 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesk Organization: Effect of Multimodal Inputs on Spatial Relational Learning
Aug 03, 2021
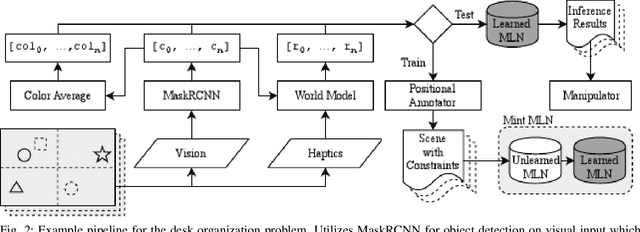
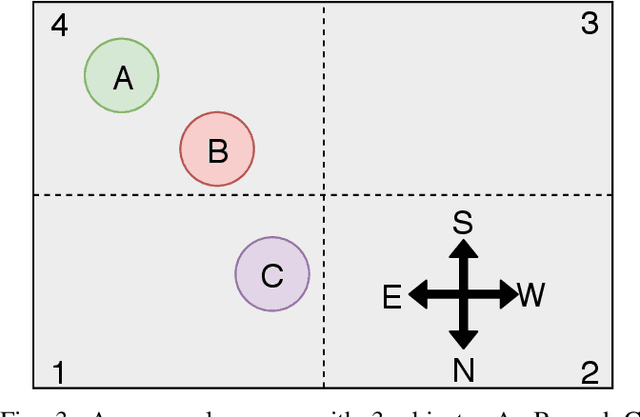

For robots to operate in a three dimensional world and interact with humans, learning spatial relationships among objects in the surrounding is necessary. Reasoning about the state of the world requires inputs from many different sensory modalities including vision ($V$) and haptics ($H$). We examine the problem of desk organization: learning how humans spatially position different objects on a planar surface according to organizational ''preference''. We model this problem by examining how humans position objects given multiple features received from vision and haptic modalities. However, organizational habits vary greatly between people both in structure and adherence. To deal with user organizational preferences, we add an additional modality, ''utility'' ($U$), which informs on a particular human's perceived usefulness of a given object. Models were trained as generalized (over many different people) or tailored (per person). We use two types of models: random forests, which focus on precise multi-task classification, and Markov logic networks, which provide an easily interpretable insight into organizational habits. The