 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Painter: Training-Free Layout Control for Text-to-Image Synthesis
Jun 06, 2024



We present Zero-Painter, a novel training-free framework for layout-conditional text-to-image synthesis that facilitates the creation of detailed and controlled imagery from textual prompts. Our method utilizes object masks and individual descriptions, coupled with a global text prompt, to generate images with high fidelity. Zero-Painter employs a two-stage process involving our novel Prompt-Adjusted Cross-Attention (PACA) and Region-Grouped Cross-Attention (ReGCA) blocks, ensuring precise alignment of generated objects with textual prompts and mask shapes. Our extensive experiments demonstrate that Zero-Painter surpasses current state-of-the-art methods in preserving textual details and adhering to mask shapes.
Video Instance Matting
Nov 08, 2023Conventional video matting outputs one alpha matte for all instances appearing in a video frame so that individual instances are not distinguished. While video instance segmentation provides time-consistent instance masks, results are unsatisfactory for matting applications, especially due to applied binarization. To remedy this deficiency, we propose Video Instance Matting~(VIM), that is, estimating alpha mattes of each instance at each frame of a video sequence. To tackle this challenging problem, we present MSG-VIM, a Mask Sequence Guided Video Instance Matting neural network, as a novel baseline model for VIM. MSG-VIM leverages a mixture of mask augmentations to make predictions robust to inaccurate and inconsistent mask guidance. It incorporates temporal mask and temporal feature guidance to improve the temporal consistency of alpha matte predictions. Furthermore, we build a new benchmark for VIM, called VIM50, which comprises 50 video clips with multiple human instances as foreground objects. To evaluate performances on the VIM task, we introduce a suitable metric called Video Instance-aware Matting Quality~(VIMQ). Our proposed model MSG-VIM sets a strong baseline on the VIM50 benchmark and outperforms existing methods by a large margin. The project is open-sourced at https://github.com/SHI-Labs/VIM.
VMFormer: End-to-End Video Matting with Transformer
Aug 26, 2022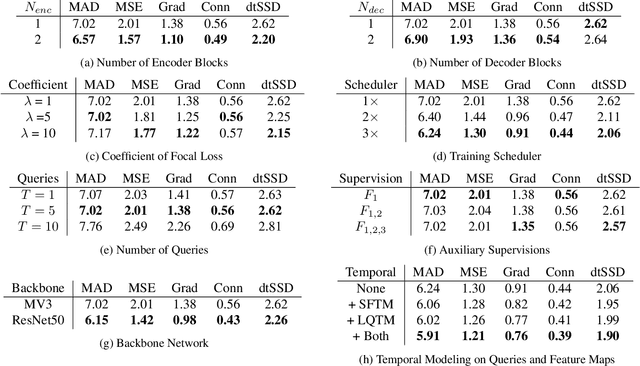
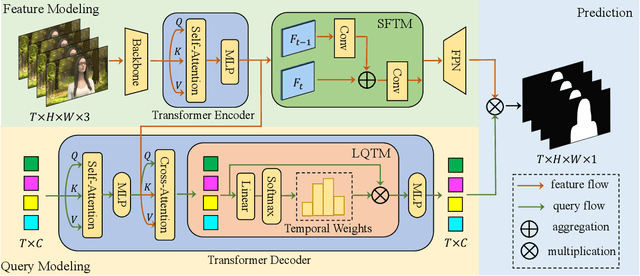

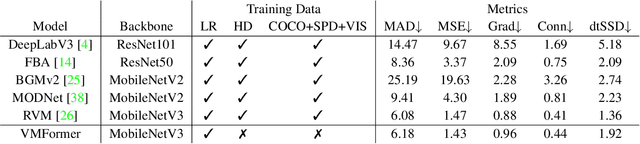
Video matting aims to predict the alpha mattes for each frame from a given input video sequence. Recent solutions to video matting have been dominated by deep convolutional neural networks (CNN) for the past few years, which have become the de-facto standard for both academia and industry. However, they have inbuilt inductive bias of locality and do not capture global characteristics of an image due to the CNN-based architectures. They also lack long-range temporal modeling considering computational costs when dealing with feature maps of multiple frames. In this paper, we propose VMFormer: a transformer-based end-to-end method for video matting. It makes predictions on alpha mattes of each frame from learnable queries given a video input sequence. Specifically, it leverages self-attention layers to build global integration of feature sequences with short-range temporal modeling on successive frames. We further apply queries to learn global representations through cross-attention in the transformer decoder with long-range temporal modeling upon all queries. In the prediction stage, both queries and corresponding feature maps are used to make the final prediction of alpha matte. Experiments show that VMFormer outperforms previous CNN-based video matting methods on the composited benchmarks. To our best knowledge, it is the first end-to-end video matting solution built upon a full vision transformer with predictions on the learnable queries. The project is open-sourced at https://chrisjuniorli.github.io/project/VMFormer/