 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms to estimate Shapley value feature attributions
Paper and Code
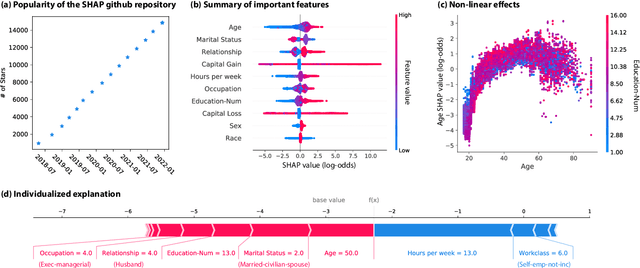
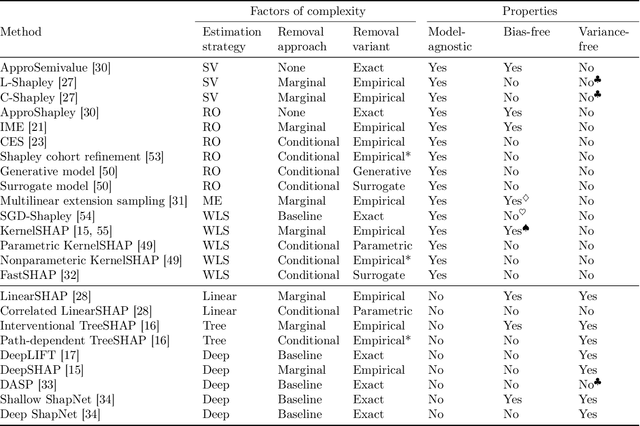
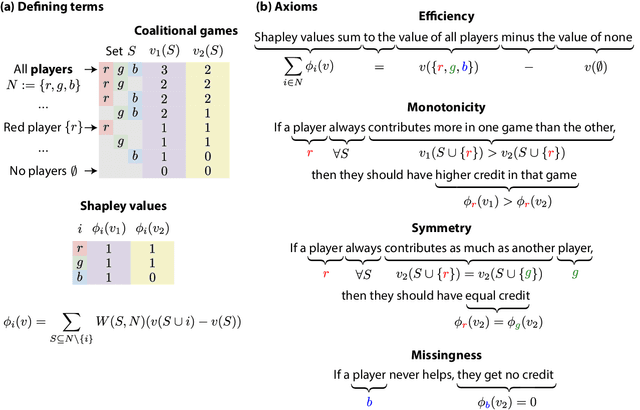
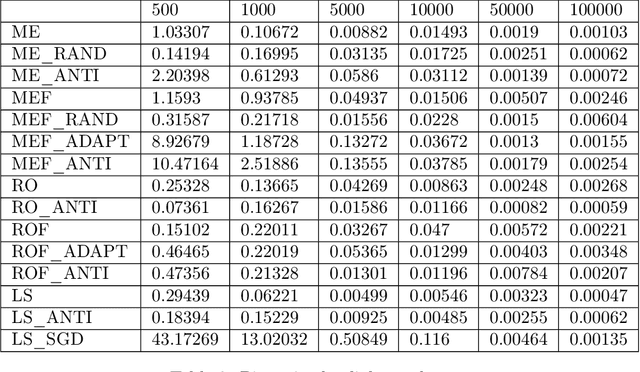
Feature attributions based on the Shapley value are popular for explaining machine learning models; however, their estimation is complex from both a theoretical and computational standpoint. We disentangle this complexity into two factors: (1)~the approach to removing feature information, and (2)~the tractable estimation strategy. These two factors provide a natural lens through which we can better understand and compare 24 distinct algorithms. Based on the various feature removal approaches, we describe the multiple types of Shapley value feature attributions and methods to calculate each one. Then, based on the tractable estimation strategies, we characterize two distinct families of approaches: model-agnostic and model-specific approximations. For the model-agnostic approximations, we benchmark a wide class of estimation approaches and tie them to alternative yet equivalent characterizations of the Shapley value. For the model-specific approximations, we clarify the assumptions crucial to each method's tractability for linear, tree, and deep models. Finally, we identify gaps in the literature and promising future research directions.