 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistanceZero: Scalably Solving Assistance Games
Apr 09, 2025Assistance games are a promising alternative to reinforcement learning from human feedback (RLHF) for training AI assistants. Assistance games resolve key drawbacks of RLHF, such as incentives for deceptive behavior, by explicitly modeling the interaction between assistant and user as a two-player game where the assistant cannot observe their shared goal. Despite their potential, assistance games have only been explored in simple settings. Scaling them to more complex environments is difficult because it requires both solving intractable decision-making problems under uncertainty and accurately modeling human users' behavior. We present the first scalable approach to solving assistance games and apply it to a new, challenging Minecraft-based assistance game with over $10^{400}$ possible goals. Our approach, AssistanceZero, extends AlphaZero with a neural network that predicts human actions and rewards, enabling it to plan under uncertainty. We show that AssistanceZero outperforms model-free RL algorithms and imitation learning in the Minecraft-based assistance game. In a human study, our AssistanceZero-trained assistant significantly reduces the number of actions participants take to complete building tasks in Minecraft. Our results suggest that assistance games are a tractable framework for training effective AI assistants in complex environments. Our code and models are available at https://github.com/cassidylaidlaw/minecraft-building-assistance-game.
Iterative Label Refinement Matters More than Preference Optimization under Weak Supervision
Jan 14, 2025Language model (LM) post-training relies on two stages of human supervision: task demonstrations for supervised finetuning (SFT), followed by preference comparisons for reinforcement learning from human feedback (RLHF). As LMs become more capable, the tasks they are given become harder to supervise. Will post-training remain effective under unreliable supervision? To test this, we simulate unreliable demonstrations and comparison feedback using small LMs and time-constrained humans. We find that in the presence of unreliable supervision, SFT still retains some effectiveness, but DPO (a common RLHF algorithm) fails to improve the model beyond SFT. To address this, we propose iterative label refinement (ILR) as an alternative to RLHF. ILR improves the SFT data by using comparison feedback to decide whether human demonstrations should be replaced by model-generated alternatives, then retrains the model via SFT on the updated data. SFT+ILR outperforms SFT+DPO on several tasks with unreliable supervision (math, coding, and safe instruction-following). Our findings suggest that as LMs are used for complex tasks where human supervision is unreliable, RLHF may no longer be the best use of human comparison feedback; instead, it is better to direct feedback towards improving the training data rather than continually training the model. Our code and data are available at https://github.com/helloelwin/iterative-label-refinement.
Preventing Reward Hacking with Occupancy Measure Regularization
Mar 05, 2024Reward hacking occurs when an agent performs very well with respect to a "proxy" reward function (which may be hand-specified or learned), but poorly with respect to the unknown true reward. Since ensuring good alignment between the proxy and true reward is extremely difficult, one approach to prevent reward hacking is optimizing the proxy conservatively. Prior work has particularly focused on enforcing the learned policy to behave similarly to a "safe" policy by penalizing the KL divergence between their action distributions (AD). However, AD regularization doesn't always work well since a small change in action distribution at a single state can lead to potentially calamitous outcomes, while large changes might not be indicative of any dangerous activity. Our insight is that when reward hacking, the agent visits drastically different states from those reached by the safe policy, causing large deviations in state occupancy measure (OM). Thus, we propose regularizing based on the OM divergence between policies instead of AD divergence to prevent reward hacking. We theoretically establish that OM regularization can more effectively avoid large drops in true reward. Then, we empirically demonstrate in a variety of realistic environments that OM divergence is superior to AD divergence for preventing reward hacking by regularizing towards a safe policy. Furthermore, we show that occupancy measure divergence can also regularize learned policies away from reward hacking behavior. Our code and data are available at https://github.com/cassidylaidlaw/orpo
Toward Computationally Efficient Inverse Reinforcement Learning via Reward Shaping
Dec 18, 2023Inverse reinforcement learning (IRL) is computationally challenging, with common approaches requiring the solution of multiple reinforcement learning (RL) sub-problems. This work motivates the use of potential-based reward shaping to reduce the computational burden of each RL sub-problem. This work serves as a proof-of-concept and we hope will inspire future developments towards computationally efficient IRL.
