 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRUvader: Sentiment-Informed Stock Market Prediction
Dec 07, 2024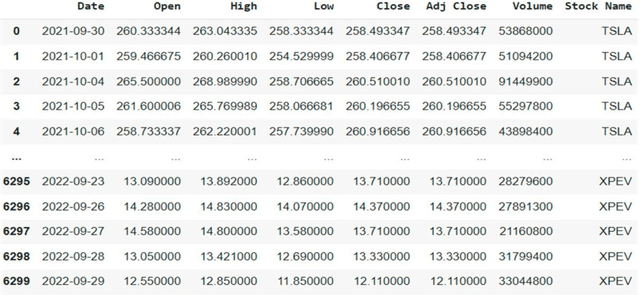

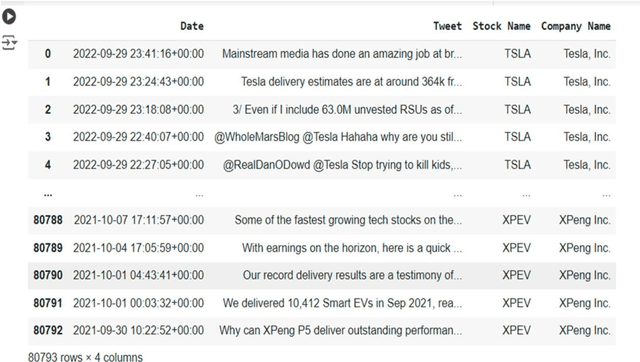
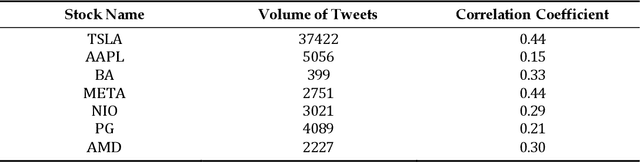
Stock price prediction is challenging due to global economic instability, high volatility, and the complexity of financial markets. Hence, this study compared several machine learning algorithms for stock market prediction and further examined the influence of a sentiment analysis indicator on the prediction of stock prices. Our results were two-fold. Firstly, we used a lexicon-based sentiment analysis approach to identify sentiment features, thus evidencing the correlation between the sentiment indicator and stock price movement. Secondly, we proposed the use of GRUvader, an optimal gated recurrent unit network, for stock market prediction. Our findings suggest that stand-alone models struggled compared with AI-enhanced models. Thus, our paper makes further recommendations on latter systems.
* 18 pages
Innovative Sentiment Analysis and Prediction of Stock Price Using FinBERT, GPT-4 and Logistic Regression: A Data-Driven Approach
Dec 07, 2024This study explores the comparative performance of cutting-edge AI models, i.e., Finaance Bidirectional Encoder representations from Transsformers (FinBERT), Generatice Pre-trained Transformer GPT-4, and Logistic Regression, for sentiment analysis and stock index prediction using financial news and the NGX All-Share Index data label. By leveraging advanced natural language processing models like GPT-4 and FinBERT, alongside a traditional machine learning model, Logistic Regression, we aim to classify market sentiment, generate sentiment scores, and predict market price movements. This research highlights global AI advancements in stock markets, showcasing how state-of-the-art language models can contribute to understanding complex financial data. The models were assessed using metrics such as accuracy, precision, recall, F1 score, and ROC AUC. Results indicate that Logistic Regression outperformed the more computationally intensive FinBERT and predefined approach of versatile GPT-4, with an accuracy of 81.83% and a ROC AUC of 89.76%. The GPT-4 predefined approach exhibited a lower accuracy of 54.19% but demonstrated strong potential in handling complex data. FinBERT, while offering more sophisticated analysis, was resource-demanding and yielded a moderate performance. Hyperparameter optimization using Optuna and cross-validation techniques ensured the robustness of the models. This study highlights the strengths and limitations of the practical applications of AI approaches in stock market prediction and presents Logistic Regression as the most efficient model for this task, with FinBERT and GPT-4 representing emerging tools with potential for future exploration and innovation in AI-driven financial analytics
* 21 pages
A Systematic Review of Generative AI for Teaching and Learning Practice
Jun 13, 2024



The use of generative artificial intelligence (GenAI) in academia is a subjective and hotly debated topic. Currently, there are no agreed guidelines towards the usage of GenAI systems in higher education (HE) and, thus, it is still unclear how to make effective use of the technology for teaching and learning practice. This paper provides an overview of the current state of research on GenAI for teaching and learning in HE. To this end, this study conducted a systematic review of relevant studies indexed by Scopus, using the preferred reporting items for systematic reviews and meta-analyses (PRISMA) guidelines. The search criteria revealed a total of 625 research papers, of which 355 met the final inclusion criteria. The findings from the review showed the current state and the future trends in documents, citations, document sources/authors, keywords, and co-authorship. The research gaps identified suggest that while some authors have looked at understanding the detection of AI-generated text, it may be beneficial to understand how GenAI can be incorporated into supporting the educational curriculum for assessments, teaching, and learning delivery. Furthermore, there is a need for additional interdisciplinary, multidimensional studies in HE through collaboration. This will strengthen the awareness and understanding of students, tutors, and other stakeholders, which will be instrumental in formulating guidelines, frameworks, and policies for GenAI usage.
