 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNC-NCD: Novel Class Discovery for Node Classification
Paper and Code
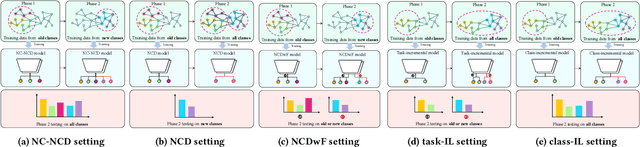

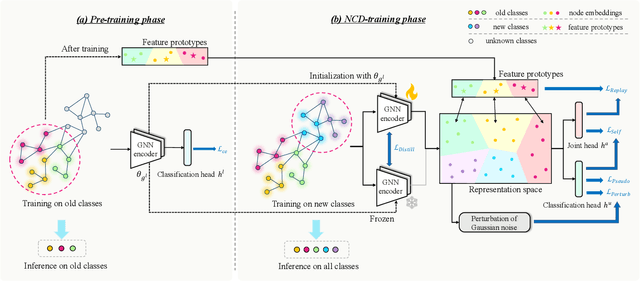
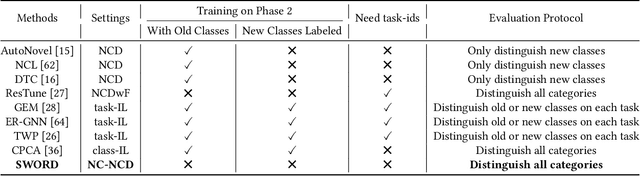
Novel Class Discovery (NCD) involves identifying new categories within unlabeled data by utilizing knowledge acquired from previously established categories. However, existing NCD methods often struggle to maintain a balance between the performance of old and new categories. Discovering unlabeled new categories in a class-incremental way is more practical but also more challenging, as it is frequently hindered by either catastrophic forgetting of old categories or an inability to learn new ones. Furthermore, the implementation of NCD on continuously scalable graph-structured data remains an under-explored area. In response to these challenges, we introduce for the first time a more practical NCD scenario for node classification (i.e., NC-NCD), and propose a novel self-training framework with prototype replay and distillation called SWORD, adopted to our NC-NCD setting. Our approach enables the model to cluster unlabeled new category nodes after learning labeled nodes while preserving performance on old categories without reliance on old category nodes. SWORD achieves this by employing a self-training strategy to learn new categories and preventing the forgetting of old categories through the joint use of feature prototypes and knowledge distillation. Extensive experiments on four common benchmarks demonstrate the superiority of SWORD over other state-of-the-art methods.