 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtected group bias and stereotypes in Large Language Models
Mar 21, 2024



As modern Large Language Models (LLMs) shatter many state-of-the-art benchmarks in a variety of domains, this paper investigates their behavior in the domains of ethics and fairness, focusing on protected group bias. We conduct a two-part study: first, we solicit sentence continuations describing the occupations of individuals from different protected groups, including gender, sexuality, religion, and race. Second, we have the model generate stories about individuals who hold different types of occupations. We collect >10k sentence completions made by a publicly available LLM, which we subject to human annotation. We find bias across minoritized groups, but in particular in the domains of gender and sexuality, as well as Western bias, in model generations. The model not only reflects societal biases, but appears to amplify them. The model is additionally overly cautious in replies to queries relating to minoritized groups, providing responses that strongly emphasize diversity and equity to an extent that other group characteristics are overshadowed. This suggests that artificially constraining potentially harmful outputs may itself lead to harm, and should be applied in a careful and controlled manner.
DELPHI: Data for Evaluating LLMs' Performance in Handling Controversial Issues
Nov 07, 2023



Controversy is a reflection of our zeitgeist, and an important aspect to any discourse. The rise of large language models (LLMs) as conversational systems has increased public reliance on these systems for answers to their various questions. Consequently, it is crucial to systematically examine how these models respond to questions that pertaining to ongoing debates. However, few such datasets exist in providing human-annotated labels reflecting the contemporary discussions. To foster research in this area, we propose a novel construction of a controversial questions dataset, expanding upon the publicly released Quora Question Pairs Dataset. This dataset presents challenges concerning knowledge recency, safety, fairness, and bias. We evaluate different LLMs using a subset of this dataset, illuminating how they handle controversial issues and the stances they adopt. This research ultimately contributes to our understanding of LLMs' interaction with controversial issues, paving the way for improvements in their comprehension and handling of complex societal debates.
Feedback Effect in User Interaction with Intelligent Assistants: Delayed Engagement, Adaption and Drop-out
Mar 17, 2023With the growing popularity of intelligent assistants (IAs), evaluating IA quality becomes an increasingly active field of research. This paper identifies and quantifies the feedback effect, a novel component in IA-user interactions: how the capabilities and limitations of the IA influence user behavior over time. First, we demonstrate that unhelpful responses from the IA cause users to delay or reduce subsequent interactions in the short term via an observational study. Next, we expand the time horizon to examine behavior changes and show that as users discover the limitations of the IA's understanding and functional capabilities, they learn to adjust the scope and wording of their requests to increase the likelihood of receiving a helpful response from the IA. Our findings highlight the impact of the feedback effect at both the micro and meso levels. We further discuss its macro-level consequences: unsatisfactory interactions continuously reduce the likelihood and diversity of future user engagements in a feedback loop.
