 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Hybrid Models in Health Misinformation Text Classification
Oct 08, 2024This study evaluates the effectiveness of machine learning (ML) and deep learning (DL) models in detecting COVID-19-related misinformation on online social networks (OSNs), aiming to develop more effective tools for countering the spread of health misinformation during the pan-demic. The study trained and tested various ML classifiers (Naive Bayes, SVM, Random Forest, etc.), DL models (CNN, LSTM, hybrid CNN+LSTM), and pretrained language models (DistilBERT, RoBERTa) on the "COVID19-FNIR DATASET". These models were evaluated for accuracy, F1 score, recall, precision, and ROC, and used preprocessing techniques like stemming and lemmatization. The results showed SVM performed well, achieving a 94.41% F1-score. DL models with Word2Vec embeddings exceeded 98% in all performance metrics (accuracy, F1 score, recall, precision & ROC). The CNN+LSTM hybrid models also exceeded 98% across performance metrics, outperforming pretrained models like DistilBERT and RoBERTa. Our study concludes that DL and hybrid DL models are more effective than conventional ML algorithms for detecting COVID-19 misinformation on OSNs. The findings highlight the importance of advanced neural network approaches and large-scale pretraining in misinformation detection. Future research should optimize these models for various misinformation types and adapt to changing OSNs, aiding in combating health misinformation.
* 8 pages, 4 tables presented at the OASIS workshop of the ACM Hypertext and Social Media Conference 2024
A Systematic Review of Generative AI for Teaching and Learning Practice
Jun 13, 2024



The use of generative artificial intelligence (GenAI) in academia is a subjective and hotly debated topic. Currently, there are no agreed guidelines towards the usage of GenAI systems in higher education (HE) and, thus, it is still unclear how to make effective use of the technology for teaching and learning practice. This paper provides an overview of the current state of research on GenAI for teaching and learning in HE. To this end, this study conducted a systematic review of relevant studies indexed