 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Painter: Training-Free Layout Control for Text-to-Image Synthesis
Jun 06, 2024



We present Zero-Painter, a novel training-free framework for layout-conditional text-to-image synthesis that facilitates the creation of detailed and controlled imagery from textual prompts. Our method utilizes object masks and individual descriptions, coupled with a global text prompt, to generate images with high fidelity. Zero-Painter employs a two-stage process involving our novel Prompt-Adjusted Cross-Attention (PACA) and Region-Grouped Cross-Attention (ReGCA) blocks, ensuring precise alignment of generated objects with textual prompts and mask shapes. Our extensive experiments demonstrate that Zero-Painter surpasses current state-of-the-art methods in preserving textual details and adhering to mask shapes.
Dr-SAM: An End-to-End Framework for Vascular Segmentation, Diameter Estimation, and Anomaly Detection on Angiography Images
Apr 25, 2024Recent advancements in AI have significantly transformed medical imaging, particularly in angiography, by enhancing diagnostic precision and patient care. However existing works are limited in analyzing the aorta and iliac arteries, above all for vascular anomaly detection and characterization. To close this gap, we propose Dr-SAM, a comprehensive multi-stage framework for vessel segmentation, diameter estimation, and anomaly analysis aiming to examine the peripheral vessels through angiography images. For segmentation we introduce a customized positive/negative point selection mechanism applied on top of the Segment Anything Model (SAM), specifically for medical (Angiography) images. Then we propose a morphological approach to determine the vessel diameters followed by our histogram-driven anomaly detection approach. Moreover, we introduce a new benchmark dataset for the comprehensive analysis of peripheral vessel angiography images which we hope can boost the upcoming research in this direction leading to enhanced diagnostic precision and ultimately better health outcomes for individuals facing vascular issues.
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
Mar 21, 2024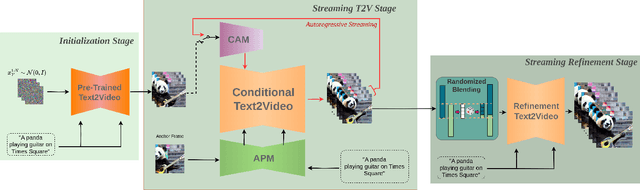
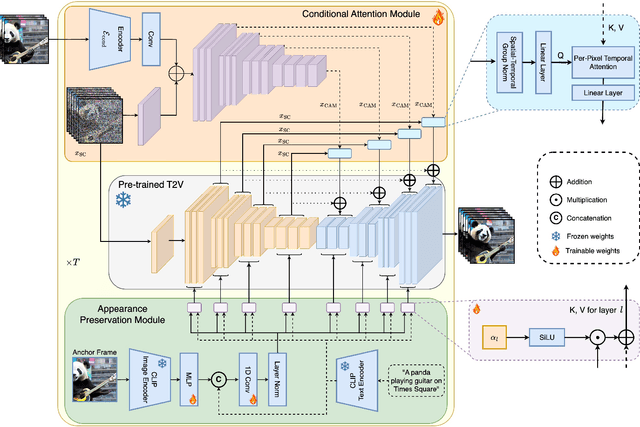


Text-to-video diffusion models enable the generation of high-quality videos that follow text instructions, making it easy to create diverse and individual content. However, existing approaches mostly focus on high-quality short video generation (typically 16 or 24 frames), ending up with hard-cuts when naively extended to the case of long video synthesis. To overcome these limitations, we introduce StreamingT2V, an autoregressive approach for long video generation of 80, 240, 600, 1200 or more frames with smooth transitions. The key components are:(i) a short-term memory block called conditional attention module (CAM), which conditions the current generation on the features extracted from the previous chunk via an attentional mechanism, leading to consistent chunk transitions, (ii) a long-term memory block called appearance preservation module, which extracts high-level scene and object features from the first video chunk to prevent the model from forgetting the initial scene, and (iii) a randomized blending approach that enables to apply a video enhancer autoregressively for infinitely long videos without inconsistencies between chunks. Experiments show that StreamingT2V generates high motion amount. In contrast, all competing image-to-video methods are prone to video stagnation when applied naively in an autoregressive manner. Thus, we propose with StreamingT2V a high-quality seamless text-to-long video generator that outperforms competitors with consistency and motion. Our code will be available at: https://github.com/Picsart-AI-Research/StreamingT2V
HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models
Dec 25, 2023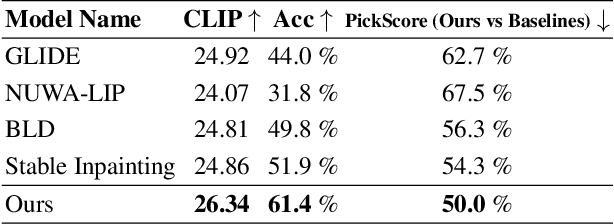
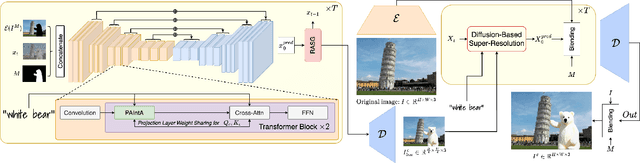
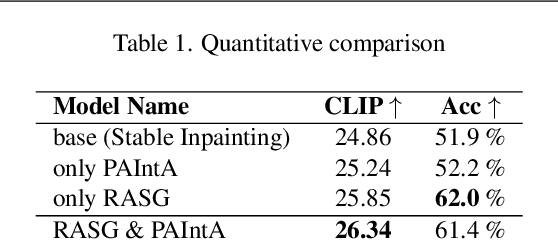
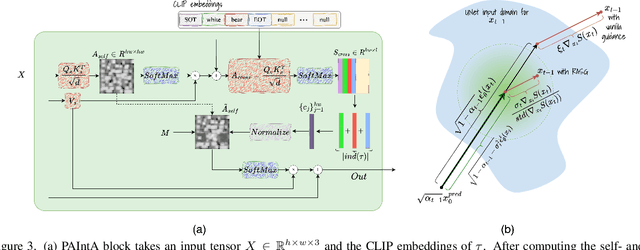
Recent progress in text-guided image inpainting, based on the unprecedented success of text-to-image diffusion models, has led to exceptionally realistic and visually plausible results. However, there is still significant potential for improvement in current text-to-image inpainting models, particularly in better aligning the inpainted area with user prompts and performing high-resolution inpainting. Therefore, in this paper we introduce HD-Painter, a completely training-free approach that accurately follows to prompts and coherently scales to high-resolution image inpainting. To this end, we design the Prompt-Aware Introverted Attention (PAIntA) layer enhancing self-attention scores by prompt information and resulting in better text alignment generations. To further improve the prompt coherence we introduce the Reweighting Attention Score Guidance (RASG) mechanism seamlessly integrating a post-hoc sampling strategy into general form of DDIM to prevent out-of-distribution latent shifts. Moreover, HD-Painter allows extension to larger scales by introducing a specialized super-resolution technique customized for inpainting, enabling the completion of missing regions in images of up to 2K resolution. Our experiments demonstrate that HD-Painter surpasses existing state-of-the-art approaches qualitatively and quantitatively, achieving an impressive generation accuracy improvement of 61.4% vs 51.9%. We will make the codes publicly available at: https://github.com/Picsart-AI-Research/HD-Painter
Video Instance Matting
Nov 08, 2023Conventional video matting outputs one alpha matte for all instances appearing in a video frame so that individual instances are not distinguished. While video instance segmentation provides time-consistent instance masks, results are unsatisfactory for matting applications, especially due to applied binarization. To remedy this deficiency, we propose Video Instance Matting~(VIM), that is, estimating alpha mattes of each instance at each frame of a video sequence. To tackle this challenging problem, we present MSG-VIM, a Mask Sequence Guided Video Instance Matting neural network, as a novel baseline model for VIM. MSG-VIM leverages a mixture of mask augmentations to make predictions robust to inaccurate and inconsistent mask guidance. It incorporates temporal mask and temporal feature guidance to improve the temporal consistency of alpha matte predictions. Furthermore, we build a new benchmark for VIM, called VIM50, which comprises 50 video clips with multiple human instances as foreground objects. To evaluate performances on the VIM task, we introduce a suitable metric called Video Instance-aware Matting Quality~(VIMQ). Our proposed model MSG-VIM sets a strong baseline on the VIM50 benchmark and outperforms existing methods by a large margin. The project is open-sourced at https://github.com/SHI-Labs/VIM.
