 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiasICL: In-Context Learning and Demographic Biases of Vision Language Models
Mar 04, 2025



Vision language models (VLMs) show promise in medical diagnosis, but their performance across demographic subgroups when using in-context learning (ICL) remains poorly understood. We examine how the demographic composition of demonstration examples affects VLM performance in two medical imaging tasks: skin lesion malignancy prediction and pneumothorax detection from chest radiographs. Our analysis reveals that ICL influences model predictions through multiple mechanisms: (1) ICL allows VLMs to learn subgroup-specific disease base rates from prompts and (2) ICL leads VLMs to make predictions that perform differently across demographic groups, even after controlling for subgroup-specific disease base rates. Our empirical results inform best-practices for prompting current VLMs (specifically examining demographic subgroup performance, and matching base rates of labels to target distribution at a bulk level and within subgroups), while also suggesting next steps for improving our theoretical understanding of these models.
Learning Deep Attribution Priors Based On Prior Knowledge
Feb 07, 2020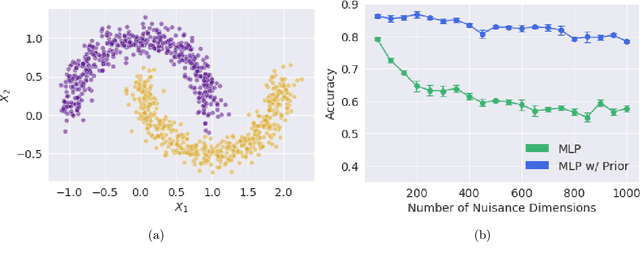
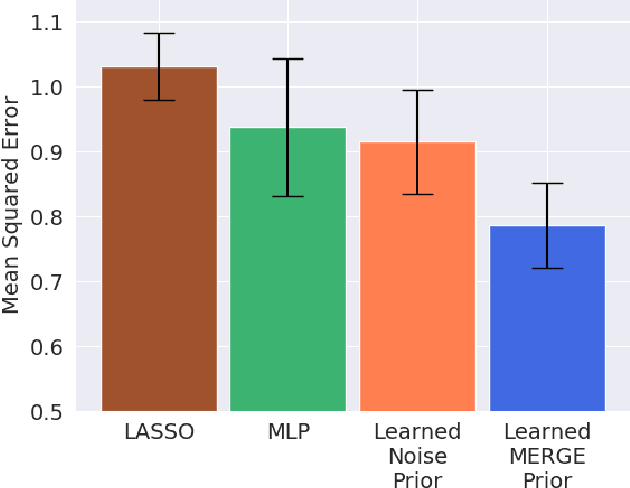
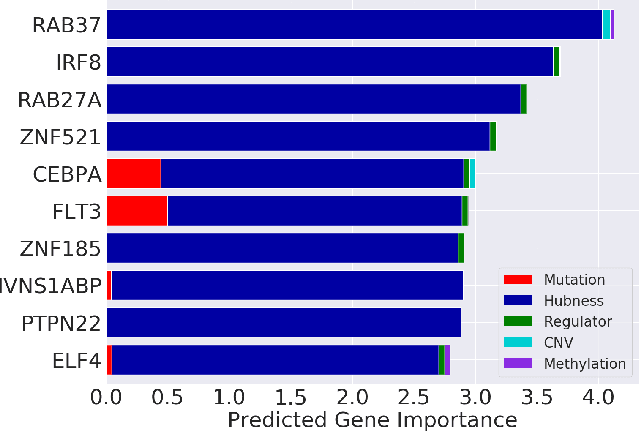
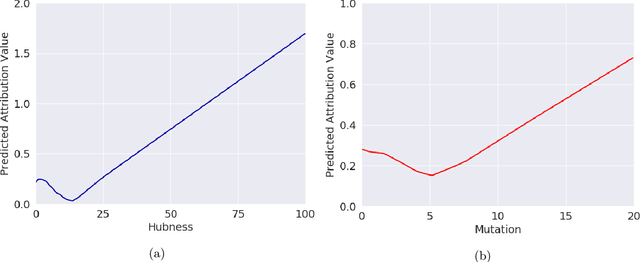
Feature attribution methods are an essential tool for understanding the behavior of complex deep learning models. However, ensuring that models produce meaningful explanations, rather than ones that rely on noise, is not straightforward. Exacerbating this problem is the fact that attribution methods do not provide insight as to why features are assigned their attribution values, leading to explanations that are difficult to interpret. In real-world problems we often have sets of additional information for each feature that are predictive of that feature's importance to the task at hand. Here we propose the deep attribution prior (DAPr) framework to exploit such information to overcome the limitations of attribution methods. Our framework jointly learns a relationship between prior information and feature importance, as well as biases models to have explanations that rely on features predicted to be important. We find that our framework both results in networks that generalize better to out of sample data and admits new methods for interpreting model explanations.