by Scopus, using the preferred reporting items for systematic reviews and meta-analyses (PRISMA) guidelines. The search criteria revealed a total of 625 research papers, of which 355 met the final inclusion criteria. The findings from the review showed the current state and the future trends in documents, citations, document sources/authors, keywords, and co-authorship. The research gaps identified suggest that while some authors have looked at understanding the detection of AI-generated text, it may be beneficial to understand how GenAI can be incorporated into supporting the educational curriculum for assessments, teaching, and learning delivery. Furthermore, there is a need for additional interdisciplinary, multidimensional studies in HE through collaboration. This will strengthen the awareness and understanding of students, tutors, and other stakeholders, which will be instrumental in formulating guidelines, frameworks, and policies for GenAI usage.
* 20 pages, 10 figures, article published in Education Sciences
Higher education assessment practice in the era of generative AI tools
Apr 01, 2024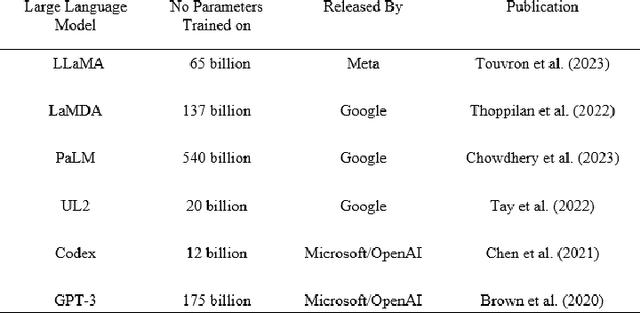
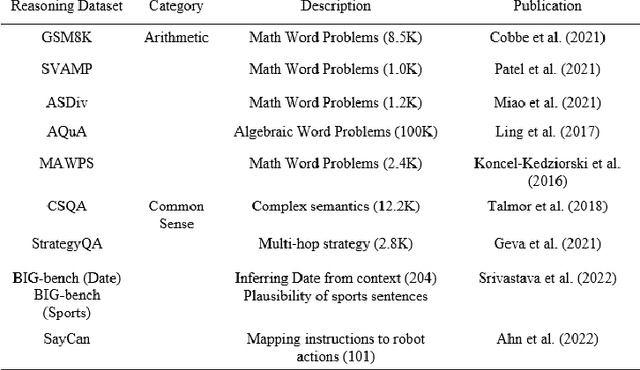
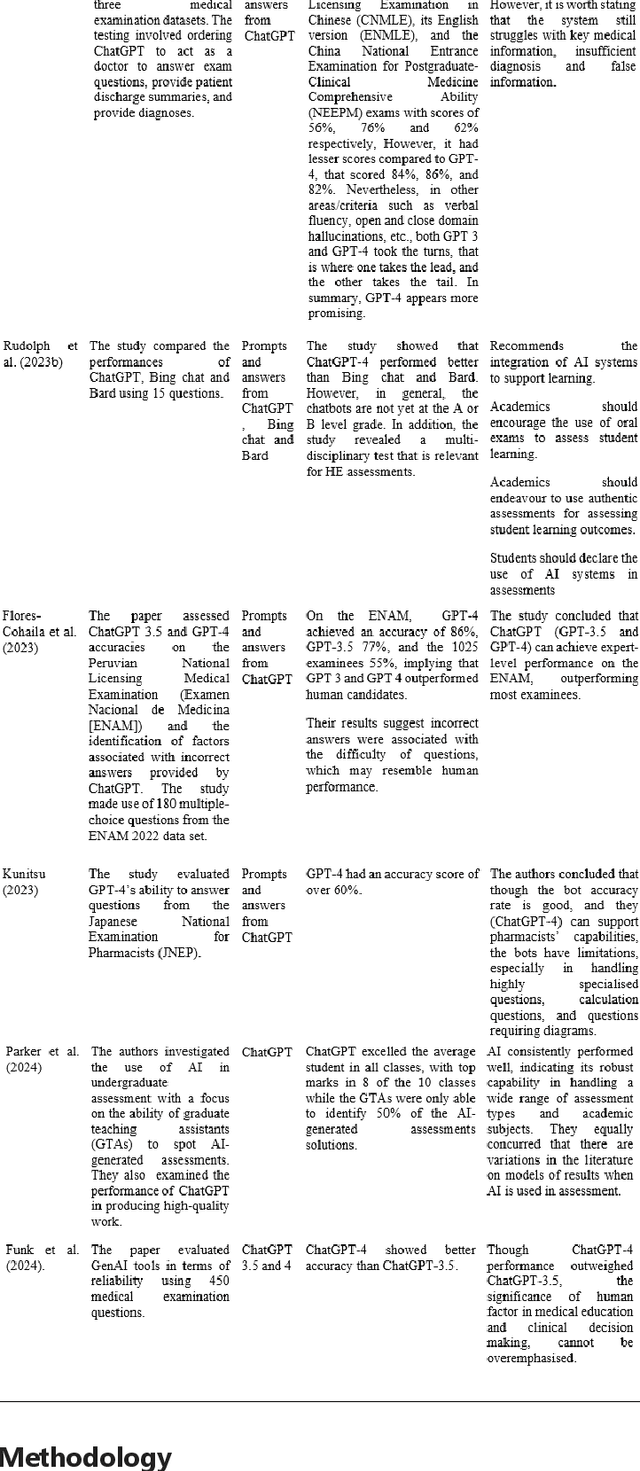
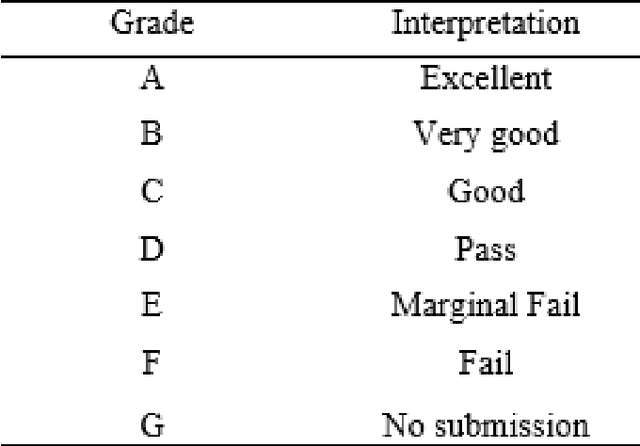
The higher education (HE) sector benefits every nation's economy and society at large. However, their contributions are challenged by advanced technologies like generative artificial intelligence (GenAI) tools. In this paper, we provide a comprehensive assessment of GenAI tools towards assessment and pedagogic practice and, subsequently, discuss the potential impacts. This study experimented using three assessment instruments from data science, data analytics, and construction management disciplines. Our findings are two-fold: first, the findings revealed that GenAI tools exhibit subject knowledge, problem-solving, analytical, critical thinking, and presentation skills and thus can limit learning when used unethically. Secondly, the design of the assessment of certain disciplines revealed the limitations of the GenAI tools. Based on our findings, we made recommendations on how AI tools can be utilised for teaching and learning in HE.