* 20 pages, 10 figures, article published in Education Sciences
Higher education assessment practice in the era of generative AI tools
Apr 01, 2024
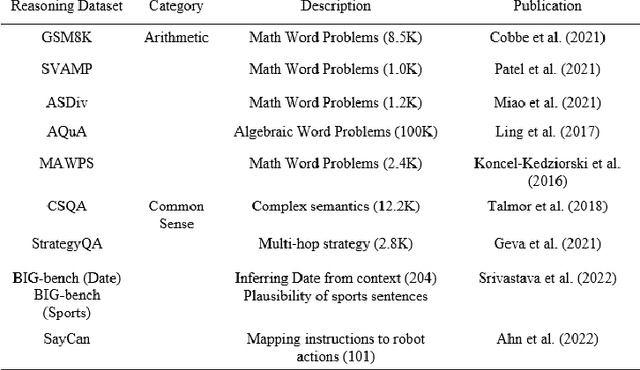
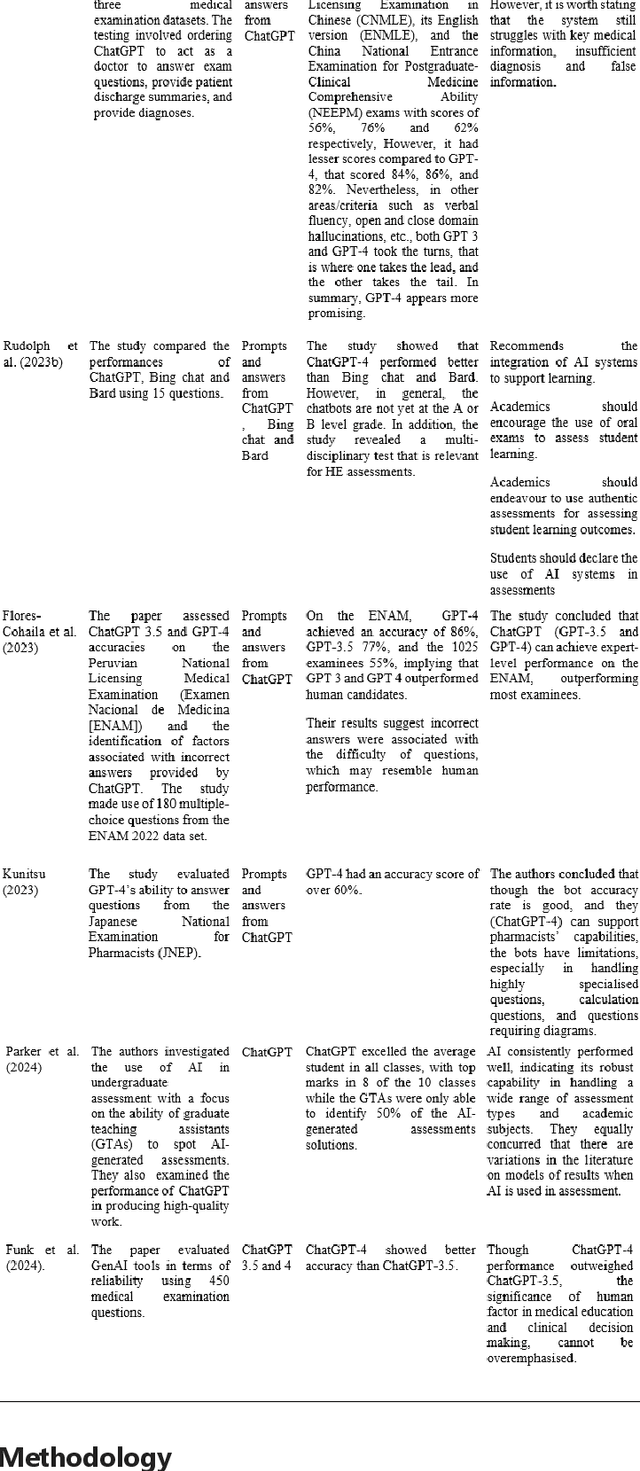
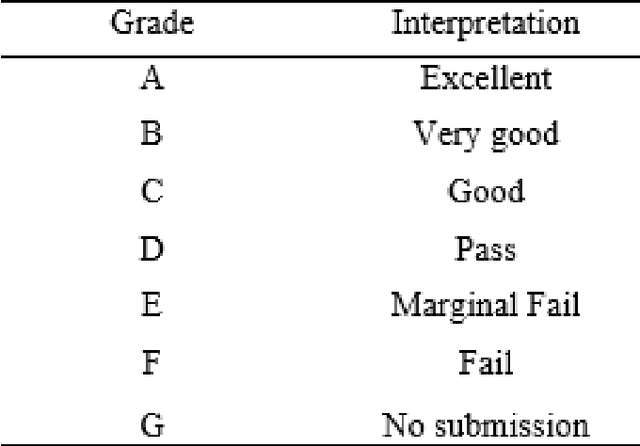
The higher education (HE) sector benefits every nation's economy and society at large. However, their contributions are challenged by advanced technologies like generative artificial intelligence (GenAI) tools. In this paper, we provide a comprehensive assessment of GenAI tools towards assessment and pedagogic practice and, subsequently, discuss the potential impacts. This study experimented using three assessment instruments from data science, data analytics, and construction management disciplines. Our findings are two-fold: first, the findings revealed that GenAI tools exhibit subject knowledge, problem-solving, analytical, critical thinking, and presentation skills and thus can limit learning when used unethically. Secondly, the design of the assessment of certain disciplines revealed the limitations of the GenAI tools. Based on our findings, we made recommendations on how AI tools can be utilised for teaching and learning in HE.
* 11 pages, 7 tables published in the Journal of Applied Learning & Teaching
An Exploration of Clustering Algorithms for Customer Segmentation in the UK Retail Market
Feb 06, 2024Recently, peoples awareness of online purchases has significantly risen. This has given rise to online retail platforms and the need for a better understanding of customer purchasing behaviour. Retail companies are pressed with the need to deal with a high volume of customer purchases, which requires sophisticated approaches to perform more accurate and efficient customer segmentation. Customer segmentation is a marketing analytical tool that aids customer-centric service and thus enhances profitability. In this paper, we aim to develop a customer segmentation model to improve decision-making processes in the retail market industry. To achieve this, we employed a UK-based online retail dataset obtained from the UCI machine learning repository. The retail dataset consists of 541,909 customer records and eight features. Our study adopted the RFM (recency, frequency, and monetary) framework to quantify customer values. Thereafter, we compared several state-of-the-art (SOTA) clustering algorithms, namely, K-means clustering, the Gaussian mixture model (GMM), density-based spatial clustering of applications with noise (DBSCAN), agglomerative clustering, and balanced iterative reducing and clustering using hierarchies (BIRCH). The results showed the GMM outperformed other approaches, with a Silhouette Score of 0.80.
