 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms to estimate Shapley value feature attributions
Jul 15, 2022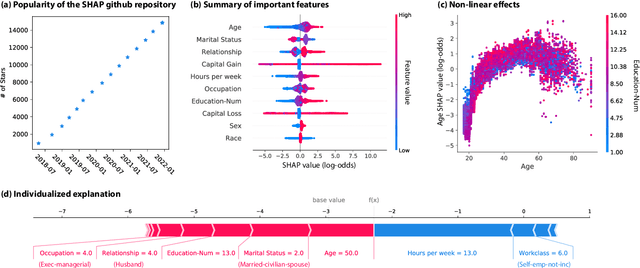
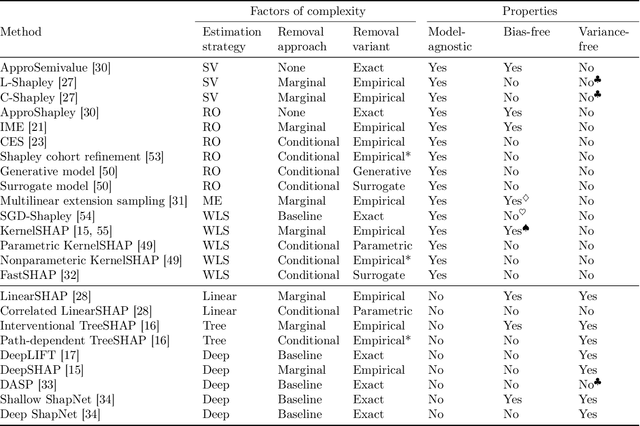
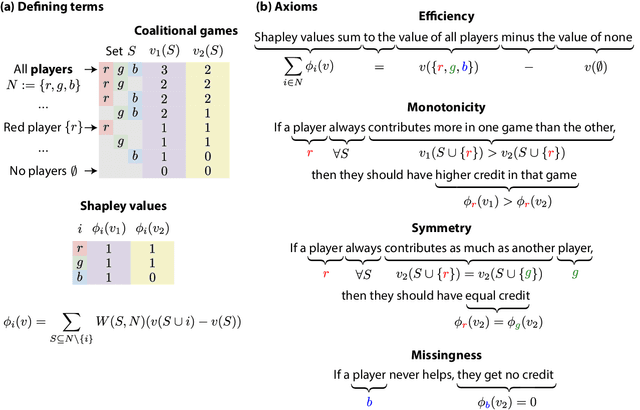
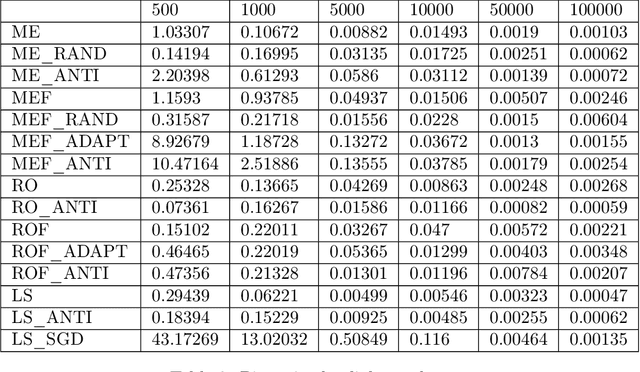
Feature attributions based on the Shapley value are popular for explaining machine learning models; however, their estimation is complex from both a theoretical and computational standpoint. We disentangle this complexity into two factors: (1)~the approach to removing feature information, and (2)~the tractable estimation strategy. These two factors provide a natural lens through which we can better understand and compare 24 distinct algorithms. Based on the various feature removal approaches, we describe the multiple types of Shapley value feature attributions and methods to calculate each one. Then, based on the tractable estimation strategies, we characterize two distinct families of approaches: model-agnostic and model-specific approximations. For the model-agnostic approximations, we benchmark a wide class of estimation approaches and tie them to alternative yet equivalent characterizations of the Shapley value. For the model-specific approximations, we clarify the assumptions crucial to each method's tractability for linear, tree, and deep models. Finally, we identify gaps in the literature and promising future research directions.