* 11 pages, 7 tables published in the Journal of Applied Learning & Teaching
Analysing the Influence of Macroeconomic Factors on Credit Risk in the UK Banking Sector
Jan 26, 2024
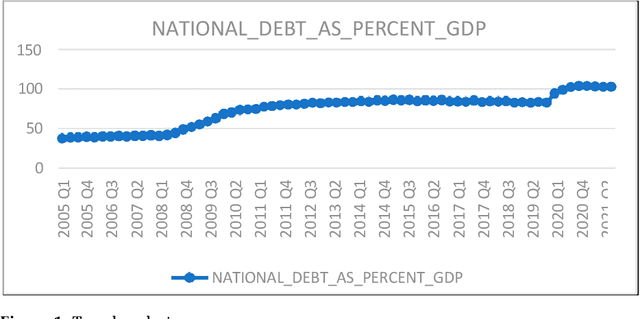

Macroeconomic factors have a critical impact on banking credit risk, which cannot be directly controlled by banks, and therefore, there is a need for an early credit risk warning system based on the macroeconomy. By comparing different predictive models (traditional statistical and machine learning algorithms), this study aims to examine the macroeconomic determinants impact on the UK banking credit risk and assess the most accurate credit risk estimate using predictive analytics. This study found that the variance-based multi-split decision tree algorithm is the most precise predictive model with interpretable, reliable, and robust results. Our model performance achieved 95% accuracy and evidenced that unemployment and inflation rate are significant credit risk predictors in the UK banking context. Our findings provided valuable insights such as a positive association between credit risk and inflation, the unemployment rate, and national savings, as well as a negative relationship between credit risk and national debt, total trade deficit, and national income. In addition, we empirically showed the relationship between national savings and non-performing loans, thus proving the paradox of thrift. These findings benefit the credit risk management team in monitoring the macroeconomic factors thresholds and implementing critical reforms to mitigate credit risk.