Variational Inference with Holder Bounds
Nov 13, 2021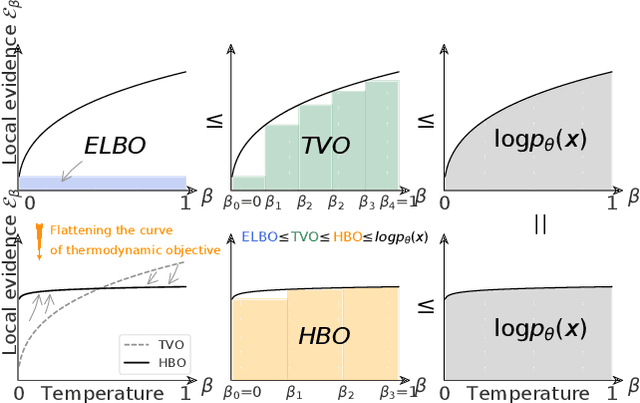
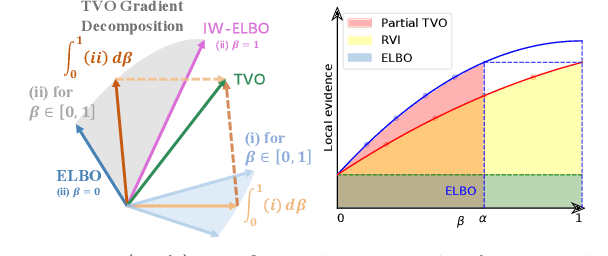
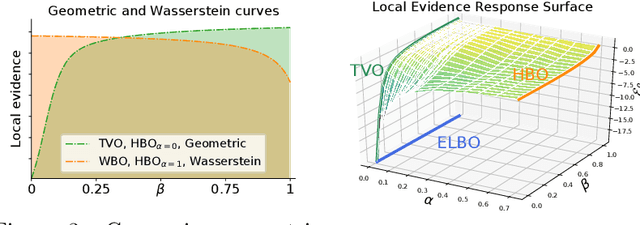
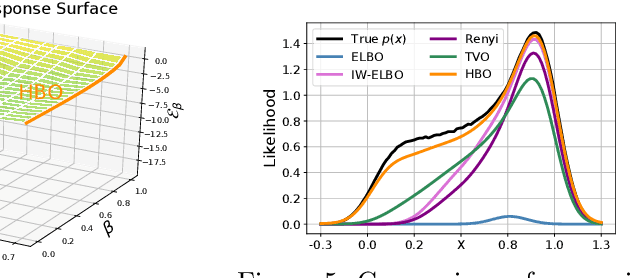
The recent introduction of thermodynamic integration techniques has provided a new framework for understanding and improving variational inference (VI). In this work, we present a careful analysis of the thermodynamic variational objective (TVO), bridging the gap between existing variational objectives and shedding new insights to advance the field. In particular, we elucidate how the TVO naturally connects the three key variational schemes, namely the importance-weighted VI, Renyi-VI, and MCMC-VI, which subsumes most VI objectives employed in practice. To explain the performance gap between theory and practice, we reveal how the pathological geometry of thermodynamic curves negatively affects TVO. By generalizing the integration path from the geometric mean to the weighted Holder mean, we extend the theory of TVO and identify new opportunities for improving VI. This motivates our new VI objectives, named the Holder bounds, which flatten the thermodynamic curves and promise to achieve a one-step approximation of the exact marginal log-likelihood. A comprehensive discussion on the choices of numerical estimators is provided. We present strong empirical evidence on both synthetic and real-world datasets to support our claims.
Supercharging Imbalanced Data Learning With Causal Representation Transfer
Nov 25, 2020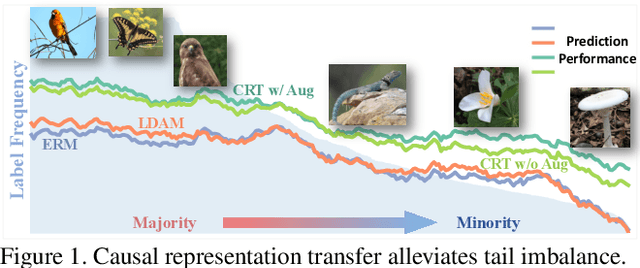
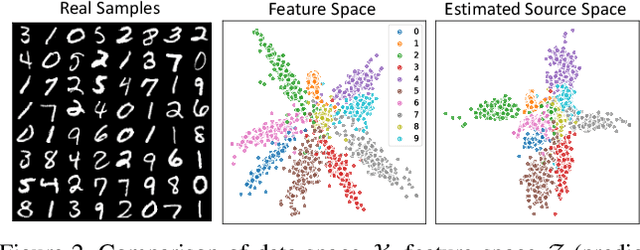
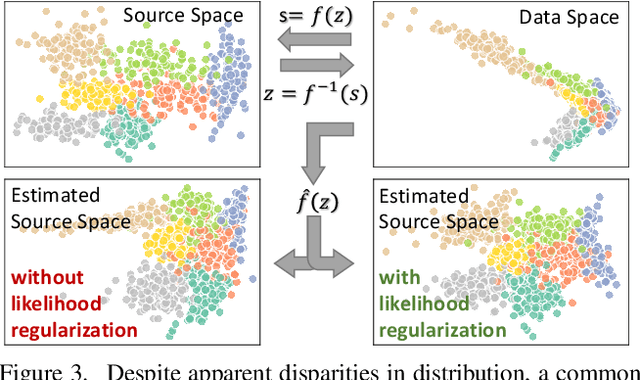
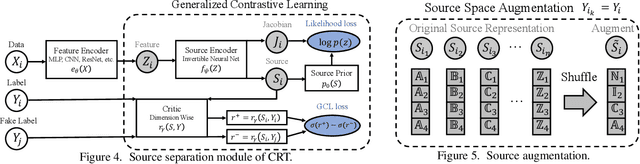
Dealing with severe class imbalance poses a major challenge for real-world applications, especially when the accurate classification and generalization of minority classes is of primary interest. In computer vision, learning from long tailed datasets is a recurring theme, especially for natural image datasets. While existing solutions mostly appeal to sampling or weighting adjustments to alleviate the pathological imbalance, or imposing inductive bias to prioritize non-spurious associations, we take novel perspectives to promote sample efficiency and model generalization based on the invariance principles of causality. Our proposal posits a meta-distributional scenario, where the data generating mechanism is invariant across the label-conditional feature distributions. Such causal assumption enables efficient knowledge transfer from the dominant classes to their under-represented counterparts, even if the respective feature distributions show apparent disparities. This allows us to leverage a causal data inflation procedure to enlarge the representation of minority classes. Our development is orthogonal to the existing extreme classification techniques thus can be seamlessly integrated. The utility of our proposal is validated with an extensive set of synthetic and real-world computer vision tasks against SOTA solutions.