models were applied to both synthetic data, which proved to be learnable when using fixed organizational constraints, and human-study data, on which the random forest achieved over 90% accuracy. Over all combinations of $\{H, U, V\}$ modalities, $UV$ and $HUV$ were the most informative for organization. In a follow-up study, we gauged participants preference of desk organizations by a generalized random forest organization vs. by a random model. On average, participants rated the random forest models as 4.15 on a 5-point Likert scale compared to 1.84 for the random model
* 8 pages, 7 figures
Balancing Shared Autonomy with Human-Robot Communication
May 20, 2018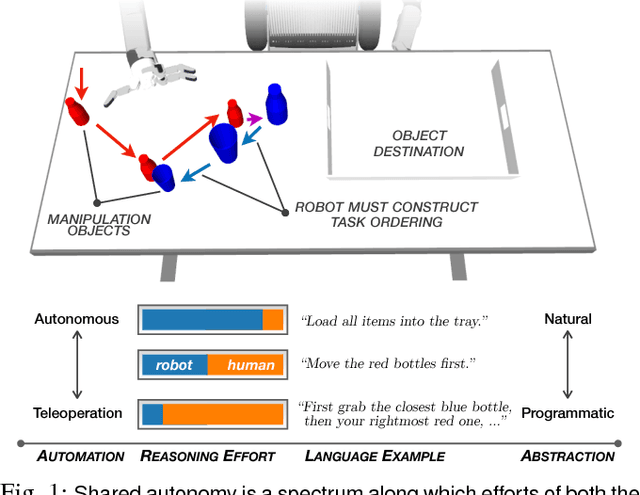
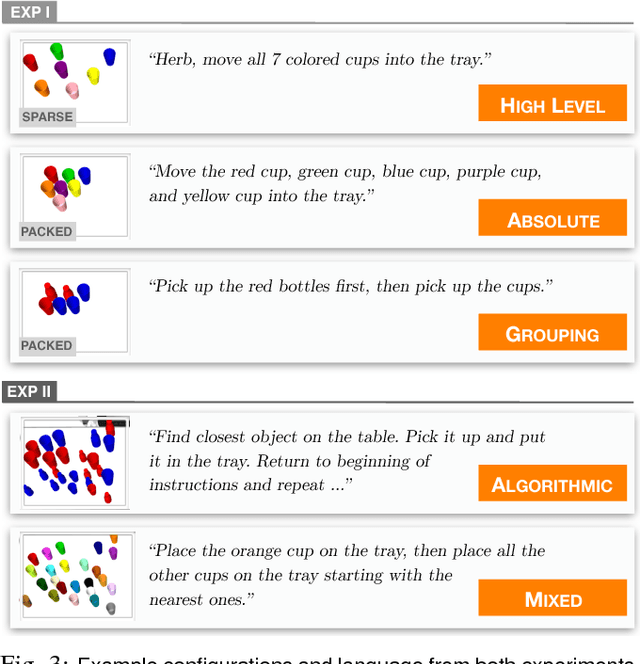
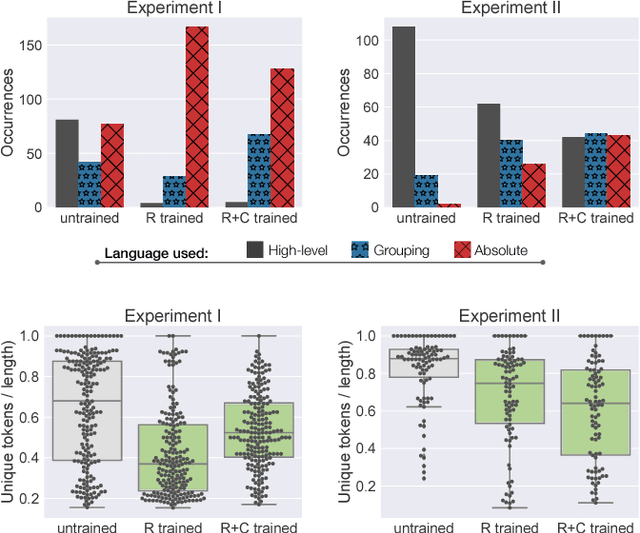
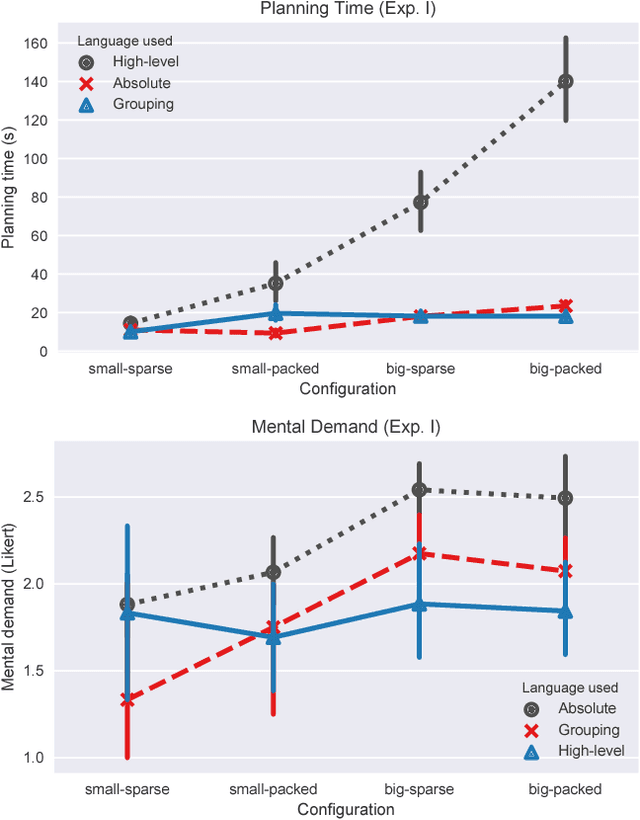
Robotic agents that share autonomy with a human should leverage human domain knowledge and account for their preferences when completing a task. This extra knowledge can dramatically improve plan efficiency and user-satisfaction, but these gains are lost if communicating with a robot is taxing and unnatural. In this paper, we show how viewing humanrobot language through the lens of shared autonomy explains the efficiency versus cognitive load trade-offs humans make when deciding how cooperative and explicit to make their instructions.