Distributional Preference Learning: Understanding and Accounting for Hidden Context in RLHF
Dec 13, 2023In practice, preference learning from human feedback depends on incomplete data with hidden context. Hidden context refers to data that affects the feedback received, but which is not represented in the data used to train a preference model. This captures common issues of data collection, such as having human annotators with varied preferences, cognitive processes that result in seemingly irrational behavior, and combining data labeled according to different criteria. We prove that standard applications of preference learning, including reinforcement learning from human feedback (RLHF), implicitly aggregate over hidden contexts according to a well-known voting rule called Borda count. We show this can produce counter-intuitive results that are very different from other methods which implicitly aggregate via expected utility. Furthermore, our analysis formalizes the way that preference learning from users with diverse values tacitly implements a social choice function. A key implication of this result is that annotators have an incentive to misreport their preferences in order to influence the learned model, leading to vulnerabilities in the deployment of RLHF. As a step towards mitigating these problems, we introduce a class of methods called distributional preference learning (DPL). DPL methods estimate a distribution of possible score values for each alternative in order to better account for hidden context. Experimental results indicate that applying DPL to RLHF for LLM chatbots identifies hidden context in the data and significantly reduces subsequent jailbreak vulnerability. Our code and data are available at https://github.com/cassidylaidlaw/hidden-context
The Effective Horizon Explains Deep RL Performance in Stochastic Environments
Dec 13, 2023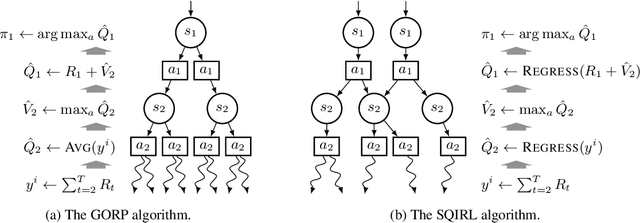

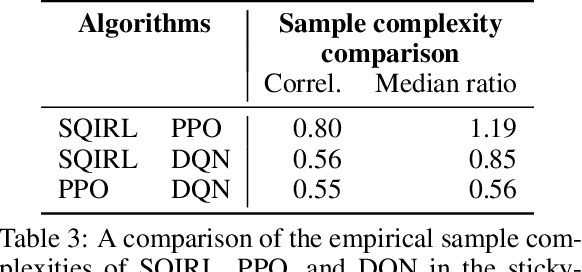
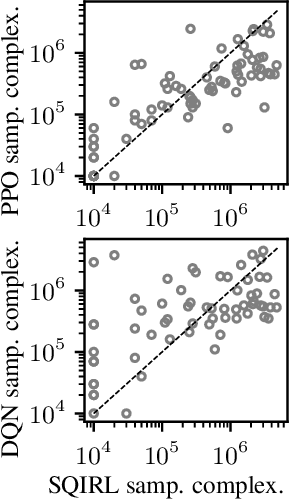
Reinforcement learning (RL) theory has largely focused on proving minimax sample complexity bounds. These require strategic exploration algorithms that use relatively limited function classes for representing the policy or value function. Our goal is to explain why deep RL algorithms often perform well in practice, despite using random exploration and much more expressive function classes like neural networks. Our work arrives at an explanation by showing that many stochastic MDPs can be solved by performing only a few steps of value iteration on the random policy's Q function and then acting greedily. When this is true, we find that it is possible to separate the exploration and learning components of RL, making it much easier to analyze. We introduce a new RL algorithm, SQIRL, that iteratively learns a near-optimal policy by exploring randomly to collect rollouts and then performing a limited number of steps of fitted-Q iteration over those rollouts. Any regression algorithm that satisfies basic in-distribution generalization properties can be used in SQIRL to efficiently solve common MDPs. This can explain why deep RL works neural networks, since it is empirically established that neural networks generalize well in-distribution. Furthermore, SQIRL explains why random exploration works well in practice, since we show many environments can be solved by estimating the random policy's Q-function and then applying zero or a few steps of value iteration. We leverage SQIRL to derive instance-dependent sample complexity bounds for RL that are exponential only in an "effective horizon" of lookahead and on the complexity of the class used for function approximation. Empirically, we also find that SQIRL performance strongly correlates with PPO and DQN performance in a variety of stochastic environments, supporting that our theoretical analysis is predictive of practical performance.