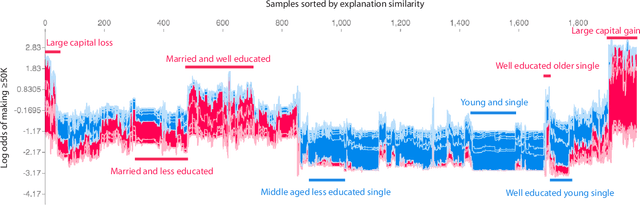
Explaining a Series of Models by Propagating Local Feature Attributions
Apr 30, 2021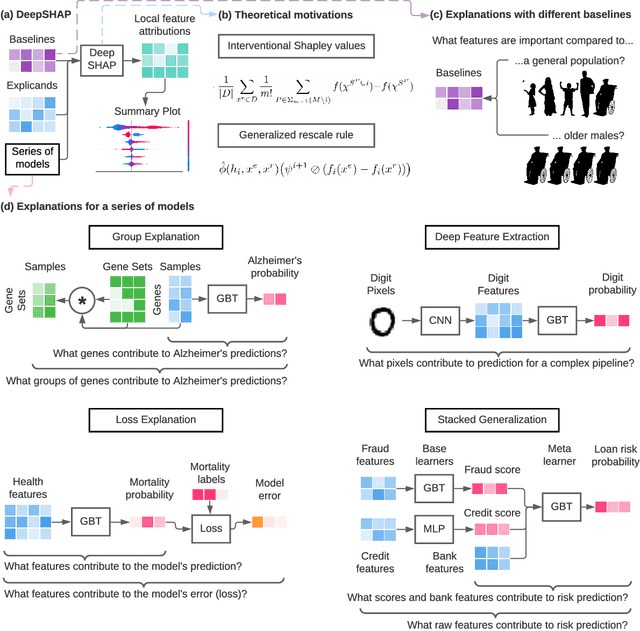

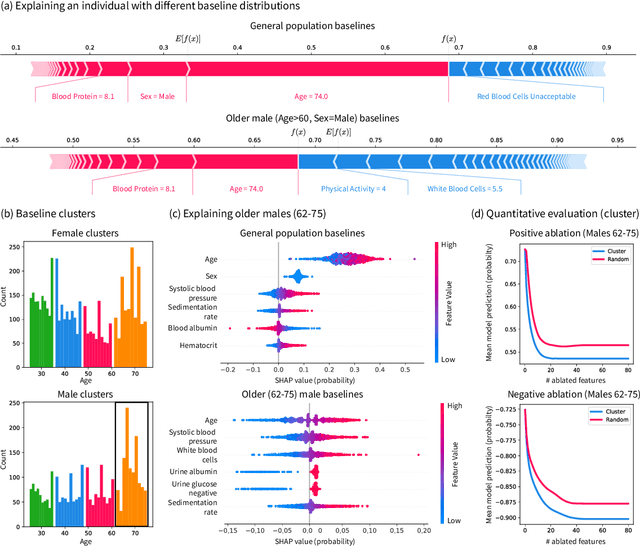
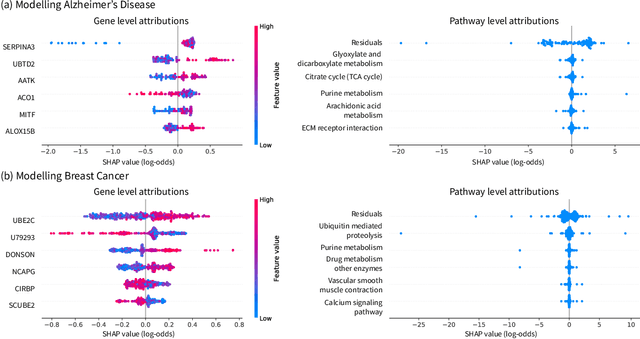
Pipelines involving a series of several machine learning models (e.g., stacked generalization ensembles, neural network feature extractors) improve performance in many domains but are difficult to understand. To improve their transparency, we introduce a framework to propagate local feature attributions through complex pipelines of models based on a connection to the Shapley value. Our framework enables us to (1) draw higher-level conclusions based on groups of gene expression features for Alzheimer's and breast cancer histologic grade prediction, (2) draw important insights about the errors a mortality prediction model makes by explaining a loss that is a non-linear transformation of the model's output, (3) explain pipelines of deep feature extractors fed into a tree model for MNIST digit classification, and (4) interpret important consumer scores and raw features in a stacked generalization setting to predict risk for home equity line of credit applications. Importantly, in the consumer scoring example, DeepSHAP is the only feature attribution technique we are aware of that allows independent entities (e.g., lending institutions, credit bureaus) to compute attributions for the original features without having to share their proprietary models. Quantitatively comparing our framework to model-agnostic approaches, we show that our approach is an order of magnitude faster while providing equally salient explanations. In addition, we describe how to incorporate an empirical baseline distribution, which allows us to (1) demonstrate the bias of previous approaches that use a single baseline sample, and (2) present a straightforward methodology for choosing meaningful baseline distributions.
