 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Aware Tweet Location Inference using Quadtree Spatial Partitioning and Jaccard-Cosine Word Embedding
Jan 16, 2024
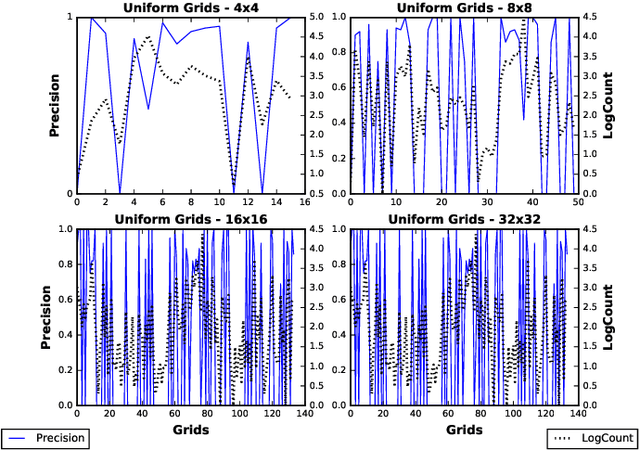
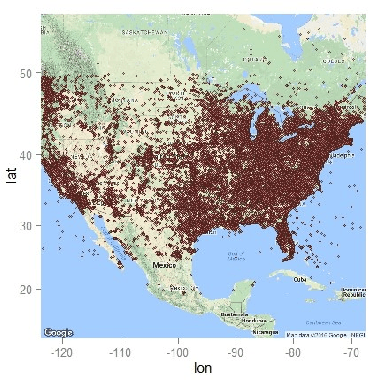
Inferring locations from user texts on social media platforms is a non-trivial and challenging problem relating to public safety. We propose a novel non-uniform grid-based approach for location inference from Twitter messages using Quadtree spatial partitions. The proposed algorithm uses natural language processing (NLP) for semantic understanding and incorporates Cosine similarity and Jaccard similarity measures for feature vector extraction and dimensionality reduction. We chose Twitter as our experimental social media platform due to its popularity and effectiveness for the dissemination of news and stories about recent events happening around the world. Our approach is the first of its kind to make location inference from tweets using Quadtree spatial partitions and NLP, in hybrid word-vector representations. The proposed algorithm achieved significant classification accuracy and outperformed state-of-the-art grid-based content-only location inference methods by up to 24% in correctly predicting tweet locations within a 161km radius and by 300km in median error distance on benchmark datasets.
* 8 pages, 7 figures, 5 tables, International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2018)
Semantic Metadata Extraction from Dense Video Captioning
Nov 05, 2022Annotation of multimedia data by humans is time-consuming and costly, while reliable automatic generation of semantic metadata is a major challenge. We propose a framework to extract semantic metadata from automatically generated video captions. As metadata, we consider entities, the entities' properties, relations between entities, and the video category. We employ two state-of-the-art dense video captioning models with masked transformer (MT) and parallel decoding (PVDC) to generate captions for videos of the ActivityNet Captions dataset. Our experiments show that it is possible to extract entities, their properties, relations between entities, and the video category from the generated captions. We observe that the quality of the extracted information is mainly influenced by the quality of the event localization in the video as well as the performance of the event caption generation.
