 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robot Success Detection using Static Object Data
Paper and Code

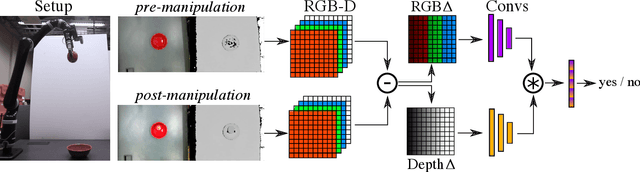
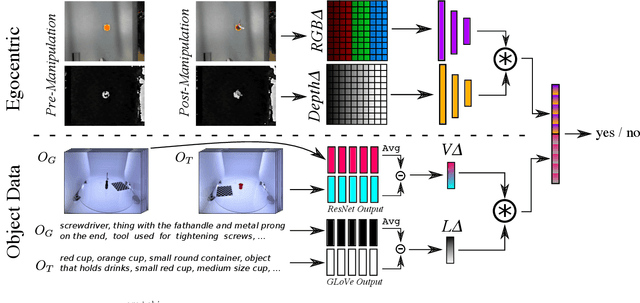
We use static object data to improve success detection for stacking objects on and nesting objects in one another. Such actions are necessary for certain robotics tasks, e.g., clearing a dining table or packing a warehouse bin. However, using an RGB-D camera to detect success can be insufficient: same-colored objects can be difficult to differentiate, and reflective silverware cause noisy depth camera perception. We show that adding static data about the objects themselves improves the performance of an end-to-end pipeline for classifying action outcomes. Images of the objects, and language expressions describing them, encode prior geometry, shape, and size information that refine classification accuracy. We collect over 13 hours of egocentric manipulation data for training a model to reason about whether a robot successfully placed unseen objects in or on one another. The model achieves up to a 57% absolute gain over the task baseline on pairs of previously unseen objects.