Generalizing Informed Sampling for Asymptotically Optimal Sampling-based Kinodynamic Planning via Markov Chain Monte Carlo
Oct 17, 2017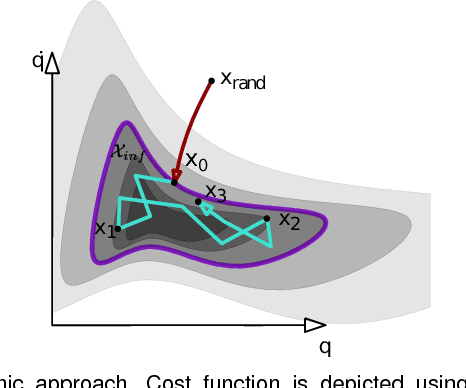
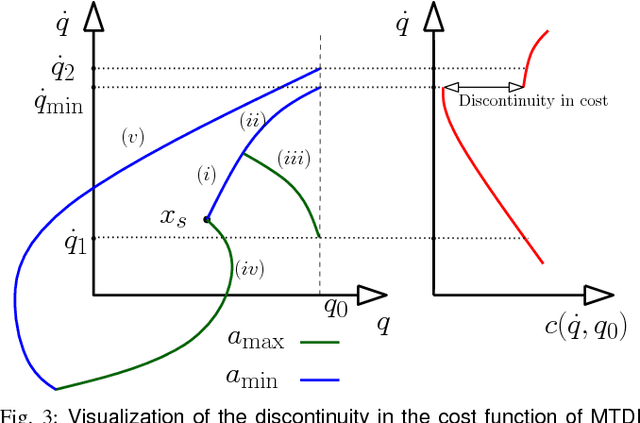
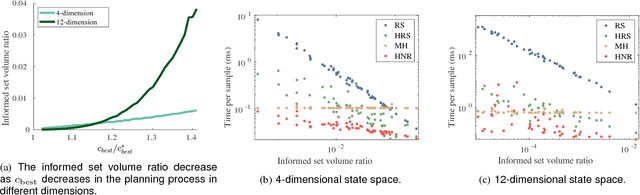
Asymptotically-optimal motion planners such as RRT* have been shown to incrementally approximate the shortest path between start and goal states. Once an initial solution is found, their performance can be dramatically improved by restricting subsequent samples to regions of the state space that can potentially improve the current solution. When the motion planning problem lies in a Euclidean space, this region $X_{inf}$, called the informed set, can be sampled directly. However, when planning with differential constraints in non-Euclidean state spaces, no analytic solutions exists to sampling $X_{inf}$ directly. State-of-the-art approaches to sampling $X_{inf}$ in such domains such as Hierarchical Rejection Sampling (HRS) may still be slow in high-dimensional state space. This may cause the planning algorithm to spend most of its time trying to produces samples in $X_{inf}$ rather than explore it. In this paper, we suggest an alternative approach to produce samples in the informed set $X_{inf}$ for a wide range of settings. Our main insight is to recast this problem as one of sampling uniformly within the sub-level-set of an implicit non-convex function. This recasting enables us to apply Monte Carlo sampling methods, used very effectively in the Machine Learning and Optimization communities, to solve our problem. We show for a wide range of scenarios that using our sampler can accelerate the convergence rate to high-quality solutions in high-dimensional problems.