 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling variable guide efficiency in pooled CRISPR screens with ContrastiveVI+
Nov 11, 2024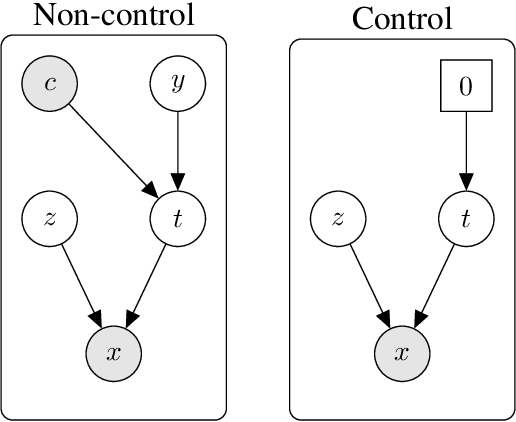
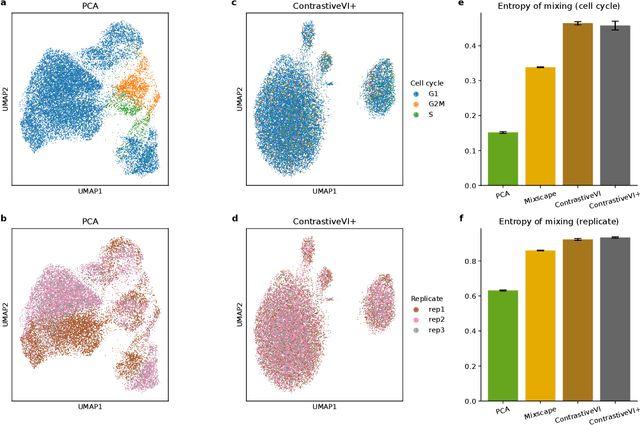
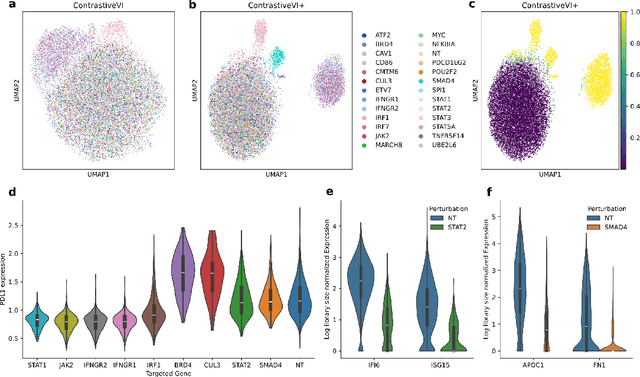
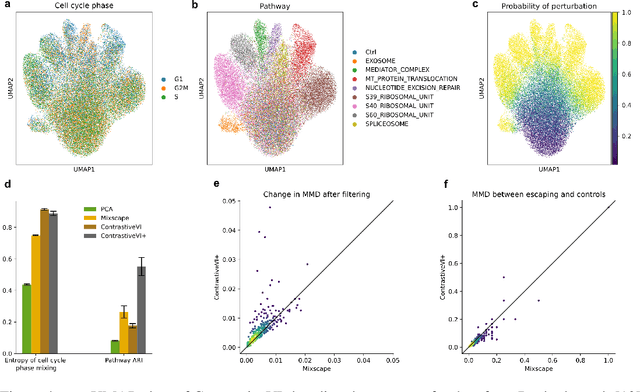
Genetic screens mediated via CRISPR-Cas9 combined with high-content readouts have emerged as powerful tools for biological discovery. However, computational analyses of these screens come with additional challenges beyond those found with standard scRNA-seq analyses. For example, perturbation-induced variations of interest may be subtle and masked by other dominant source of variation shared with controls, and variable guide efficiency results in some cells not undergoing genetic perturbation despite expressing a guide RNA. While a number of methods have been developed to address the former problem by explicitly disentangling perturbation-induced variations from those shared with controls, less attention has been paid to the latter problem of noisy perturbation labels. To address this issue, here we propose ContrastiveVI+, a generative modeling framework that both disentangles perturbation-induced from non-perturbation-related variations while also inferring whether cells truly underwent genomic edits. Applied to three large-scale Perturb-seq datasets, we find that ContrastiveVI+ better recovers known perturbation-induced variations compared to previous methods while successfully identifying cells that escaped the functional consequences of guide RNA expression. An open-source implementation of our model is available at \url{https://github.com/insitro/contrastive_vi_plus}.
