 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriva-ML: A Continuous FAIRness Approach to Reproducible Machine Learning Models
Paper and Code
Jun 27, 2024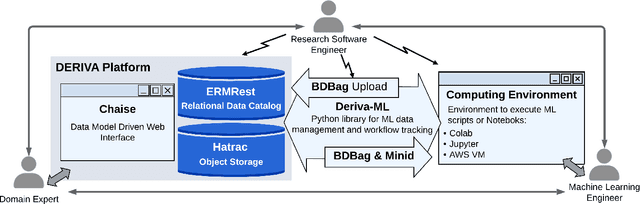
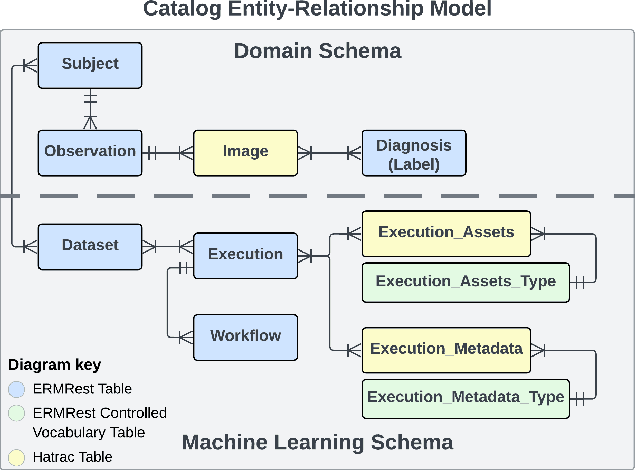
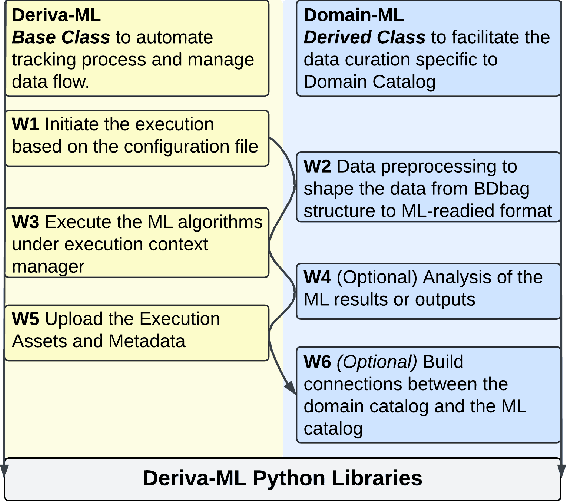
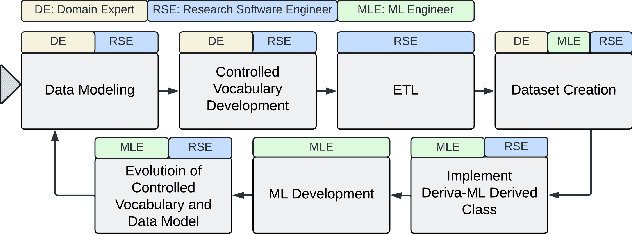
Increasingly, artificial intelligence (AI) and machine learning (ML) are used in eScience applications [9]. While these approaches have great potential, the literature has shown that ML-based approaches frequently suffer from results that are either incorrect or unreproducible due to mismanagement or misuse of data used for training and validating the models [12, 15]. Recognition of the necessity of high-quality data for correct ML results has led to data-centric ML approaches that shift the central focus from model development to creation of high-quality data sets to train and validate the models [14, 20]. However, there are limited tools and methods available for data-centric approaches to explore and evaluate ML solutions for eScience problems which often require collaborative multidisciplinary teams working with models and data that will rapidly evolve as an investigation unfolds [1]. In this paper, we show how data management tools based on the principle that all of the data for ML should be findable, accessible, interoperable and reusable (i.e. FAIR [26]) can significantly improve the quality of data that is used for ML applications. When combined with best practices that apply these tools to the entire life cycle of an ML-based eScience investigation, we can significantly improve the ability of an eScience team to create correct and reproducible ML solutions. We propose an architecture and implementation of such tools and demonstrate through two use cases how they can be used to improve ML-based eScience investigations.