 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
LLM-ERM: Sample-Efficient Program Learning via LLM-Guided Search
Oct 16, 2025We seek algorithms for program learning that are both sample-efficient and computationally feasible. Classical results show that targets admitting short program descriptions (e.g., with short ``python code'') can be learned with a ``small'' number of examples (scaling with the size of the code) via length-first program enumeration, but the search is exponential in description length. Consequently, Gradient-based training avoids this cost yet can require exponentially many samples on certain short-program families. To address this gap, we introduce LLM-ERM, a propose-and-verify framework that replaces exhaustive enumeration with an LLM-guided search over candidate programs while retaining ERM-style selection on held-out data. Specifically, we draw $k$ candidates with a pretrained reasoning-augmented LLM, compile and check each on the data, and return the best verified hypothesis, with no feedback, adaptivity, or gradients. Theoretically, we show that coordinate-wise online mini-batch SGD requires many samples to learn certain short programs. {\em Empirically, LLM-ERM solves tasks such as parity variants, pattern matching, and primality testing with as few as 200 samples, while SGD-trained transformers overfit even with 100,000 samples}. These results indicate that language-guided program synthesis recovers much of the statistical efficiency of finite-class ERM while remaining computationally tractable, offering a practical route to learning succinct hypotheses beyond the reach of gradient-based training.
Preventing Reward Hacking with Occupancy Measure Regularization
Mar 05, 2024Reward hacking occurs when an agent performs very well with respect to a "proxy" reward function (which may be hand-specified or learned), but poorly with respect to the unknown true reward. Since ensuring good alignment between the proxy and true reward is extremely difficult, one approach to prevent reward hacking is optimizing the proxy conservatively. Prior work has particularly focused on enforcing the learned policy to behave similarly to a "safe" policy by penalizing the KL divergence between their action distributions (AD). However, AD regularization doesn't always work well since a small change in action distribution at a single state can lead to potentially calamitous outcomes, while large changes might not be indicative of any dangerous activity. Our insight is that when reward hacking, the agent visits drastically different states from those reached by the safe policy, causing large deviations in state occupancy measure (OM). Thus, we propose regularizing based on the OM divergence between policies instead of AD divergence to prevent reward hacking. We theoretically establish that OM regularization can more effectively avoid large drops in true reward. Then, we empirically demonstrate in a variety of realistic environments that OM divergence is superior to AD divergence for preventing reward hacking by regularizing towards a safe policy. Furthermore, we show that occupancy measure divergence can also regularize learned policies away from reward hacking behavior. Our code and data are available at https://github.com/cassidylaidlaw/orpo
Desk Organization: Effect of Multimodal Inputs on Spatial Relational Learning
Aug 03, 2021
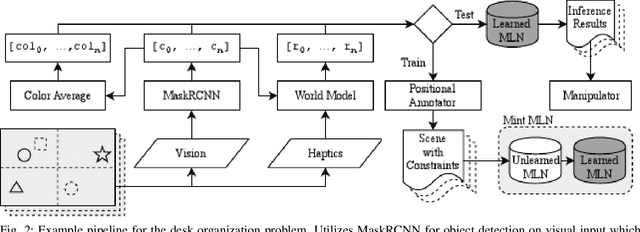
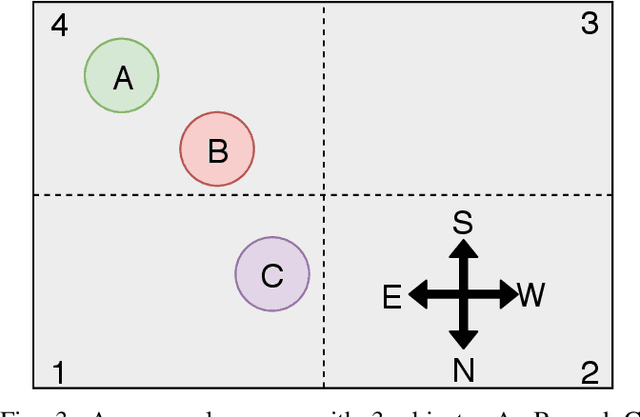

For robots to operate in a three dimensional world and interact with humans, learning spatial relationships among objects in the surrounding is necessary. Reasoning about the state of the world requires inputs from many different sensory modalities including vision ($V$) and haptics ($H$). We examine the problem of desk organization: learning how humans spatially position different objects on a planar surface according to organizational ''preference''. We model this problem by examining how humans position objects given multiple features received from vision and haptic modalities. However, organizational habits vary greatly between people both in structure and adherence. To deal with user organizational preferences, we add an additional modality, ''utility'' ($U$), which informs on a particular human's perceived usefulness of a given object. Models were trained as generalized (over many different people) or tailored (per person). We use two types of models: random forests, which focus on precise multi-task classification, and Markov logic networks, which provide an easily interpretable insight into organizational habits. The models were applied to both synthetic data, which proved to be learnable when using fixed organizational constraints, and human-study data, on which the random forest achieved over 90% accuracy. Over all combinations of $\{H, U, V\}$ modalities, $UV$ and $HUV$ were the most informative for organization. In a follow-up study, we gauged participants preference of desk organizations by a generalized random forest organization vs. by a random model. On average, participants rated the random forest models as 4.15 on a 5-point Likert scale compared to 1.84 for the random model
* 8 pages, 7 figures