 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end LSTM-based dialog control optimized with supervised and reinforcement learning
Paper and Code
Jun 03, 2016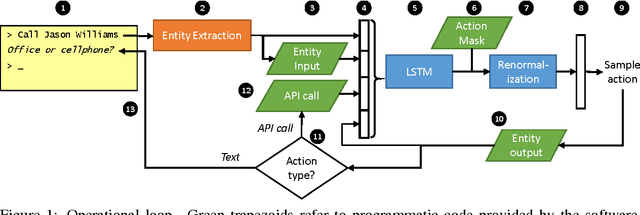
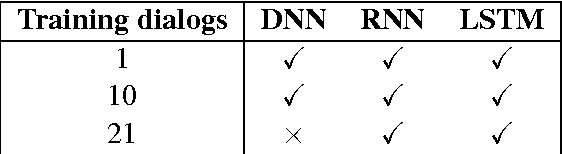

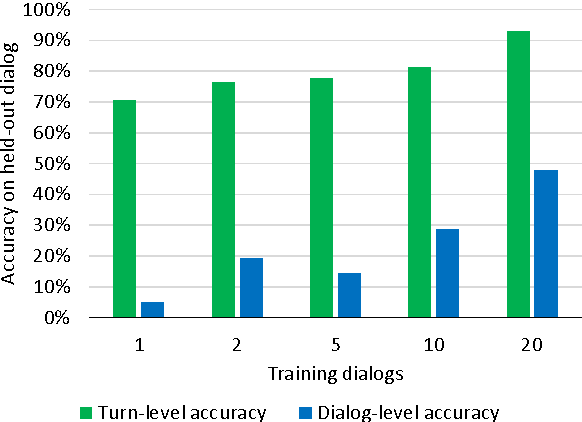
This paper presents a model for end-to-end learning of task-oriented dialog systems. The main component of the model is a recurrent neural network (an LSTM), which maps from raw dialog history directly to a distribution over system actions. The LSTM automatically infers a representation of dialog history, which relieves the system developer of much of the manual feature engineering of dialog state. In addition, the developer can provide software that expresses business rules and provides access to programmatic APIs, enabling the LSTM to take actions in the real world on behalf of the user. The LSTM can be optimized using supervised learning (SL), where a domain expert provides example dialogs which the LSTM should imitate; or using reinforcement learning (RL), where the system improves by interacting directly with end users. Experiments show that SL and RL are complementary: SL alone can derive a reasonable initial policy from a small number of training dialogs; and starting RL optimization with a policy trained with SL substantially accelerates the learning rate of RL.