Feature Selection in the Contrastive Analysis Setting
Oct 27, 2023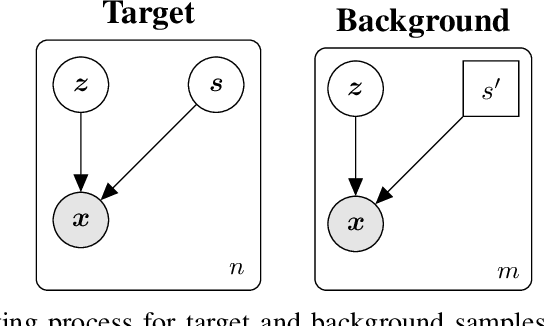
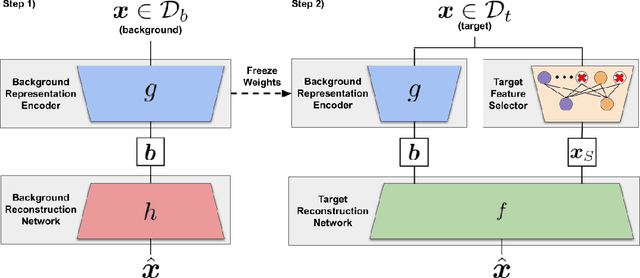
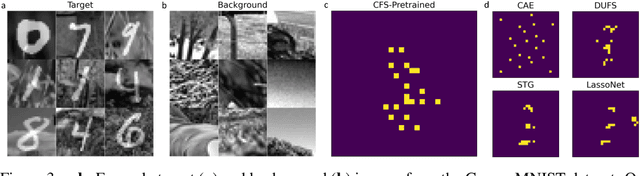

Contrastive analysis (CA) refers to the exploration of variations uniquely enriched in a target dataset as compared to a corresponding background dataset generated from sources of variation that are irrelevant to a given task. For example, a biomedical data analyst may wish to find a small set of genes to use as a proxy for variations in genomic data only present among patients with a given disease (target) as opposed to healthy control subjects (background). However, as of yet the problem of feature selection in the CA setting has received little attention from the machine learning community. In this work we present contrastive feature selection (CFS), a method for performing feature selection in the CA setting. We motivate our approach with a novel information-theoretic analysis of representation learning in the CA setting, and we empirically validate CFS on a semi-synthetic dataset and four real-world biomedical datasets. We find that our method consistently outperforms previously proposed state-of-the-art supervised and fully unsupervised feature selection methods not designed for the CA setting. An open-source implementation of our method is available at https://github.com/suinleelab/CFS.
