 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Graph Matching Algorithms in Computer Vision
Jul 01, 2022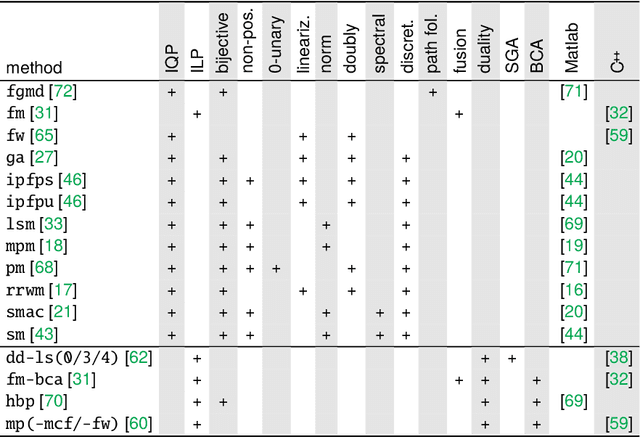
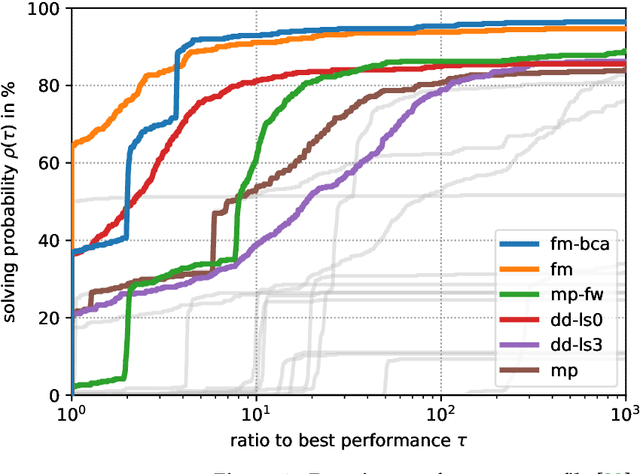
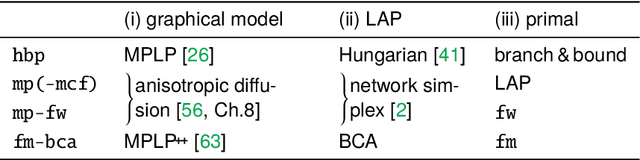
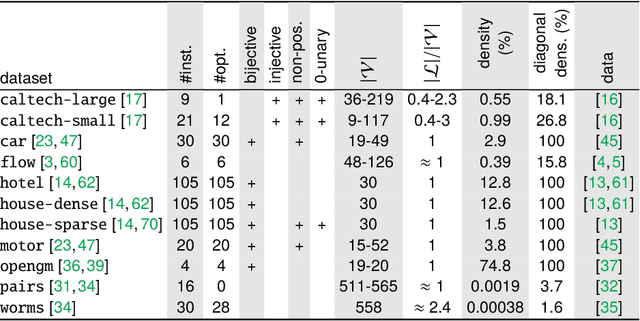
The graph matching optimization problem is an essential component for many tasks in computer vision, such as bringing two deformable objects in correspondence. Naturally, a wide range of applicable algorithms have been proposed in the last decades. Since a common standard benchmark has not been developed, their performance claims are often hard to verify as evaluation on differing problem instances and criteria make the results incomparable. To address these shortcomings, we present a comparative study of graph matching algorithms. We create a uniform benchmark where we collect and categorize a large set of existing and publicly available computer vision graph matching problems in a common format. At the same time we collect and categorize the most popular open-source implementations of graph matching algorithms. Their performance is evaluated in a way that is in line with the best practices for comparing optimization algorithms. The study is designed to be reproducible and extensible to serve as a valuable resource in the future. Our study provides three notable insights: 1.) popular problem instances are exactly solvable in substantially less than 1 second and, therefore, are insufficient for future empirical evaluations; 2.) the most popular baseline methods are highly inferior to the best available methods; 3.) despite the NP-hardness of the problem, instances coming from vision applications are often solvable in a few seconds even for graphs with more than 500 vertices.