Bridging RL Theory and Practice with the Effective Horizon
Apr 19, 2023Deep reinforcement learning (RL) works impressively in some environments and fails catastrophically in others. Ideally, RL theory should be able to provide an understanding of why this is, i.e. bounds predictive of practical performance. Unfortunately, current theory does not quite have this ability. We compare standard deep RL algorithms to prior sample complexity prior bounds by introducing a new dataset, BRIDGE. It consists of 155 MDPs from common deep RL benchmarks, along with their corresponding tabular representations, which enables us to exactly compute instance-dependent bounds. We find that prior bounds do not correlate well with when deep RL succeeds vs. fails, but discover a surprising property that does. When actions with the highest Q-values under the random policy also have the highest Q-values under the optimal policy, deep RL tends to succeed; when they don't, deep RL tends to fail. We generalize this property into a new complexity measure of an MDP that we call the effective horizon, which roughly corresponds to how many steps of lookahead search are needed in order to identify the next optimal action when leaf nodes are evaluated with random rollouts. Using BRIDGE, we show that the effective horizon-based bounds are more closely reflective of the empirical performance of PPO and DQN than prior sample complexity bounds across four metrics. We also show that, unlike existing bounds, the effective horizon can predict the effects of using reward shaping or a pre-trained exploration policy.
The Boltzmann Policy Distribution: Accounting for Systematic Suboptimality in Human Models
Apr 22, 2022
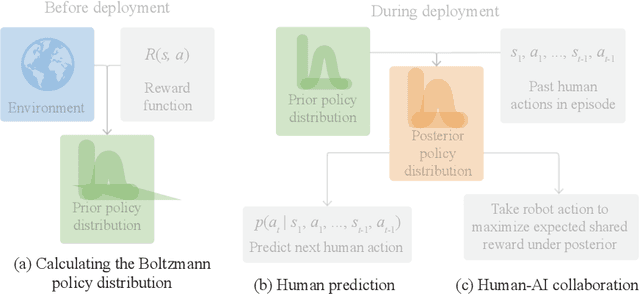

Models of human behavior for prediction and collaboration tend to fall into two categories: ones that learn from large amounts of data via imitation learning, and ones that assume human behavior to be noisily-optimal for some reward function. The former are very useful, but only when it is possible to gather a lot of human data in the target environment and distribution. The advantage of the latter type, which includes Boltzmann rationality, is the ability to make accurate predictions in new environments without extensive data when humans are actually close to optimal. However, these models fail when humans exhibit systematic suboptimality, i.e. when their deviations from optimal behavior are not independent, but instead consistent over time. Our key insight is that systematic suboptimality can be modeled by predicting policies, which couple action choices over time, instead of trajectories. We introduce the Boltzmann policy distribution (BPD), which serves as a prior over human policies and adapts via Bayesian inference to capture systematic deviations by observing human actions during a single episode. The BPD is difficult to compute and represent because policies lie in a high-dimensional continuous space, but we leverage tools from generative and sequence models to enable efficient sampling and inference. We show that the BPD enables prediction of human behavior and human-AI collaboration equally as well as imitation learning-based human models while using far less data.
