 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeevoML Yellow Paper: Evolutionary AI and Optimisation Studio
Dec 20, 2022
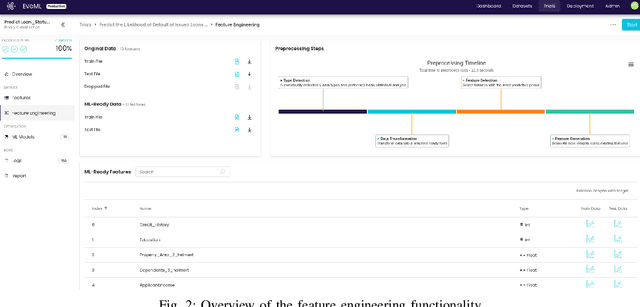
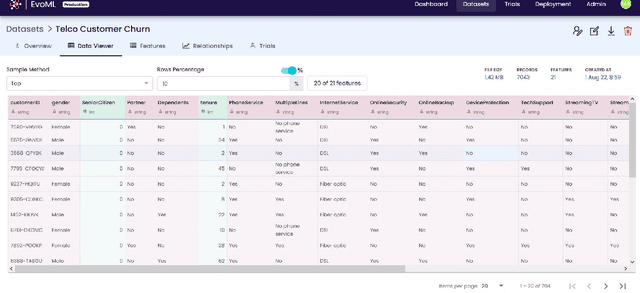
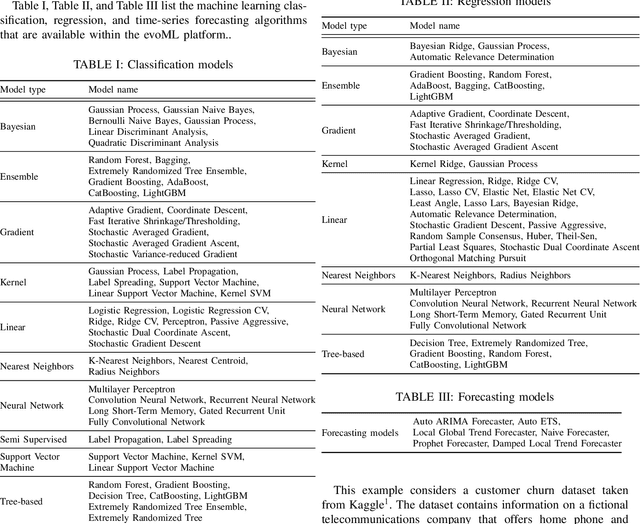
Machine learning model development and optimisation can be a rather cumbersome and resource-intensive process. Custom models are often more difficult to build and deploy, and they require infrastructure and expertise which are often costly to acquire and maintain. Machine learning product development lifecycle must take into account the need to navigate the difficulties of developing and deploying machine learning models. evoML is an AI-powered tool that provides automated functionalities in machine learning model development, optimisation, and model code optimisation. Core functionalities of evoML include data cleaning, exploratory analysis, feature analysis and generation, model optimisation, model evaluation, model code optimisation, and model deployment. Additionally, a key feature of evoML is that it embeds code and model optimisation into the model development process, and includes multi-objective optimisation capabilities.
Inducing Cooperation via Team Regret Minimization based Multi-Agent Deep Reinforcement Learning
Nov 18, 2019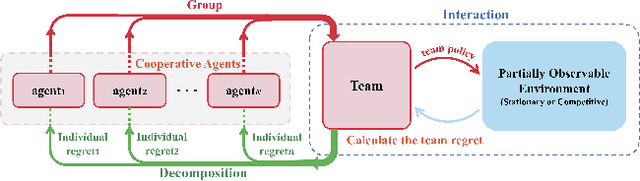
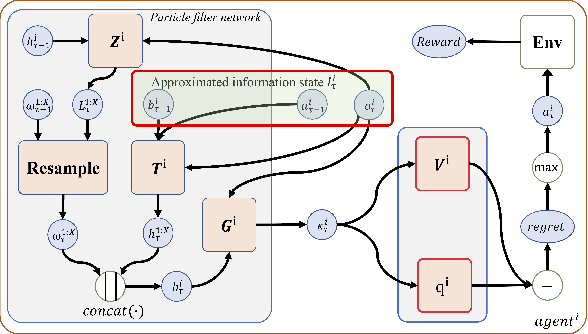
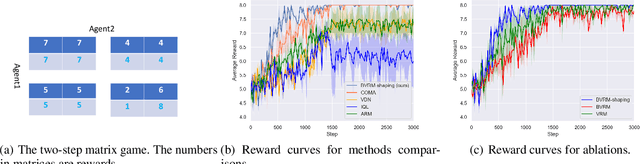
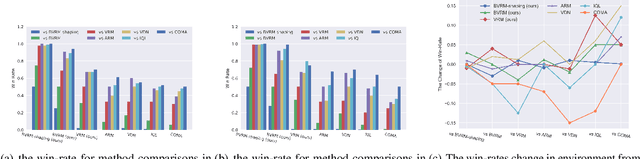
Existing value-factorized based Multi-Agent deep Reinforce-ment Learning (MARL) approaches are well-performing invarious multi-agent cooperative environment under thecen-tralized training and decentralized execution(CTDE) scheme,where all agents are trained together by the centralized valuenetwork and each agent execute its policy independently. How-ever, an issue remains open: in the centralized training process,when the environment for the team is partially observable ornon-stationary, i.e., the observation and action informationof all the agents cannot represent the global states, existingmethods perform poorly and sample inefficiently. Regret Min-imization (RM) can be a promising approach as it performswell in partially observable and fully competitive settings.However, it tends to model others as opponents and thus can-not work well under the CTDE scheme. In this work, wepropose a novel team RM based Bayesian MARL with threekey contributions: (a) we design a novel RM method to traincooperative agents as a team and obtain a team regret-basedpolicy for that team; (b) we introduce a novel method to de-compose the team regret to generate the policy for each agentfor decentralized execution; (c) to further improve the perfor-mance, we leverage a differential particle filter (a SequentialMonte Carlo method) network to get an accurate estimation ofthe state for each agent. Experimental results on two-step ma-trix games (cooperative game) and battle games (large-scalemixed cooperative-competitive games) demonstrate that ouralgorithm significantly outperforms state-of-the-art methods.