Moment Matching Deep Contrastive Latent Variable Models
Feb 21, 2022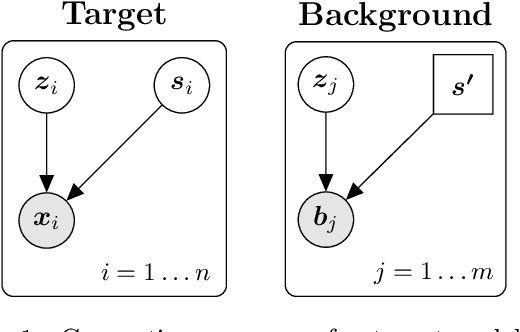
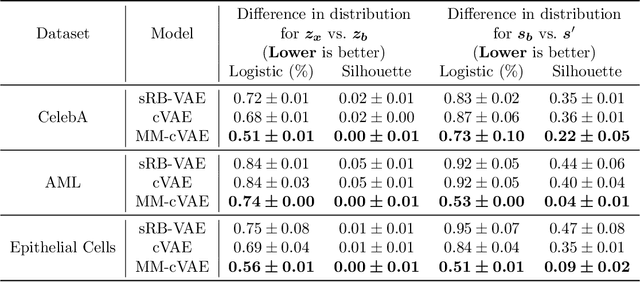
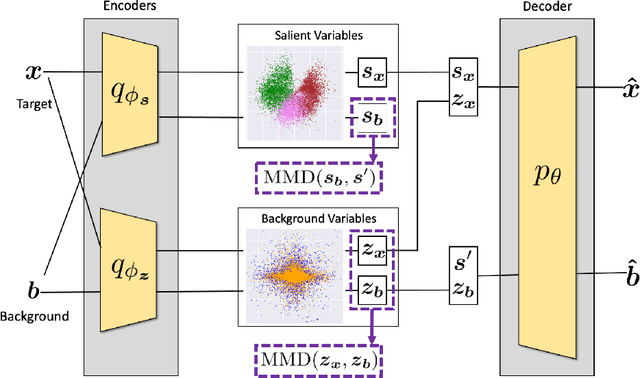
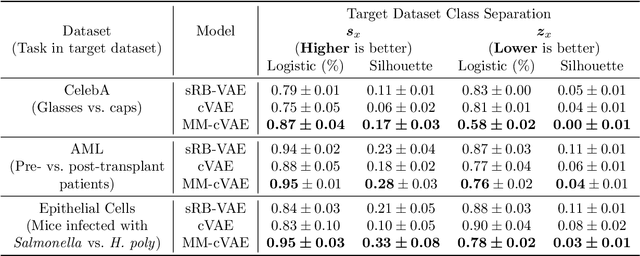
In the contrastive analysis (CA) setting, machine learning practitioners are specifically interested in discovering patterns that are enriched in a target dataset as compared to a background dataset generated from sources of variation irrelevant to the task at hand. For example, a biomedical data analyst may seek to understand variations in genomic data only present among patients with a given disease as opposed to those also present in healthy control subjects. Such scenarios have motivated the development of contrastive latent variable models to isolate variations unique to these target datasets from those shared across the target and background datasets, with current state of the art models based on the variational autoencoder (VAE) framework. However, previously proposed models do not explicitly enforce the constraints on latent variables underlying CA, potentially leading to the undesirable leakage of information between the two sets of latent variables. Here we propose the moment matching contrastive VAE (MM-cVAE), a reformulation of the VAE for CA that uses the maximum mean discrepancy to explicitly enforce two crucial latent variable constraints underlying CA. On three challenging CA tasks we find that our method outperforms the previous state-of-the-art both qualitatively and on a set of quantitative metrics.
Learning Deep Attribution Priors Based On Prior Knowledge
Feb 07, 2020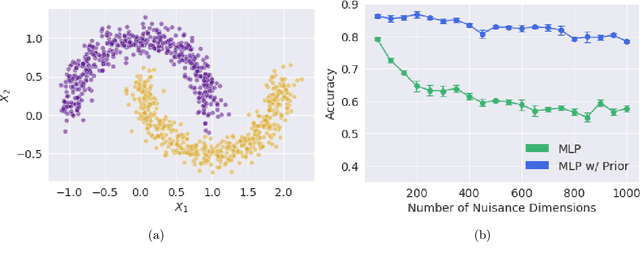
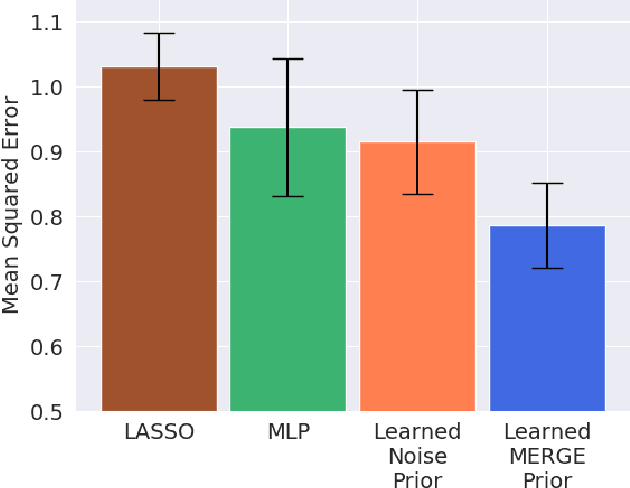
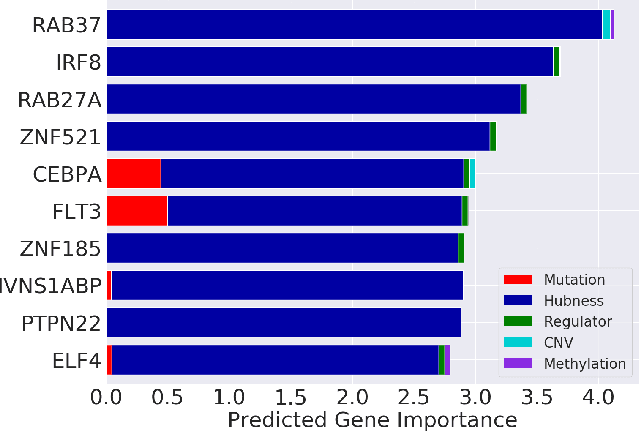
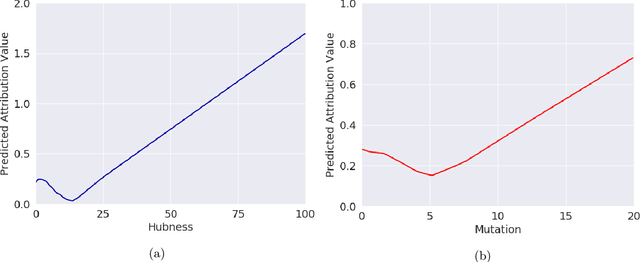