Multi-Concept T2I-Zero: Tweaking Only The Text Embeddings and Nothing Else
Oct 11, 2023



Recent advances in text-to-image diffusion models have enabled the photorealistic generation of images from text prompts. Despite the great progress, existing models still struggle to generate compositional multi-concept images naturally, limiting their ability to visualize human imagination. While several recent works have attempted to address this issue, they either introduce additional training or adopt guidance at inference time. In this work, we consider a more ambitious goal: natural multi-concept generation using a pre-trained diffusion model, and with almost no extra cost. To achieve this goal, we identify the limitations in the text embeddings used for the pre-trained text-to-image diffusion models. Specifically, we observe concept dominance and non-localized contribution that severely degrade multi-concept generation performance. We further design a minimal low-cost solution that overcomes the above issues by tweaking (not re-training) the text embeddings for more realistic multi-concept text-to-image generation. Our Correction by Similarities method tweaks the embedding of concepts by collecting semantic features from most similar tokens to localize the contribution. To avoid mixing features of concepts, we also apply Cross-Token Non-Maximum Suppression, which excludes the overlap of contributions from different concepts. Experiments show that our approach outperforms previous methods in text-to-image, image manipulation, and personalization tasks, despite not introducing additional training or inference costs to the diffusion steps.
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
Mar 23, 2023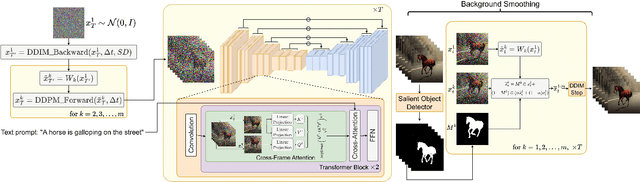

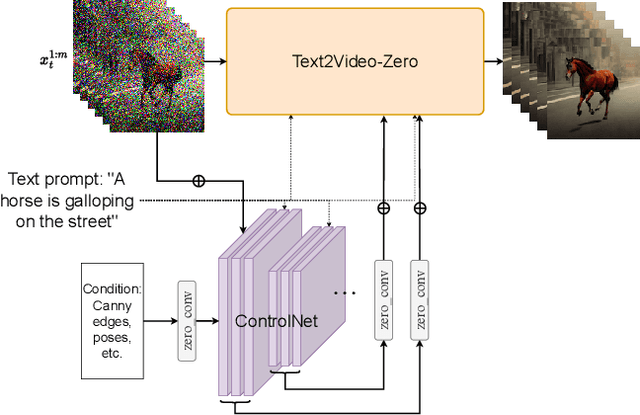

Recent text-to-video generation approaches rely on computationally heavy training and require large-scale video datasets. In this paper, we introduce a new task of zero-shot text-to-video generation and propose a low-cost approach (without any training or optimization) by leveraging the power of existing text-to-image synthesis methods (e.g., Stable Diffusion), making them suitable for the video domain. Our key modifications include (i) enriching the latent codes of the generated frames with motion dynamics to keep the global scene and the background time consistent; and (ii) reprogramming frame-level self-attention using a new cross-frame attention of each frame on the first frame, to preserve the context, appearance, and identity of the foreground object. Experiments show that this leads to low overhead, yet high-quality and remarkably consistent video generation. Moreover, our approach is not limited to text-to-video synthesis but is also applicable to other tasks such as conditional and content-specialized video generation, and Video Instruct-Pix2Pix, i.e., instruction-guided video editing. As experiments show, our method performs comparably or sometimes better than recent approaches, despite not being trained on additional video data. Our code will be open sourced at: https://github.com/Picsart-AI-Research/Text2Video-Zero .