Variational Disentanglement for Rare Event Modeling
Sep 21, 2020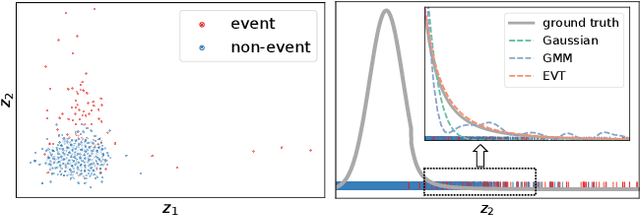


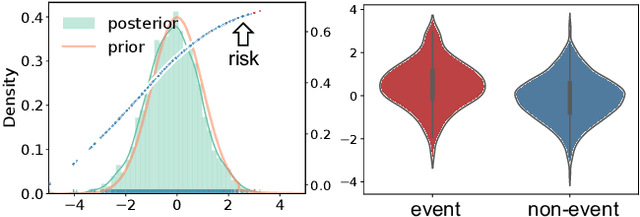
Combining the increasing availability and abundance of healthcare data and the current advances in machine learning methods have created renewed opportunities to improve clinical decision support systems. However, in healthcare risk prediction applications, the proportion of cases with the condition (label) of interest is often very low relative to the available sample size. Though very prevalent in healthcare, such imbalanced classification settings are also common and challenging in many other scenarios. So motivated, we propose a variational disentanglement approach to semi-parametrically learn from rare events in heavily imbalanced classification problems. Specifically, we leverage the imposed extreme-distribution behavior on a latent space to extract information from low-prevalence events, and develop a robust prediction arm that joins the merits of the generalized additive model and isotonic neural nets. Results on synthetic studies and diverse real-world datasets, including mortality prediction on a COVID-19 cohort, demonstrate that the proposed approach outperforms existing alternatives.
Variational Learning of Individual Survival Distributions
Mar 09, 2020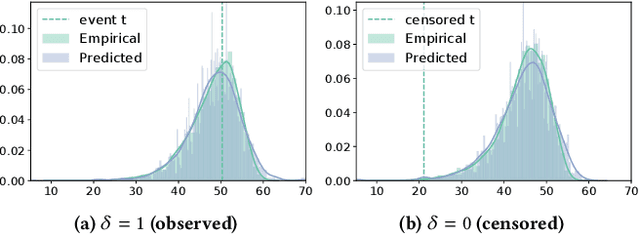
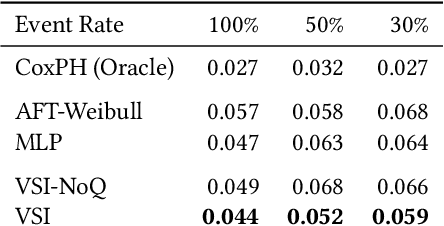
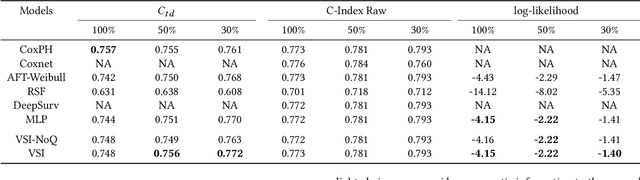
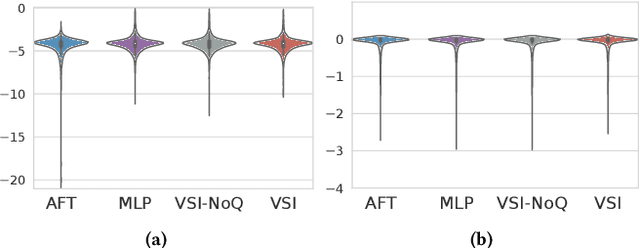
The abundance of modern health data provides many opportunities for the use of machine learning techniques to build better statistical models to improve clinical decision making. Predicting time-to-event distributions, also known as survival analysis, plays a key role in many clinical applications. We introduce a variational time-to-event prediction model, named Variational Survival Inference (VSI), which builds upon recent advances in distribution learning techniques and deep neural networks. VSI addresses the challenges of non-parametric distribution estimation by ($i$) relaxing the restrictive modeling assumptions made in classical models, and ($ii$) efficiently handling the censored observations, {\it i.e.}, events that occur outside the observation window, all within the variational framework. To validate the effectiveness of our approach, an extensive set of experiments on both synthetic and real-world datasets is carried out, showing improved performance relative to competing solutions.