* 15 pages, Journal of Analytics
An Optimal House Price Prediction Algorithm: XGBoost
Feb 06, 2024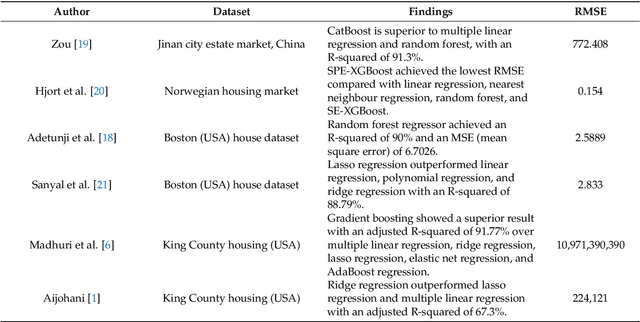

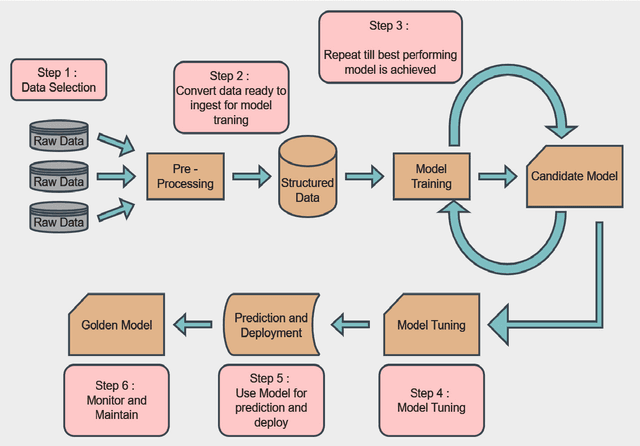

An accurate prediction of house prices is a fundamental requirement for various sectors including real estate and mortgage lending. It is widely recognized that a property value is not solely determined by its physical attributes but is significantly influenced by its surrounding neighbourhood. Meeting the diverse housing needs of individuals while balancing budget constraints is a primary concern for real estate developers. To this end, we addressed the house price prediction problem as a regression task and thus employed various machine learning techniques capable of expressing the significance of independent variables. We made use of the housing dataset of Ames City in Iowa, USA to compare support vector regressor, random forest regressor, XGBoost, multilayer perceptron and multiple linear regression algorithms for house price prediction. Afterwards, we identified the key factors that influence housing costs. Our results show that XGBoost is the best performing model for house price prediction.
* 16 pages, Journal of Analytics
The Use of a Large Language Model for Cyberbullying Detection
Feb 06, 2024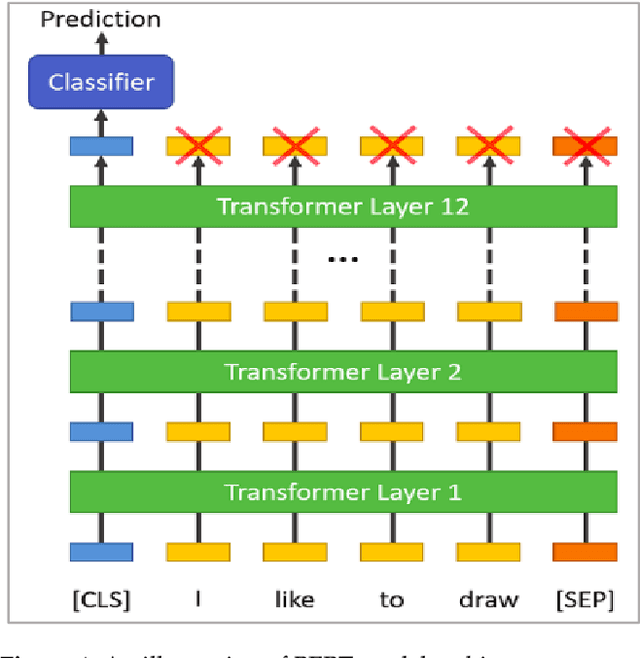

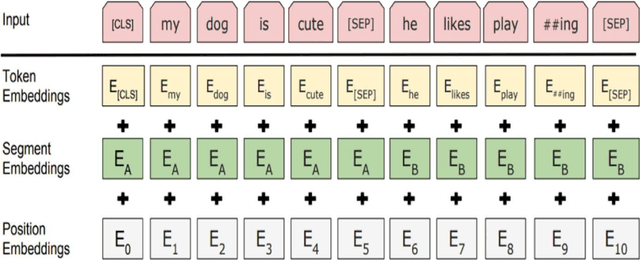

The dominance of social media has added to the channels of bullying for perpetrators. Unfortunately, cyberbullying (CB) is the most prevalent phenomenon in todays cyber world, and is a severe threat to the mental and physical health of citizens. This opens the need to develop a robust system to prevent bullying content from online forums, blogs, and social media platforms to manage the impact in our society. Several machine learning (ML) algorithms have been proposed for this purpose. However, their performances are not consistent due to high class imbalance and generalisation issues. In recent years, large language models (LLMs) like BERT and RoBERTa have achieved state-of-the-art (SOTA) results in several natural language processing (NLP) tasks. Unfortunately, the LLMs have not been applied extensively for CB detection. In our paper, we explored the use of these models for cyberbullying (CB) detection. We have prepared a new dataset (D2) from existing studies (Formspring and Twitter). Our experimental results for dataset D1 and D2 showed that RoBERTa outperformed other models.