Image Completion with Heterogeneously Filtered Spectral Hints
Nov 07, 2022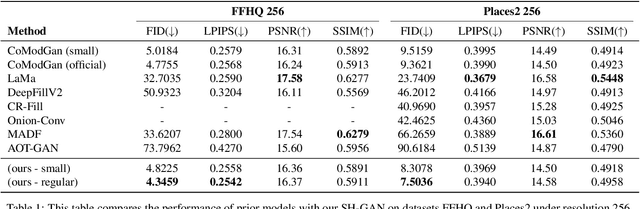
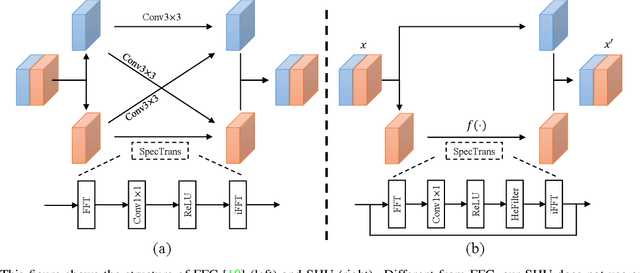
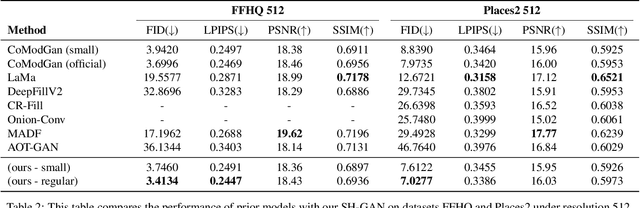
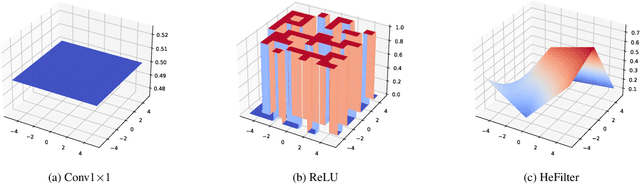
Image completion with large-scale free-form missing regions is one of the most challenging tasks for the computer vision community. While researchers pursue better solutions, drawbacks such as pattern unawareness, blurry textures, and structure distortion remain noticeable, and thus leave space for improvement. To overcome these challenges, we propose a new StyleGAN-based image completion network, Spectral Hint GAN (SH-GAN), inside which a carefully designed spectral processing module, Spectral Hint Unit, is introduced. We also propose two novel 2D spectral processing strategies, Heterogeneous Filtering and Gaussian Split that well-fit modern deep learning models and may further be extended to other tasks. From our inclusive experiments, we demonstrate that our model can reach FID scores of 3.4134 and 7.0277 on the benchmark datasets FFHQ and Places2, and therefore outperforms prior works and reaches a new state-of-the-art. We also prove the effectiveness of our design via ablation studies, from which one may notice that the aforementioned challenges, i.e. pattern unawareness, blurry textures, and structure distortion, can be noticeably resolved. Our code will be open-sourced at: https://github.com/SHI-Labs/SH-GAN.
VMFormer: End-to-End Video Matting with Transformer
Aug 26, 2022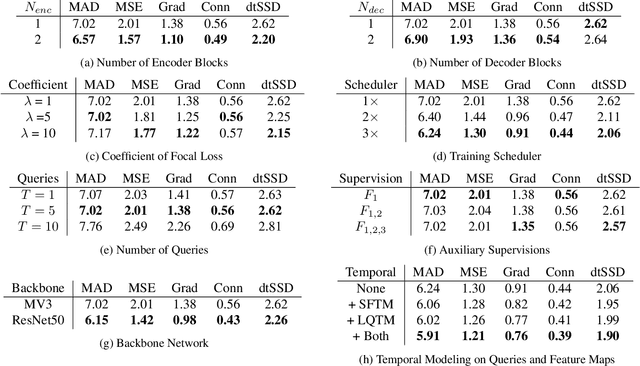
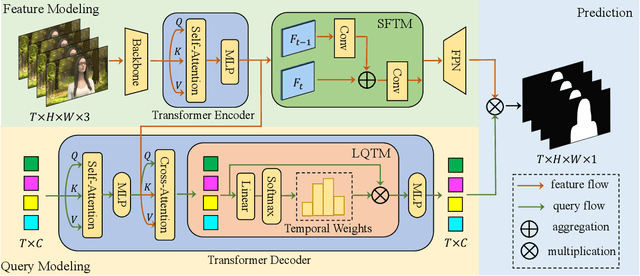

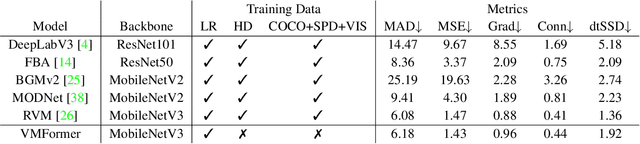
Video matting aims to predict the alpha mattes for each frame from a given input video sequence. Recent solutions to video matting have been dominated by deep convolutional neural networks (CNN) for the past few years, which have become the de-facto standard for both academia and industry. However, they have inbuilt inductive bias of locality and do not capture global characteristics of an image due to the CNN-based architectures. They also lack long-range temporal modeling considering computational costs when dealing with feature maps of multiple frames. In this paper, we propose VMFormer: a transformer-based end-to-end method for video matting. It makes predictions on alpha mattes of each frame from learnable queries given a video input sequence. Specifically, it leverages self-attention layers to build global integration of feature sequences with short-range temporal modeling on successive frames. We further apply queries to learn global representations through cross-attention in the transformer decoder with long-range temporal modeling upon all queries. In the prediction stage, both queries and corresponding feature maps are used to make the final prediction of alpha matte. Experiments show that VMFormer outperforms previous CNN-based video matting methods on the composited benchmarks. To our best knowledge, it is the first end-to-end video matting solution built upon a full vision transformer with predictions on the learnable queries. The project is open-sourced at https://chrisjuniorli.github.io/project/VMFormer/