Survey on Automated Short Answer Grading with Deep Learning: from Word Embeddings to Transformers
Mar 11, 2022
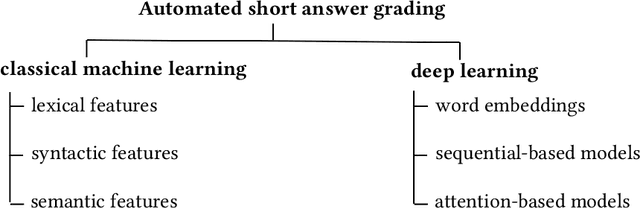
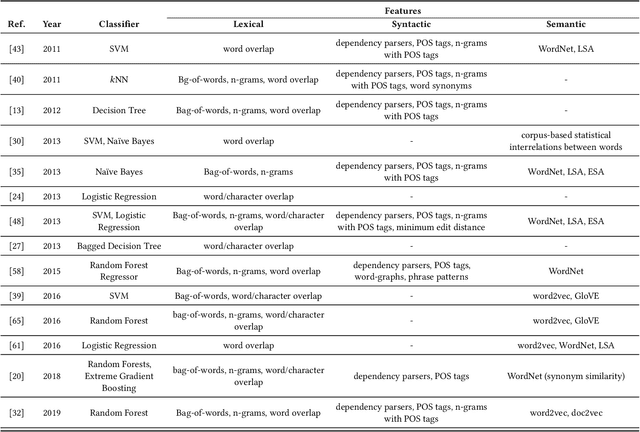

Automated short answer grading (ASAG) has gained attention in education as a means to scale educational tasks to the growing number of students. Recent progress in Natural Language Processing and Machine Learning has largely influenced the field of ASAG, of which we survey the recent research advancements. We complement previous surveys by providing a comprehensive analysis of recently published methods that deploy deep learning approaches. In particular, we focus our analysis on the transition from hand engineered features to representation learning approaches, which learn representative features for the task at hand automatically from large corpora of data. We structure our analysis of deep learning methods along three categories: word embeddings, sequential models, and attention-based methods. Deep learning impacted ASAG differently than other fields of NLP, as we noticed that the learned representations alone do not contribute to achieve the best results, but they rather show to work in a complementary way with hand-engineered features. The best performance are indeed achieved by methods that combine the carefully hand-engineered features with the power of the semantic descriptions provided by the latest models, like transformers architectures. We identify challenges and provide an outlook on research direction that can be addressed in the future
Fusion Moves for Graph Matching
Feb 05, 2021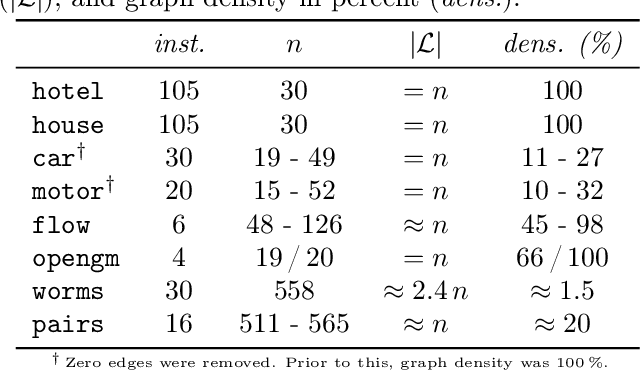
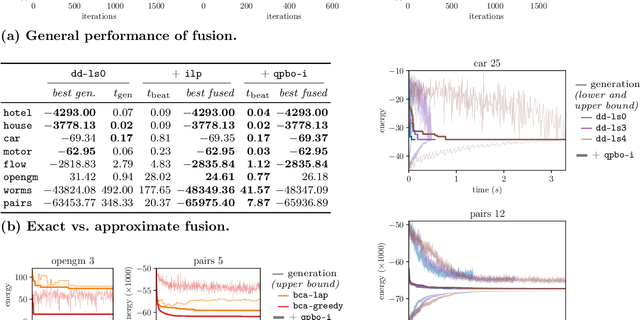
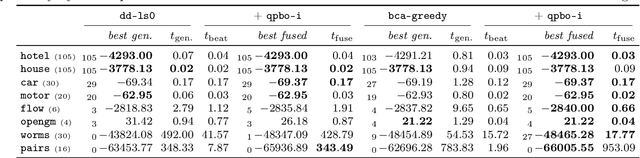

We contribute to approximate algorithms for the quadratic assignment problem also known as graph matching. Inspired by the success of the fusion moves technique developed for multilabel discrete Markov random fields, we investigate its applicability to graph matching. In particular, we show how it can be efficiently combined with the dedicated state-of-the-art Lagrange dual methods that have recently shown superior results in computer vision and bio-imaging applications. As our empirical evaluation on a wide variety of graph matching datasets suggests, fusion moves notably improve performance of these methods in terms of speed and quality of the obtained solutions. Hence, this combination results in a state-of-the-art solver for graph matching.