Explainable AI for Trees: From Local Explanations to Global Understanding
May 11, 2019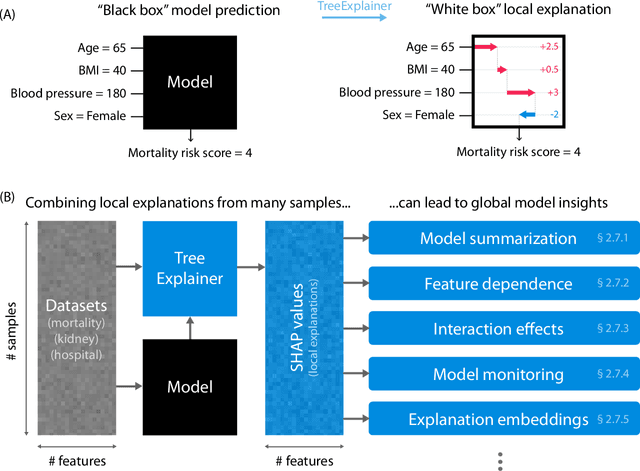
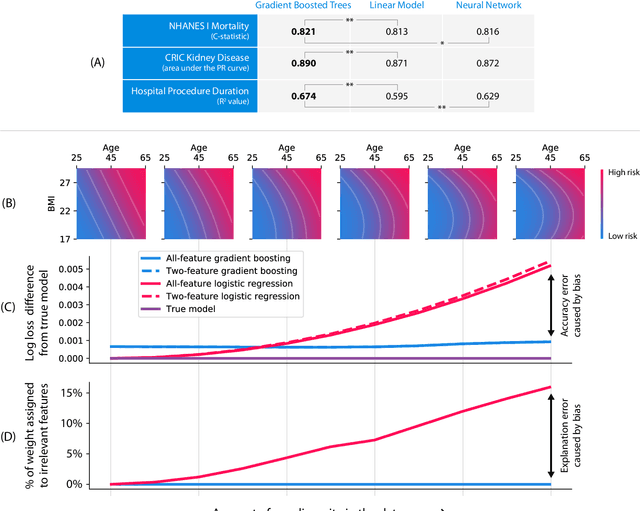
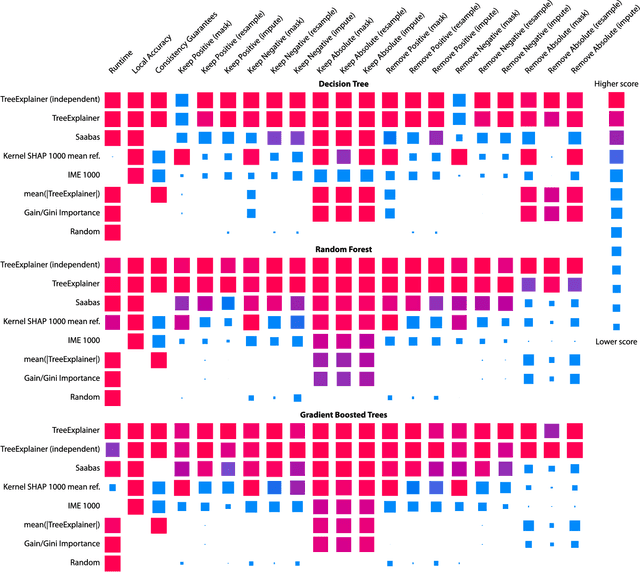
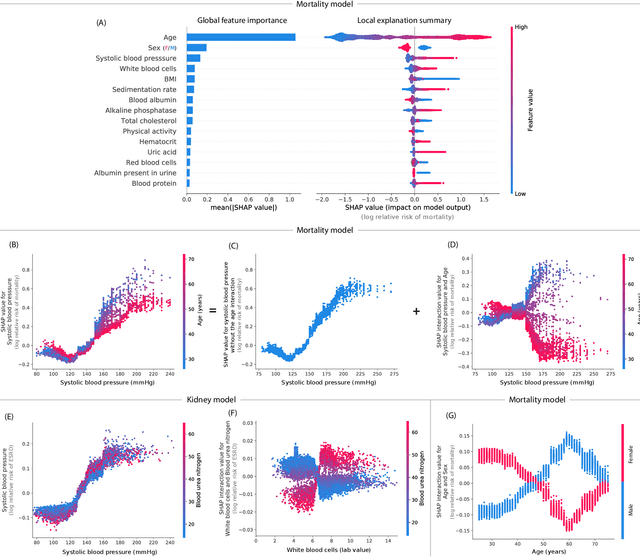
Tree-based machine learning models such as random forests, decision trees, and gradient boosted trees are the most popular non-linear predictive models used in practice today, yet comparatively little attention has been paid to explaining their predictions. Here we significantly improve the interpretability of tree-based models through three main contributions: 1) The first polynomial time algorithm to compute optimal explanations based on game theory. 2) A new type of explanation that directly measures local feature interaction effects. 3) A new set of tools for understanding global model structure based on combining many local explanations of each prediction. We apply these tools to three medical machine learning problems and show how combining many high-quality local explanations allows us to represent global structure while retaining local faithfulness to the original model. These tools enable us to i) identify high magnitude but low frequency non-linear mortality risk factors in the general US population, ii) highlight distinct population sub-groups with shared risk characteristics, iii) identify non-linear interaction effects among risk factors for chronic kidney disease, and iv) monitor a machine learning model deployed in a hospital by identifying which features are degrading the model's performance over time. Given the popularity of tree-based machine learning models, these improvements to their interpretability have implications across a broad set of domains.
