Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisrupting Model Training with Adversarial Shortcuts
Paper and Code
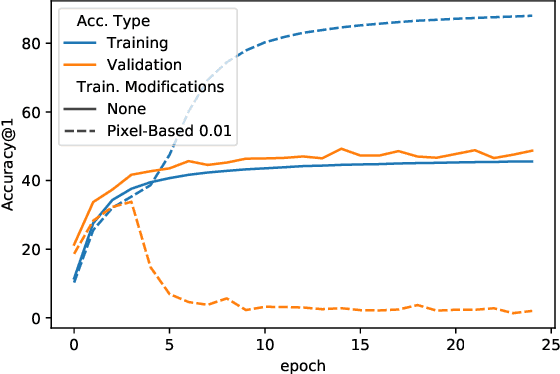

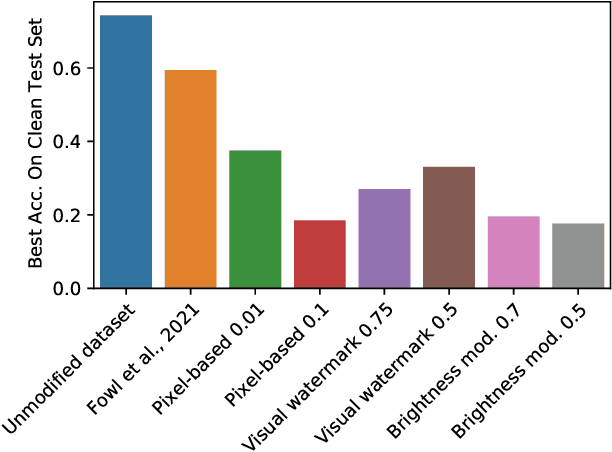
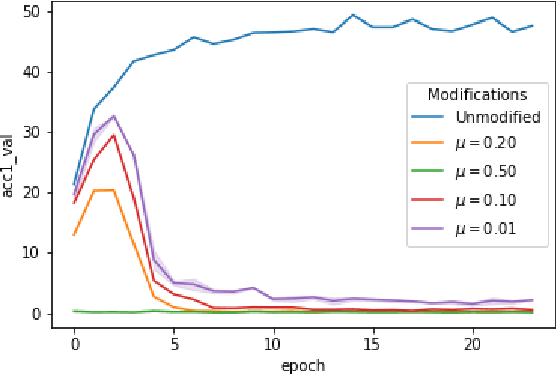
When data is publicly released for human consumption, it is unclear how to prevent its unauthorized usage for machine learning purposes. Successful model training may be preventable with carefully designed dataset modifications, and we present a proof-of-concept approach for the image classification setting. We propose methods based on the notion of adversarial shortcuts, which encourage models to rely on non-robust signals rather than semantic features, and our experiments demonstrate that these measures successfully prevent deep learning models from achieving high accuracy on real, unmodified data examples.
View paper on
 OpenReview
OpenReview