Content-Aware Tweet Location Inference using Quadtree Spatial Partitioning and Jaccard-Cosine Word Embedding
Jan 16, 2024
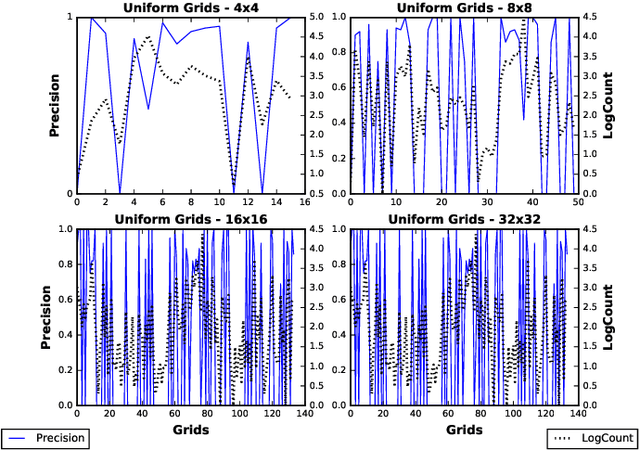
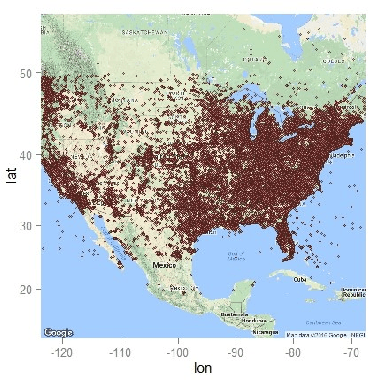
Inferring locations from user texts on social media platforms is a non-trivial and challenging problem relating to public safety. We propose a novel non-uniform grid-based approach for location inference from Twitter messages using Quadtree spatial partitions. The proposed algorithm uses natural language processing (NLP) for semantic understanding and incorporates Cosine similarity and Jaccard similarity measures for feature vector extraction and dimensionality reduction. We chose Twitter as our experimental social media platform due to its popularity and effectiveness for the dissemination of news and stories about recent events happening around the world. Our approach is the first of its kind to make location inference from tweets using Quadtree spatial partitions and NLP, in hybrid word-vector representations. The proposed algorithm achieved significant classification accuracy and outperformed state-of-the-art grid-based content-only location inference methods by up to 24% in correctly predicting tweet locations within a 161km radius and by 300km in median error distance on benchmark datasets.
* 8 pages, 7 figures, 5 tables, International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2018)
Exploring Content-Based and Meta-Data Analysis for Detecting Fake News Infodemic: A case study on COVID-19
Jan 16, 2024



The coronavirus pandemic (COVID-19) is probably the most disruptive global health disaster in recent history. It negatively impacted the whole world and virtually brought the global economy to a standstill. However, as the virus was spreading, infecting people and claiming thousands of lives so was the spread and propagation of fake news, misinformation and disinformation about the event. These included the spread of unconfirmed health advice and remedies on social media. In this paper, false information about the pandemic is identified using a content-based approach and metadata curated from messages posted to online social networks. A content-based approach combined with metadata as well as an initial feature analysis is used and then several supervised learning models are tested for identifying and predicting misleading posts. Our approach shows up to 93% accuracy in the detection of fake news related posts about the COVID-19 pandemic
* 8 pages, 5 figures, 3 tables, International Conference for Pattern Recognition Systems (ICPRS 2022)
Fake News Identification on Twitter with Hybrid CNN and RNN Models
Jun 29, 2018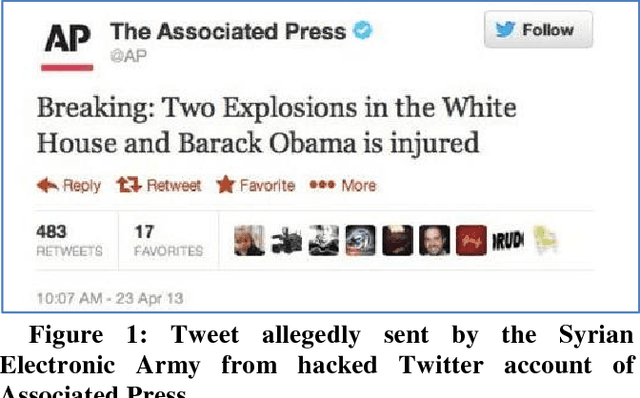


The problem associated with the propagation of fake news continues to grow at an alarming scale. This trend has generated much interest from politics to academia and industry alike. We propose a framework that detects and classifies fake news messages from Twitter posts using hybrid of convolutional neural networks and long-short term recurrent neural network models. The proposed work using this deep learning approach achieves 82% accuracy. Our approach intuitively identifies relevant features associated with fake news stories without previous knowledge of the domain.
* 5 Pages