* 14 pages, Journal of Analytics
Comparison of Topic Modelling Approaches in the Banking Context
Feb 05, 2024
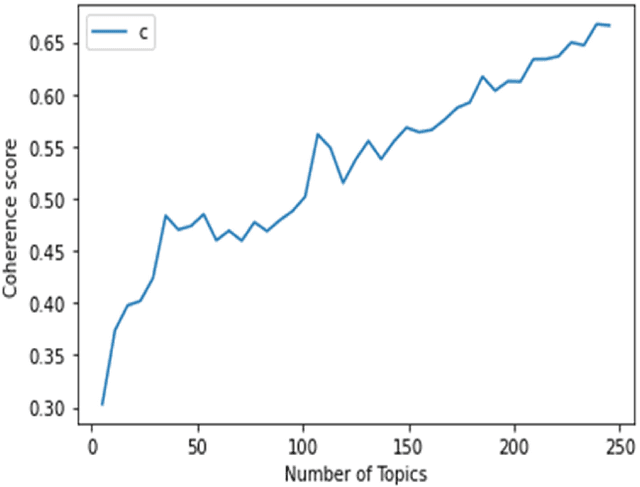
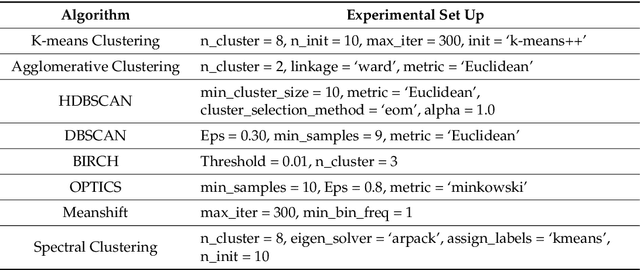
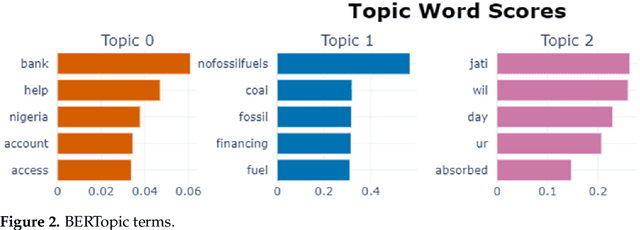
Topic modelling is a prominent task for automatic topic extraction in many applications such as sentiment analysis and recommendation systems. The approach is vital for service industries to monitor their customer discussions. The use of traditional approaches such as Latent Dirichlet Allocation (LDA) for topic discovery has shown great performances, however, they are not consistent in their results as these approaches suffer from data sparseness and inability to model the word order in a document. Thus, this study presents the use of Kernel Principal Component Analysis (KernelPCA) and K-means Clustering in the BERTopic architecture. We have prepared a new dataset using tweets from customers of Nigerian banks and we use this to compare the topic modelling approaches. Our findings showed KernelPCA and K-means in the BERTopic architecture-produced coherent topics with a coherence score of 0.8463.
