Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-efficient Deep Reinforcement Learning for Dialog Control
Paper and Code
Dec 18, 2016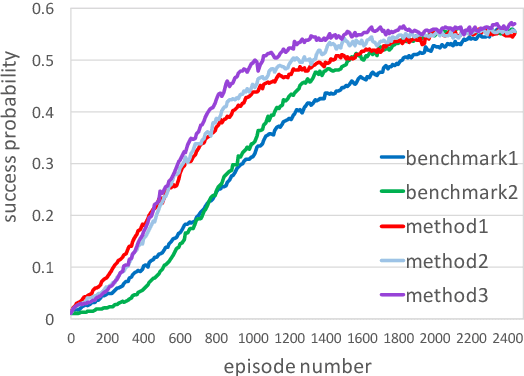
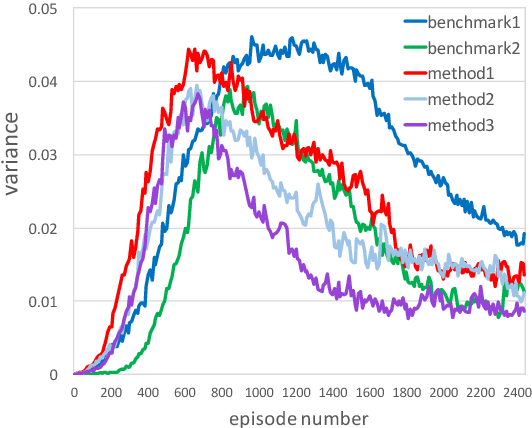
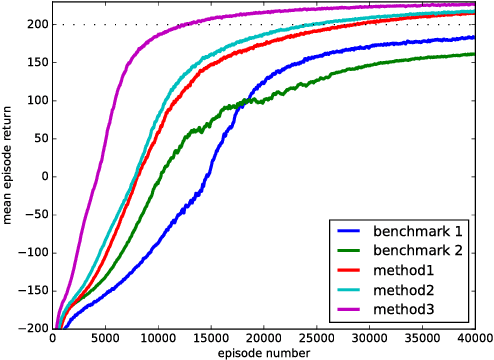
Representing a dialog policy as a recurrent neural network (RNN) is attractive because it handles partial observability, infers a latent representation of state, and can be optimized with supervised learning (SL) or reinforcement learning (RL). For RL, a policy gradient approach is natural, but is sample inefficient. In this paper, we present 3 methods for reducing the number of dialogs required to optimize an RNN-based dialog policy with RL. The key idea is to maintain a second RNN which predicts the value of the current policy, and to apply experience replay to both networks. On two tasks, these methods reduce the number of dialogs/episodes required by about a third, vs. standard policy gradient methods.
View paper on