Learning the Preferences of Uncertain Humans with Inverse Decision Theory
Jun 19, 2021
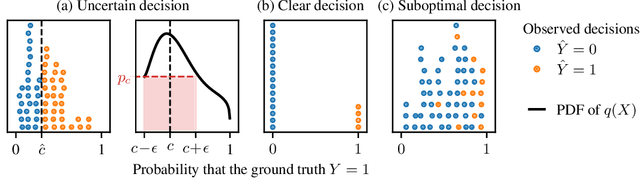
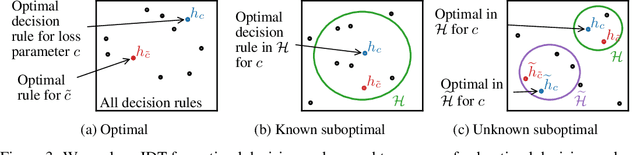
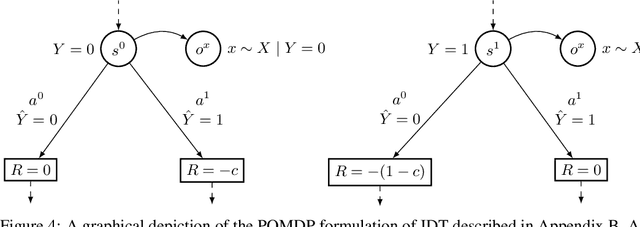
Existing observational approaches for learning human preferences, such as inverse reinforcement learning, usually make strong assumptions about the observability of the human's environment. However, in reality, people make many important decisions under uncertainty. To better understand preference learning in these cases, we study the setting of inverse decision theory (IDT), a previously proposed framework where a human is observed making non-sequential binary decisions under uncertainty. In IDT, the human's preferences are conveyed through their loss function, which expresses a tradeoff between different types of mistakes. We give the first statistical analysis of IDT, providing conditions necessary to identify these preferences and characterizing the sample complexity -- the number of decisions that must be observed to learn the tradeoff the human is making to a desired precision. Interestingly, we show that it is actually easier to identify preferences when the decision problem is more uncertain. Furthermore, uncertain decision problems allow us to relax the unrealistic assumption that the human is an optimal decision maker but still identify their exact preferences; we give sample complexities in this suboptimal case as well. Our analysis contradicts the intuition that partial observability should make preference learning more difficult. It also provides a first step towards understanding and improving preference learning methods for uncertain and suboptimal humans.
Perceptual Adversarial Robustness: Defense Against Unseen Threat Models
Jun 22, 2020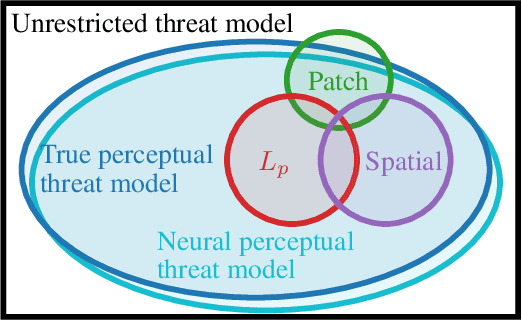


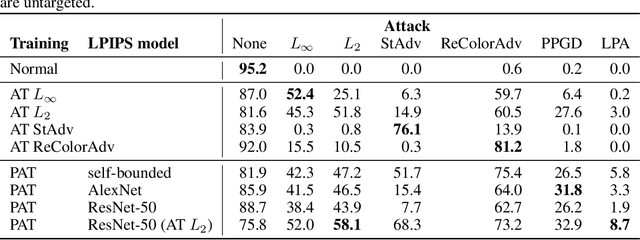
We present adversarial attacks and defenses for the perceptual adversarial threat model: the set of all perturbations to natural images which can mislead a classifier but are imperceptible to human eyes. The perceptual threat model is broad and encompasses $L_2$, $L_\infty$, spatial, and many other existing adversarial threat models. However, it is difficult to determine if an arbitrary perturbation is imperceptible without humans in the loop. To solve this issue, we propose to use a {\it neural perceptual distance}, an approximation of the true perceptual distance between images using internal activations of neural networks. In particular, we use the Learned Perceptual Image Patch Similarity (LPIPS) distance. We then propose the {\it neural perceptual threat model} that includes adversarial examples with a bounded neural perceptual distance to natural images. Under the neural perceptual threat model, we develop two novel perceptual adversarial attacks to find any imperceptible perturbations to images which can fool a classifier. Through an extensive perceptual study, we show that the LPIPS distance correlates well with human judgements of perceptibility of adversarial examples, validating our threat model. Because the LPIPS threat model is very broad, we find that Perceptual Adversarial Training (PAT) against a perceptual attack gives robustness against many other types of adversarial attacks. We test PAT on CIFAR-10 and ImageNet-100 against 12 types of adversarial attacks and find that, for each attack, PAT achieves close to the accuracy of adversarial training against just that perturbation type. That is, PAT generalizes well to unforeseen perturbation types. This is vital in sensitive applications where a particular threat model cannot be assumed, and to the best of our knowledge, PAT is the first adversarial defense with this property.