to new and varied surroundings. Further, many of these approaches are not designed to contend with partial-observability. We posit that such uncertainty in environment geometry can, in fact, help \textit{drive} the sampling process in generating feasible, and probabilistically-safe planning graphs. We propose a method for Probabilistic Roadmaps which relies on particle-based Variational Inference to efficiently cover the posterior distribution over feasible regions in configuration space. Our approach, Stein Variational Probabilistic Roadmap (SV-PRM), results in sample-efficient generation of planning-graphs and large improvements over traditional sampling approaches. We demonstrate the approach on a variety of challenging planning problems, including real-world probabilistic occupancy maps and high-dof manipulation problems common in robotics.
Guided Incremental Local Densification for Accelerated Sampling-based Motion Planning
Apr 11, 2021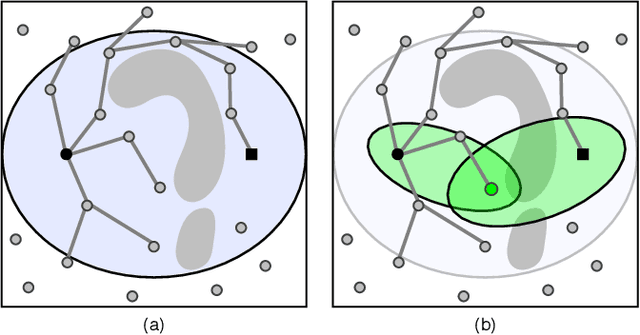
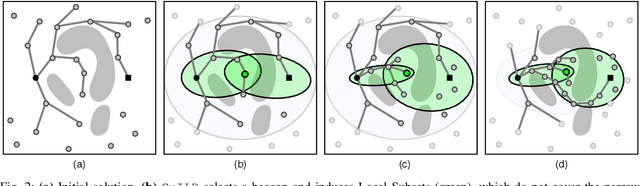
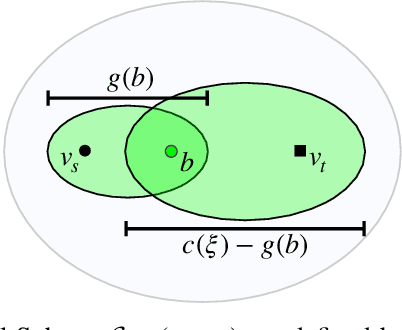
Sampling-based motion planners rely on incremental densification to discover progressively shorter paths. After computing feasible path $\xi$ between start $x_s$ and goal $x_t$, the Informed Set (IS) prunes the configuration space $\mathcal{C}$ by conservatively eliminating points that cannot yield shorter paths. Densification via sampling from this Informed Set retains asymptotic optimality of sampling from the entire configuration space. For path length $c(\xi)$ and Euclidean heuristic $h$, $IS = \{ x | x \in \mathcal{C}, h(x_s, x) + h(x, x_t) \leq c(\xi) \}$. Relying on the heuristic can render the IS especially conservative in high dimensions or complex environments. Furthermore, the IS only shrinks when shorter paths are discovered. Thus, the computational effort from each iteration of densification and planning is wasted if it fails to yield a shorter path, despite improving the cost-to-come for vertices in the search tree. Our key insight is that even in such a failure, shorter paths to vertices in the search tree (rather than just the goal) can immediately improve the planner's sampling strategy. Guided Incremental Local Densification (GuILD) leverages this information to sample from Local Subsets of the IS. We show that GuILD significantly outperforms uniform sampling of the Informed Set in simulated $\mathbb{R}^2$, $SE(2)$ environments and manipulation tasks in $\mathbb{R}^7$.
Improving Robot Success Detection using Static Object Data
Apr 02, 2019
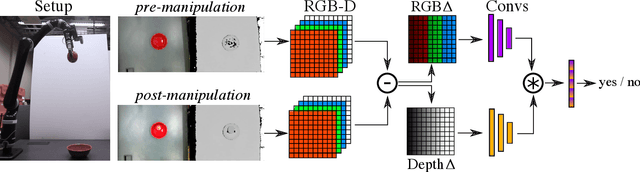
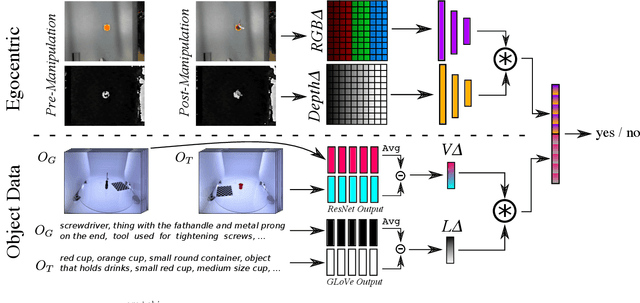
We use static object data to improve success detection for stacking objects on and nesting objects in one another. Such actions are necessary for certain robotics tasks, e.g., clearing a dining table or packing a warehouse bin. However, using an RGB-D camera to detect success can be insufficient: same-colored objects can be difficult to differentiate, and reflective silverware cause noisy depth camera perception. We show that adding static data about the objects themselves improves the performance of an end-to-end pipeline for classifying action outcomes. Images of the objects, and language expressions describing them, encode prior geometry, shape, and size information that refine classification accuracy. We collect over 13 hours of egocentric manipulation data for training a model to reason about whether a robot successfully placed unseen objects in or on one another. The model achieves up to a 57% absolute gain over the task baseline on pairs of previously unseen objects.