Feature attribution methods are an essential tool for understanding the behavior of complex deep learning models. However, ensuring that models produce meaningful explanations, rather than ones that rely on noise, is not straightforward. Exacerbating this problem is the fact that attribution methods do not provide insight as to why features are assigned their attribution values, leading to explanations that are difficult to interpret. In real-world problems we often have sets of additional information for each feature that are predictive of that feature's importance to the task at hand. Here we propose the deep attribution prior (DAPr) framework to exploit such information to overcome the limitations of attribution methods. Our framework jointly learns a relationship between prior information and feature importance, as well as biases models to have explanations that rely on features predicted to be important. We find that our framework both results in networks that generalize better to out of sample data and admits new methods for interpreting model explanations.
Defending against Adversarial Images using Basis Functions Transformations
Apr 16, 2018


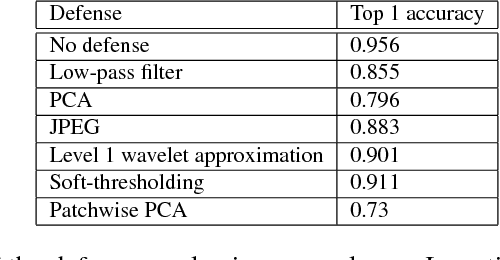
We study the effectiveness of various approaches that defend against adversarial attacks on deep networks via manipulations based on basis function representations of images. Specifically, we experiment with low-pass filtering, PCA, JPEG compression, low resolution wavelet approximation, and soft-thresholding. We evaluate these defense techniques using three types of popular attacks in black, gray and white-box settings. Our results show JPEG compression tends to outperform the other tested defenses in most of the settings considered, in addition to soft-thresholding, which performs well in specific cases, and yields a more mild decrease in accuracy on benign examples. In addition, we also mathematically derive a novel white-box attack in which the adversarial perturbation is composed only of terms corresponding a to pre-determined subset of the basis functions, of which a "low frequency attack" is a special case.