* 14 pages, Journal of Applied Science
Analysing the Influence of Macroeconomic Factors on Credit Risk in the UK Banking Sector
Jan 26, 2024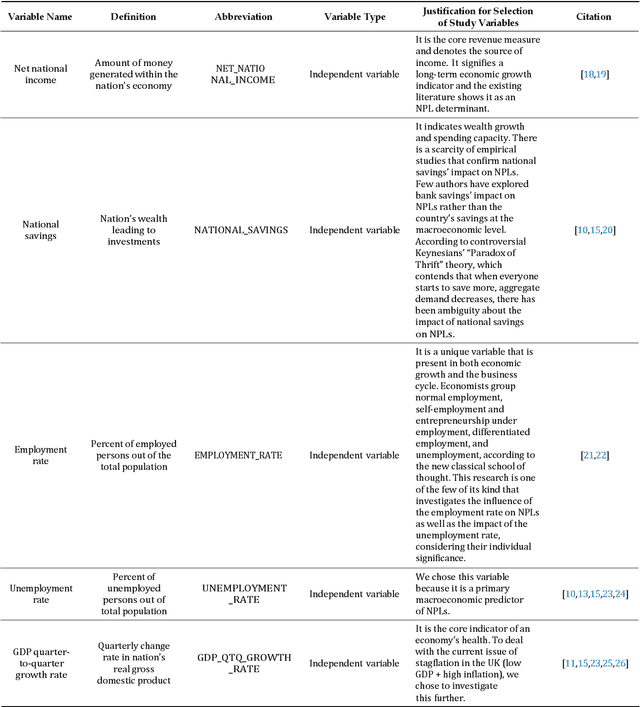
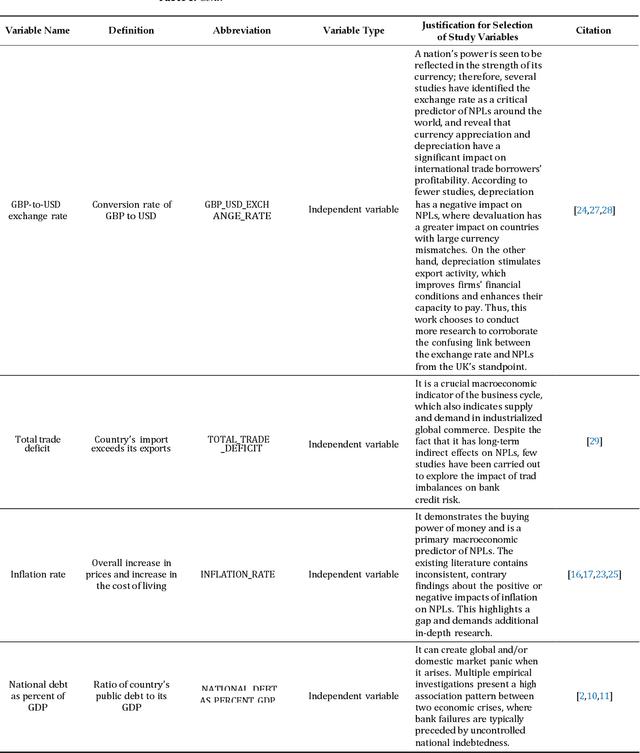
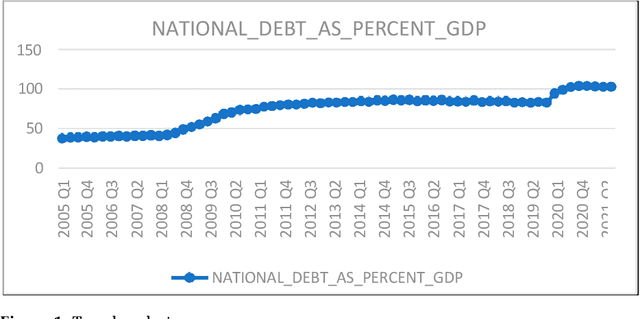

Macroeconomic factors have a critical impact on banking credit risk, which cannot be directly controlled by banks, and therefore, there is a need for an early credit risk warning system based on the macroeconomy. By comparing different predictive models (traditional statistical and machine learning algorithms), this study aims to examine the macroeconomic determinants impact on the UK banking credit risk and assess the most accurate credit risk estimate using predictive analytics. This study found that the variance-based multi-split decision tree algorithm is the most precise predictive model with interpretable, reliable, and robust results. Our model performance achieved 95% accuracy and evidenced that unemployment and inflation rate are significant credit risk predictors in the UK banking context. Our findings provided valuable insights such as a positive association between credit risk and inflation, the unemployment rate, and national savings, as well as a negative relationship between credit risk and national debt, total trade deficit, and national income. In addition, we empirically showed the relationship between national savings and non-performing loans, thus proving the paradox of thrift. These findings benefit the credit risk management team in monitoring the macroeconomic factors thresholds and implementing critical reforms to mitigate credit risk.