 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairXGBoost: Fairness-aware Classification in XGBoost
Paper and Code
Sep 03, 2020
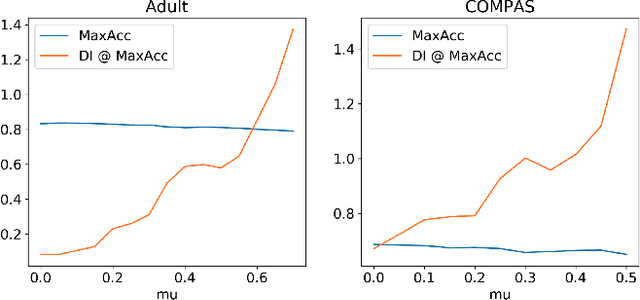

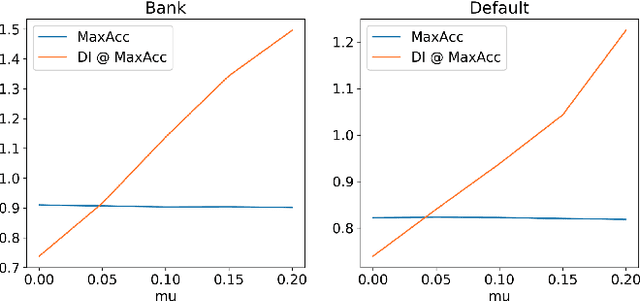
Highly regulated domains such as finance have long favoured the use of machine learning algorithms that are scalable, transparent, robust and yield better performance. One of the most prominent examples of such an algorithm is XGBoost. Meanwhile, there is also a growing interest in building fair and unbiased models in these regulated domains and numerous bias-mitigation algorithms have been proposed to this end. However, most of these bias-mitigation methods are restricted to specific model families such as logistic regression or support vector machine models, thus leaving modelers with a difficult decision of choosing between fairness from the bias-mitigation algorithms and scalability, transparency, performance from algorithms such as XGBoost. We aim to leverage the best of both worlds by proposing a fair variant of XGBoost that enjoys all the advantages of XGBoost, while also matching the levels of fairness from the state-of-the-art bias-mitigation algorithms. Furthermore, the proposed solution requires very little in terms of changes to the original XGBoost library, thus making it easy for adoption. We provide an empirical analysis of our proposed method on standard benchmark datasets used in the fairness community.