A Primal-Dual Solver for Large-Scale Tracking-by-Assignment
Apr 14, 2020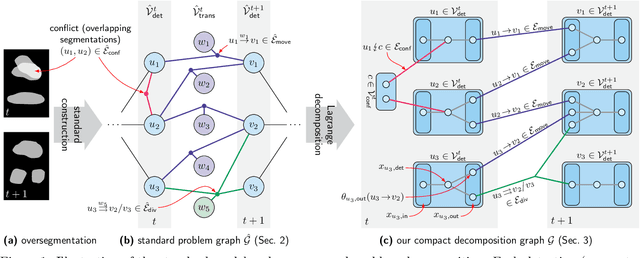
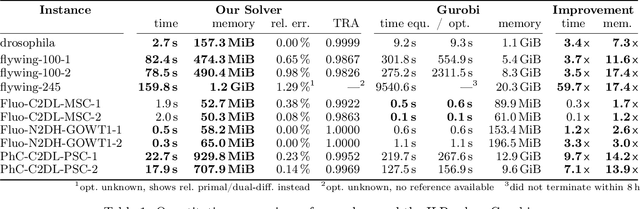
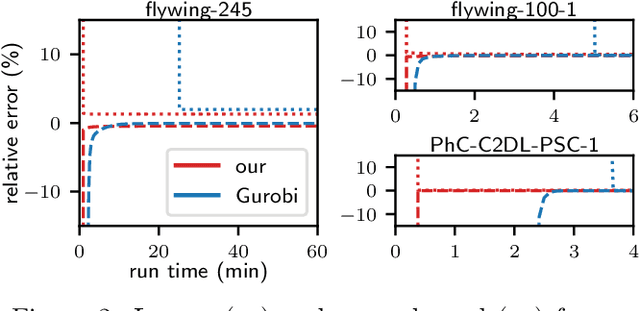
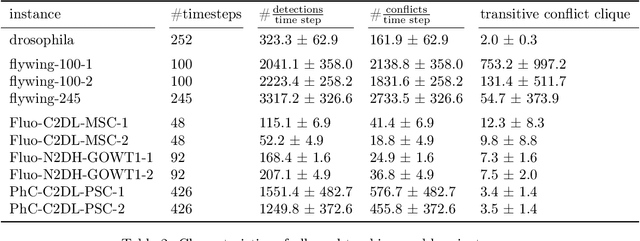
We propose a fast approximate solver for the combinatorial problem known as tracking-by-assignment, which we apply to cell tracking. The latter plays a key role in discovery in many life sciences, especially in cell and developmental biology. So far, in the most general setting this problem was addressed by off-the-shelf solvers like Gurobi, whose run time and memory requirements rapidly grow with the size of the input. In contrast, for our method this growth is nearly linear. Our contribution consists of a new (1) decomposable compact representation of the problem; (2) dual block-coordinate ascent method for optimizing the decomposition-based dual; and (3) primal heuristics that reconstructs a feasible integer solution based on the dual information. Compared to solving the problem with Gurobi, we observe an up to~60~times speed-up, while reducing the memory footprint significantly. We demonstrate the efficacy of our method on real-world tracking problems.
Exact MAP-Inference by Confining Combinatorial Search with LP Relaxation
Apr 14, 2020

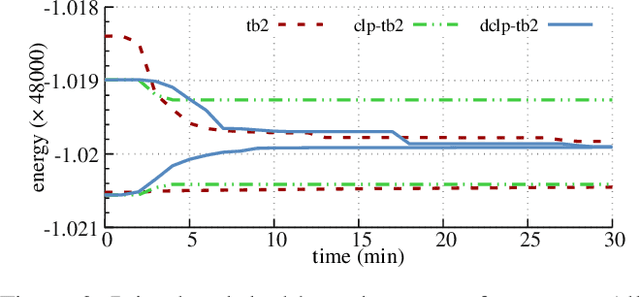
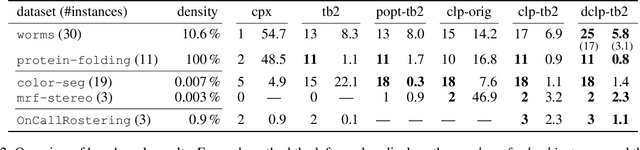
We consider the MAP-inference problem for graphical models, which is a valued constraint satisfaction problem defined on real numbers with a natural summation operation. We propose a family of relaxations (different from the famous Sherali-Adams hierarchy), which naturally define lower bounds for its optimum. This family always contains a tight relaxation and we give an algorithm able to find it and therefore, solve the initial non-relaxed NP-hard problem. The relaxations we consider decompose the original problem into two non-overlapping parts: an easy LP-tight part and a difficult one. For the latter part a combinatorial solver must be used. As we show in our experiments, in a number of applications the second, difficult part constitutes only a small fraction of the whole problem. This property allows to significantly reduce the computational time of the combinatorial solver and therefore solve problems which were out of reach before.