Balancing Shared Autonomy with Human-Robot Communication
May 20, 2018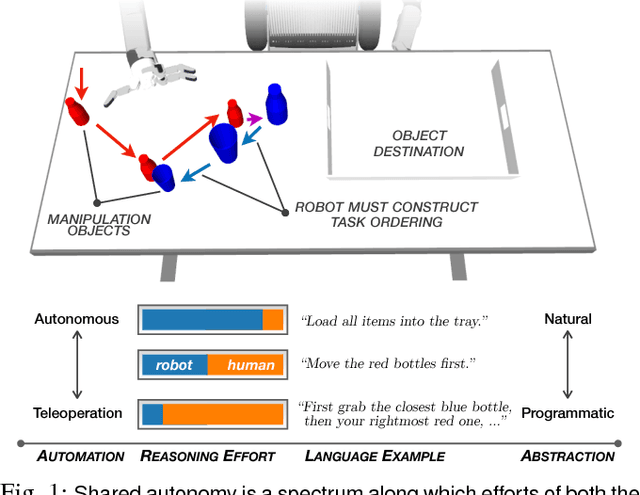
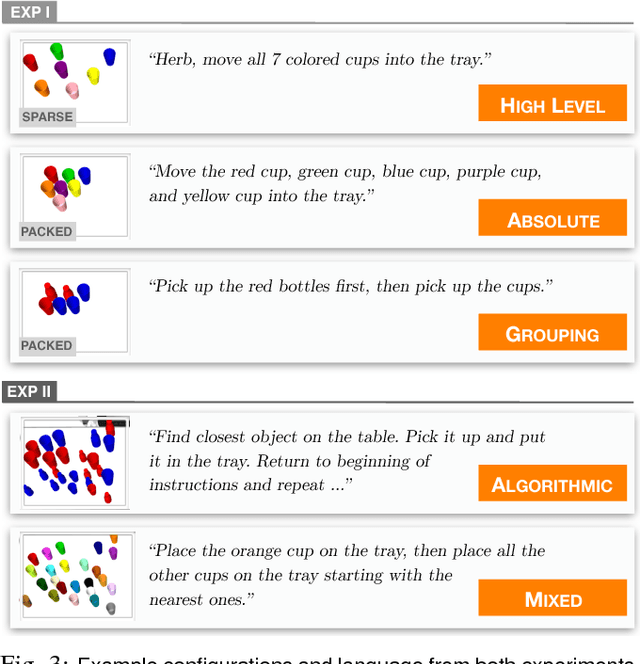
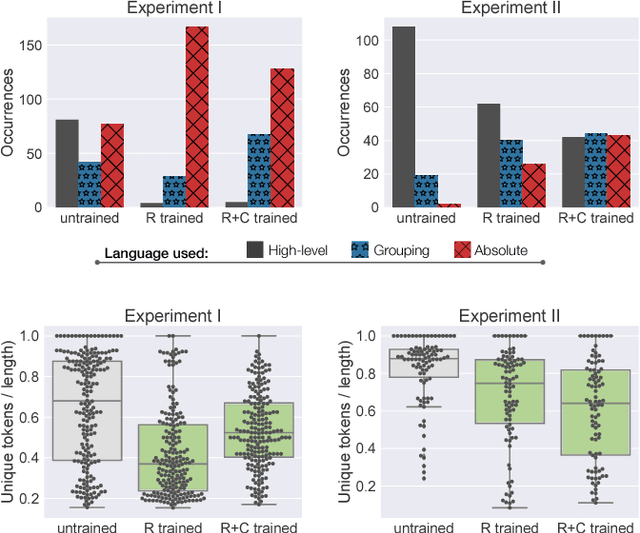
Robotic agents that share autonomy with a human should leverage human domain knowledge and account for their preferences when completing a task. This extra knowledge can dramatically improve plan efficiency and user-satisfaction, but these gains are lost if communicating with a robot is taxing and unnatural. In this paper, we show how viewing humanrobot language through the lens of shared autonomy explains the efficiency versus cognitive load trade-offs humans make when deciding how cooperative and explicit to make their instructions.