Consistent Individualized Feature Attribution for Tree Ensembles
Jun 18, 2018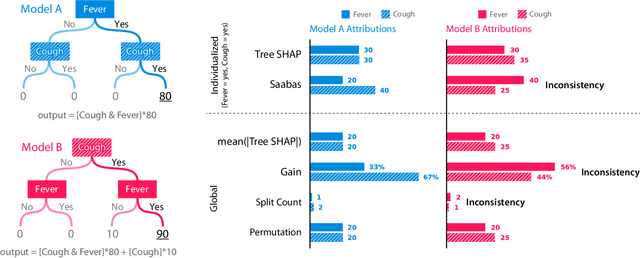


Interpreting predictions from tree ensemble methods such as gradient boosting machines and random forests is important, yet feature attribution for trees is often heuristic and not individualized for each prediction. Here we show that popular feature attribution methods are inconsistent, meaning they can lower a feature's assigned importance when the true impact of that feature actually increases. This is a fundamental problem that casts doubt on any comparison between features. To address it we turn to recent applications of game theory and develop fast exact tree solutions for SHAP (SHapley Additive exPlanation) values, which are the unique consistent and locally accurate attribution values. We then extend SHAP values to interaction effects and define SHAP interaction values. We propose a rich visualization of individualized feature attributions that improves over classic attribution summaries and partial dependence plots, and a unique "supervised" clustering (clustering based on feature attributions). We demonstrate better agreement with human intuition through a user study, exponential improvements in run time, improved clustering performance, and better identification of influential features. An implementation of our algorithm has also been merged into XGBoost and LightGBM, see http://github.com/slundberg/shap for details.