Long-term Correlation Tracking using Multi-layer Hybrid Features in Sparse and Dense Environments
Sep 06, 2018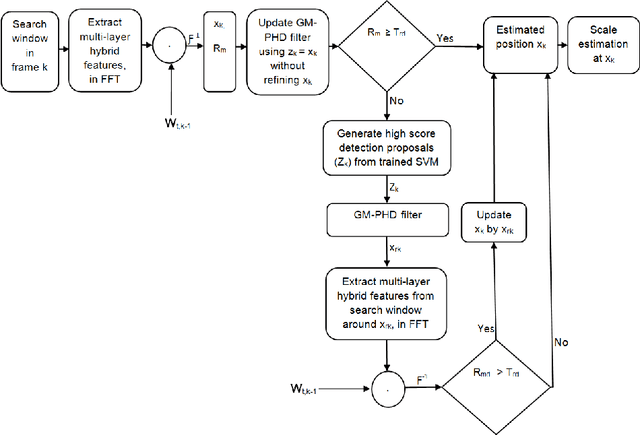

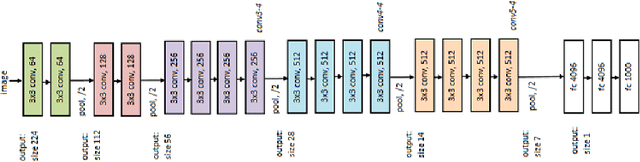
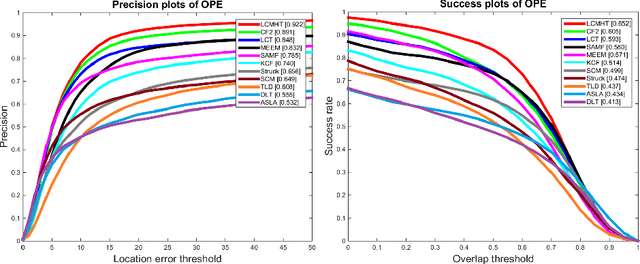
Tracking a target of interest in both sparse and crowded environments is a challenging problem, not yet successfully addressed in the literature. In this paper, we propose a new long-term visual tracking algorithm, learning discriminative correlation filters and using an online classifier, to track a target of interest in both sparse and crowded video sequences. First, we learn a translation correlation filter using a multi-layer hybrid of convolutional neural networks (CNN) and traditional hand-crafted features. We combine advantages of both the lower convolutional layer which retains more spatial details for precise localization and the higher convolutional layer which encodes semantic information for handling appearance variations, and then integrate these with histogram of oriented gradients (HOG) and color-naming traditional features. Second, we include a re-detection module for overcoming tracking failures due to long-term occlusions by training an incremental (online) SVM on the most confident frames using hand-engineered features. This re-detection module is activated only when the correlation response of the object is below some pre-defined threshold. This generates high score detection proposals which are temporally filtered using a Gaussian mixture probability hypothesis density (GM-PHD) filter to find the detection proposal with the maximum weight as the target state estimate by removing the other detection proposals as clutter. Finally, we learn a scale correlation filter for estimating the scale of a target by constructing a target pyramid around the estimated or re-detected position using the HOG features. We carry out extensive experiments on both sparse and dense data sets which show that our method significantly outperforms state-of-the-art methods.
Fake News Identification on Twitter with Hybrid CNN and RNN Models
Jun 29, 2018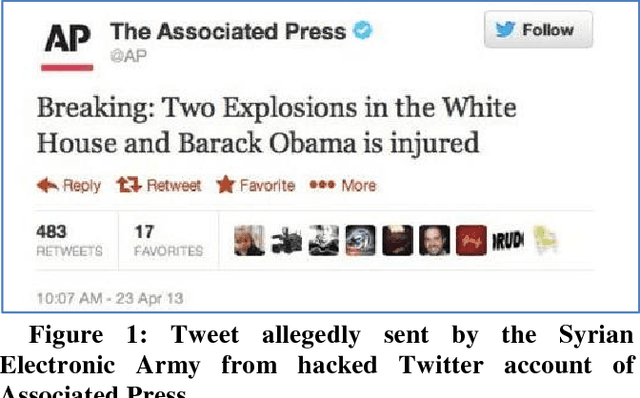


The problem associated with the propagation of fake news continues to grow at an alarming scale. This trend has generated much interest from politics to academia and industry alike. We propose a framework that detects and classifies fake news messages from Twitter posts using hybrid of convolutional neural networks and long-short term recurrent neural network models. The proposed work using this deep learning approach achieves 82% accuracy. Our approach intuitively identifies relevant features associated with fake news stories without previous knowledge of the domain.
* 5 Pages