 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Formulation for Non-Rectangular Lp Robust Markov Decision Processes
Feb 13, 2025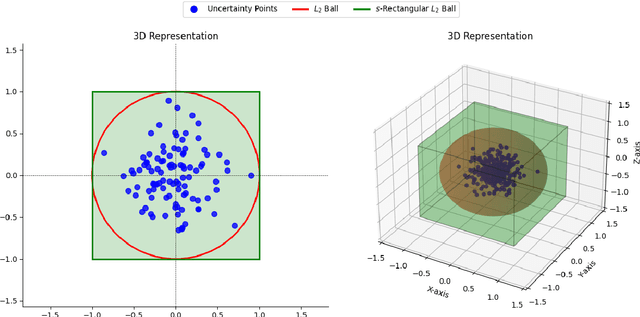

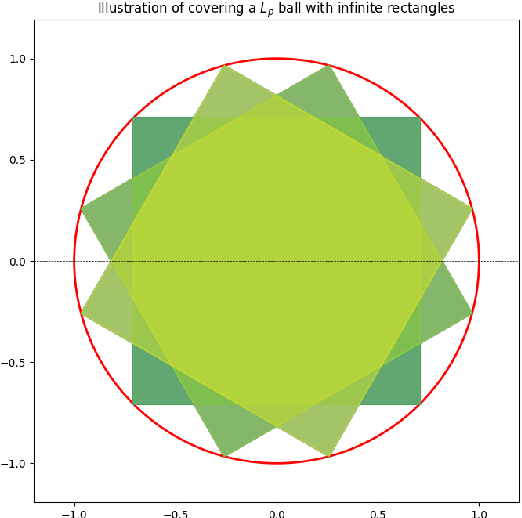

We study robust Markov decision processes (RMDPs) with non-rectangular uncertainty sets, which capture interdependencies across states unlike traditional rectangular models. While non-rectangular robust policy evaluation is generally NP-hard, even in approximation, we identify a powerful class of $L_p$-bounded uncertainty sets that avoid these complexity barriers due to their structural simplicity. We further show that this class can be decomposed into infinitely many \texttt{sa}-rectangular $L_p$-bounded sets and leverage its structural properties to derive a novel dual formulation for $L_p$ RMDPs. This formulation provides key insights into the adversary's strategy and enables the development of the first robust policy evaluation algorithms for non-rectangular RMDPs. Empirical results demonstrate that our approach significantly outperforms brute-force methods, establishing a promising foundation for future investigation into non-rectangular robust MDPs.
Solving Non-Rectangular Reward-Robust MDPs via Frequency Regularization
Sep 03, 2023In robust Markov decision processes (RMDPs), it is assumed that the reward and the transition dynamics lie in a given uncertainty set. By targeting maximal return under the most adversarial model from that set, RMDPs address performance sensitivity to misspecified environments. Yet, to preserve computational tractability, the uncertainty set is traditionally independently structured for each state. This so-called rectangularity condition is solely motivated by computational concerns. As a result, it lacks a practical incentive and may lead to overly conservative behavior. In this work, we study coupled reward RMDPs where the transition kernel is fixed, but the reward function lies within an $\alpha$-radius from a nominal one. We draw a direct connection between this type of non-rectangular reward-RMDPs and applying policy visitation frequency regularization. We introduce a policy-gradient method, and prove its convergence. Numerical experiments illustrate the learned policy's robustness and its less conservative behavior when compared to rectangular uncertainty.