Consistent feature attribution for tree ensembles
Feb 17, 2018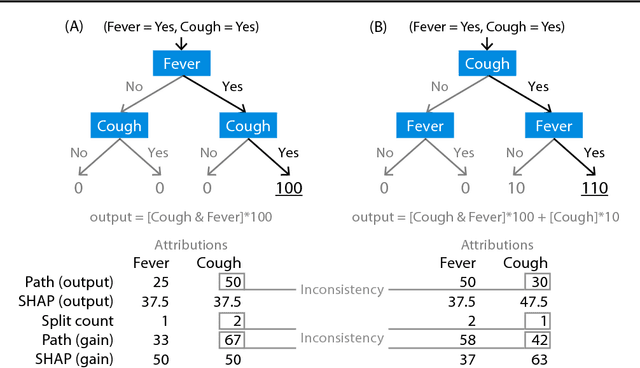



Note that a newer expanded version of this paper is now available at: arXiv:1802.03888 It is critical in many applications to understand what features are important for a model, and why individual predictions were made. For tree ensemble methods these questions are usually answered by attributing importance values to input features, either globally or for a single prediction. Here we show that current feature attribution methods are inconsistent, which means changing the model to rely more on a given feature can actually decrease the importance assigned to that feature. To address this problem we develop fast exact solutions for SHAP (SHapley Additive exPlanation) values, which were recently shown to be the unique additive feature attribution method based on conditional expectations that is both consistent and locally accurate. We integrate these improvements into the latest version of XGBoost, demonstrate the inconsistencies of current methods, and show how using SHAP values results in significantly improved supervised clustering performance. Feature importance values are a key part of understanding widely used models such as gradient boosting trees and random forests, so improvements to them have broad practical implications.
Anesthesiologist-level forecasting of hypoxemia with only SpO2 data using deep learning
Dec 02, 2017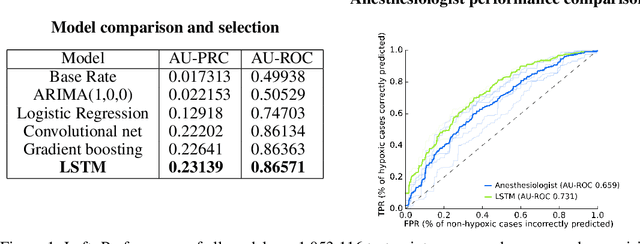
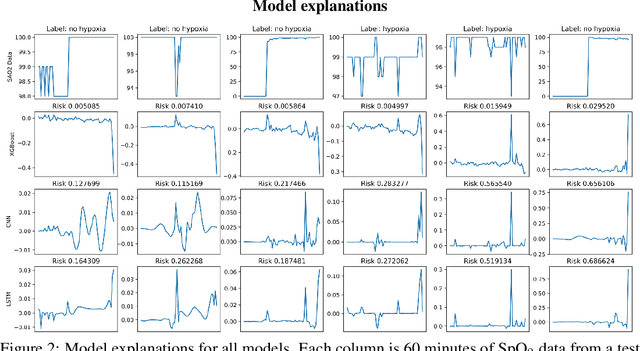
We use a deep learning model trained only on a patient's blood oxygenation data (measurable with an inexpensive fingertip sensor) to predict impending hypoxemia (low blood oxygen) more accurately than trained anesthesiologists with access to all the data recorded in a modern operating room. We also provide a simple way to visualize the reason why a patient's risk is low or high by assigning weight to the patient's past blood oxygen values. This work has the potential to provide cutting-edge clinical decision support in low-resource settings, where rates of surgical complication and death are substantially greater than in high-resource areas.