 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Guarantees for Fairness Aware Plug-In Algorithms
Jul 27, 2021
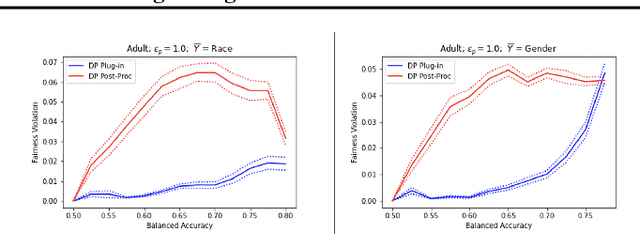

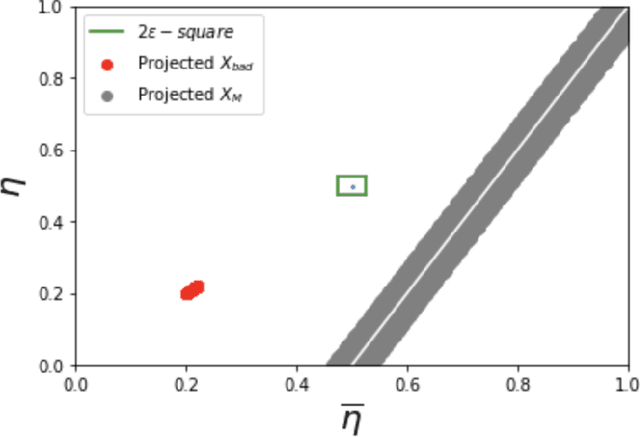
A plug-in algorithm to estimate Bayes Optimal Classifiers for fairness-aware binary classification has been proposed in (Menon & Williamson, 2018). However, the statistical efficacy of their approach has not been established. We prove that the plug-in algorithm is statistically consistent. We also derive finite sample guarantees associated with learning the Bayes Optimal Classifiers via the plug-in algorithm. Finally, we propose a protocol that modifies the plug-in approach, so as to simultaneously guarantee fairness and differential privacy with respect to a binary feature deemed sensitive.
Accurate and Intuitive Contextual Explanations using Linear Model Trees
Sep 11, 2020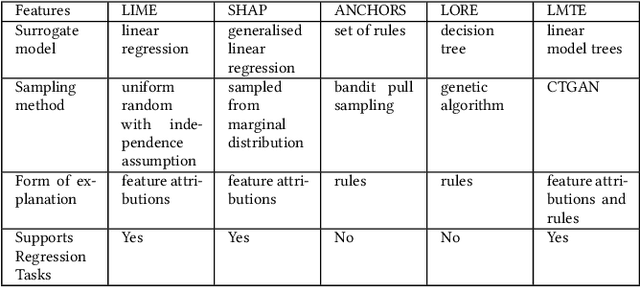
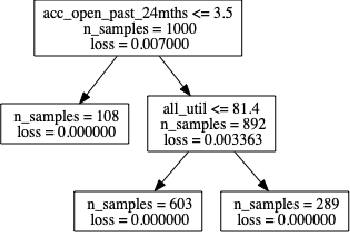
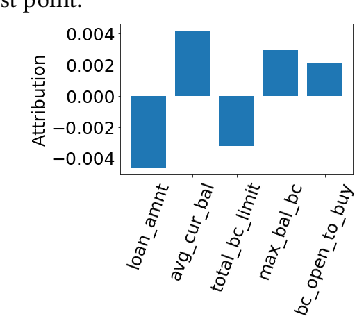

With the ever-increasing use of complex machine learning models in critical applications within the finance domain, explaining the decisions of the model has become a necessity. With applications spanning from credit scoring to credit marketing, the impact of these models is undeniable. Among the multiple ways in which one can explain the decisions of these complicated models, local post hoc model agnostic explanations have gained massive adoption. These methods allow one to explain each prediction independent of the modelling technique that was used while training. As explanations, they either give individual feature attributions or provide sufficient rules that represent conditions for a prediction to be made. The current state of the art methods use rudimentary methods to generate synthetic data around the point to be explained. This is followed by fitting simple linear models as surrogates to obtain a local interpretation of the prediction. In this paper, we seek to significantly improve on both, the method used to generate the explanations and the nature of explanations produced. We use a Generative Adversarial Network for synthetic data generation and train a piecewise linear model in the form of Linear Model Trees to be used as the surrogate model.In addition to individual feature attributions, we also provide an accompanying context to our explanations by leveraging the structure and property of our surrogate model.
FairXGBoost: Fairness-aware Classification in XGBoost
Sep 03, 2020
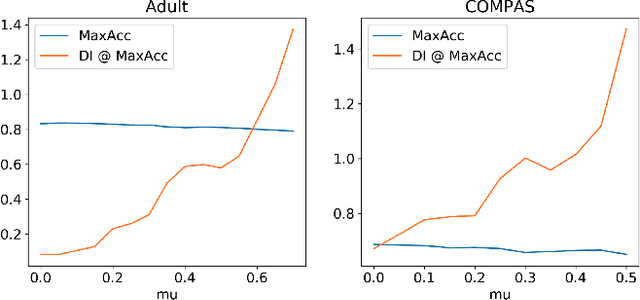

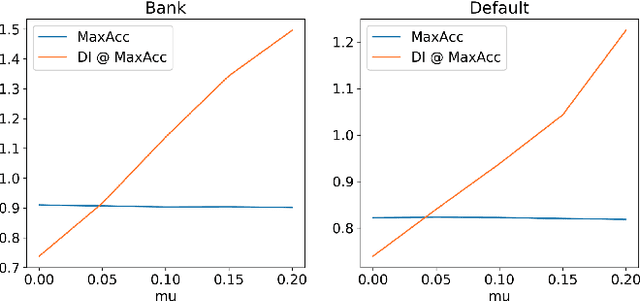
Highly regulated domains such as finance have long favoured the use of machine learning algorithms that are scalable, transparent, robust and yield better performance. One of the most prominent examples of such an algorithm is XGBoost. Meanwhile, there is also a growing interest in building fair and unbiased models in these regulated domains and numerous bias-mitigation algorithms have been proposed to this end. However, most of these bias-mitigation methods are restricted to specific model families such as logistic regression or support vector machine models, thus leaving modelers with a difficult decision of choosing between fairness from the bias-mitigation algorithms and scalability, transparency, performance from algorithms such as XGBoost. We aim to leverage the best of both worlds by proposing a fair variant of XGBoost that enjoys all the advantages of XGBoost, while also matching the levels of fairness from the state-of-the-art bias-mitigation algorithms. Furthermore, the proposed solution requires very little in terms of changes to the original XGBoost library, thus making it easy for adoption. We provide an empirical analysis of our proposed method on standard benchmark datasets used in the fairness community.