 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEST: Nested Event Stream Transformer for Sequences of Multisets
Feb 03, 2026Event stream data often exhibit hierarchical structure in which multiple events co-occur, resulting in a sequence of multisets (i.e., bags of events). In electronic health records (EHRs), for example, medical events are grouped into a sequence of clinical encounters with well-defined temporal structure, but the order and timing of events within each encounter may be unknown or unreliable. Most existing foundation models (FMs) for event stream data flatten this hierarchy into a one-dimensional sequence, leading to (i) computational inefficiency associated with dense attention and learning spurious within-set relationships, and (ii) lower-quality set-level representations from heuristic post-training pooling for downstream tasks. Here, we show that preserving the original hierarchy in the FM architecture provides a useful inductive bias that improves both computational efficiency and representation quality. We then introduce Nested Event Stream Transformer (NEST), a FM for event streams comprised of sequences of multisets. Building on this architecture, we formulate Masked Set Modeling (MSM), an efficient paradigm that promotes improved set-level representation learning. Experiments on real-world multiset sequence data show that NEST captures real-world dynamics while improving both pretraining efficiency and downstream performance.
Supercharging Imbalanced Data Learning With Causal Representation Transfer
Nov 25, 2020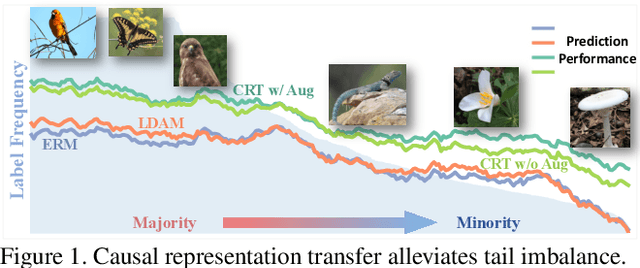
Dealing with severe class imbalance poses a major challenge for real-world applications, especially when the accurate classification and generalization of minority classes is of primary interest. In computer vision, learning from long tailed datasets is a recurring theme, especially for natural image datasets. While existing solutions mostly appeal to sampling or weighting adjustments to alleviate the pathological imbalance, or imposing inductive bias to prioritize non-spurious associations, we take novel perspectives to promote sample efficiency and model generalization based on the invariance principles of causality. Our proposal posits a meta-distributional scenario, where the data generating mechanism is invariant across the label-conditional feature distributions. Such causal assumption enables efficient knowledge transfer from the dominant classes to their under-represented counterparts, even if the respective feature distributions show apparent disparities. This allows us to leverage a causal data inflation procedure to enlarge the representation of minority classes. Our development is orthogonal to the existing extreme classification techniques thus can be seamlessly integrated. The utility of our proposal is validated with an extensive set of synthetic and real-world computer vision tasks against SOTA solutions.
Variational Disentanglement for Rare Event Modeling
Sep 21, 2020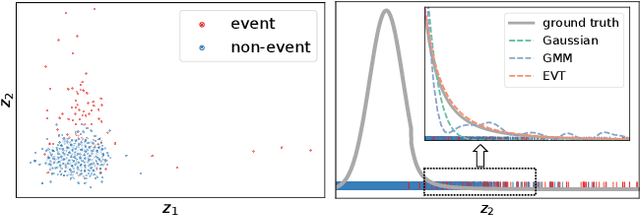


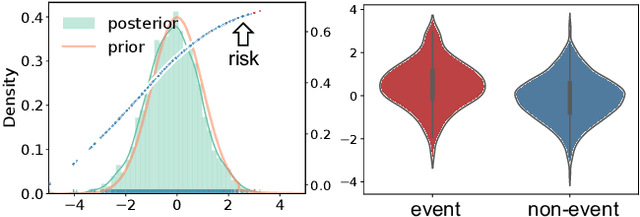
Combining the increasing availability and abundance of healthcare data and the current advances in machine learning methods have created renewed opportunities to improve clinical decision support systems. However, in healthcare risk prediction applications, the proportion of cases with the condition (label) of interest is often very low relative to the available sample size. Though very prevalent in healthcare, such imbalanced classification settings are also common and challenging in many other scenarios. So motivated, we propose a variational disentanglement approach to semi-parametrically learn from rare events in heavily imbalanced classification problems. Specifically, we leverage the imposed extreme-distribution behavior on a latent space to extract information from low-prevalence events, and develop a robust prediction arm that joins the merits of the generalized additive model and isotonic neural nets. Results on synthetic studies and diverse real-world datasets, including mortality prediction on a COVID-19 cohort, demonstrate that the proposed approach outperforms existing alternatives.
Adversarial Time-to-Event Modeling
Jun 07, 2018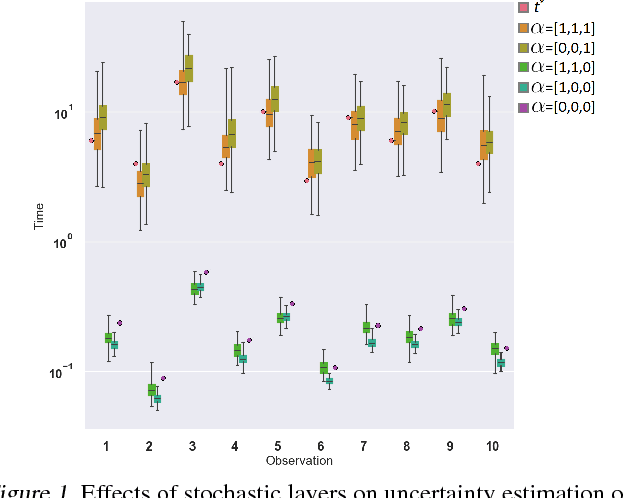
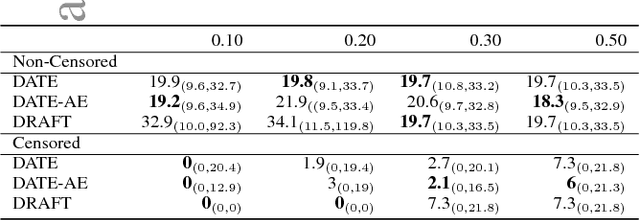

Modern health data science applications leverage abundant molecular and electronic health data, providing opportunities for machine learning to build statistical models to support clinical practice. Time-to-event analysis, also called survival analysis, stands as one of the most representative examples of such statistical models. We present a deep-network-based approach that leverages adversarial learning to address a key challenge in modern time-to-event modeling: nonparametric estimation of event-time distributions. We also introduce a principled cost function to exploit information from censored events (events that occur subsequent to the observation window). Unlike most time-to-event models, we focus on the estimation of time-to-event distributions, rather than time ordering. We validate our model on both benchmark and real datasets, demonstrating that the proposed formulation yields significant performance gains relative to a parametric alternative, which we also propose.