 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Collaborate in Multi-Module Recommendation via Multi-Agent Reinforcement Learning without Communication
Aug 29, 2020
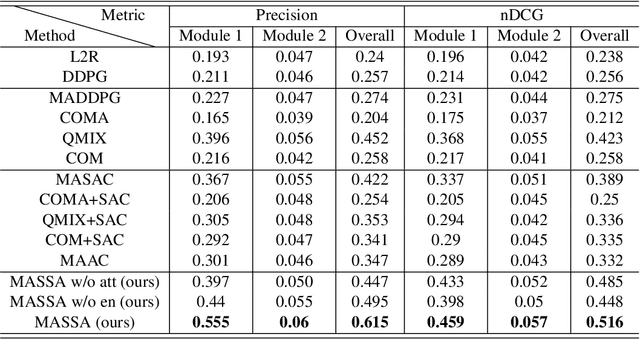
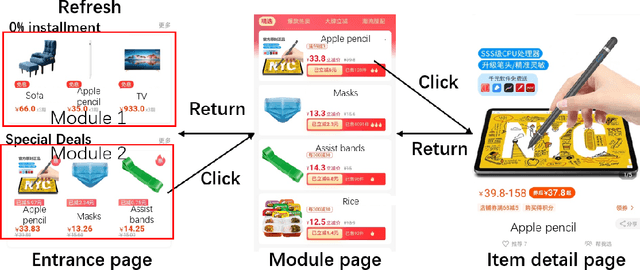
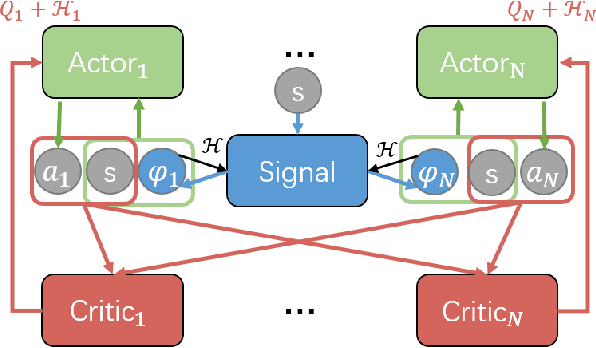
With the rise of online e-commerce platforms, more and more customers prefer to shop online. To sell more products, online platforms introduce various modules to recommend items with different properties such as huge discounts. A web page often consists of different independent modules. The ranking policies of these modules are decided by different teams and optimized individually without cooperation, which might result in competition between modules. Thus, the global policy of the whole page could be sub-optimal. In this paper, we propose a novel multi-agent cooperative reinforcement learning approach with the restriction that different modules cannot communicate. Our contributions are three-fold. Firstly, inspired by a solution concept in game theory named correlated equilibrium, we design a signal network to promote cooperation of all modules by generating signals (vectors) for different modules. Secondly, an entropy-regularized version of the signal network is proposed to coordinate agents' exploration of the optimal global policy. Furthermore, experiments based on real-world e-commerce data demonstrate that our algorithm obtains superior performance over baselines.
Contextual User Browsing Bandits for Large-Scale Online Mobile Recommendation
Aug 21, 2020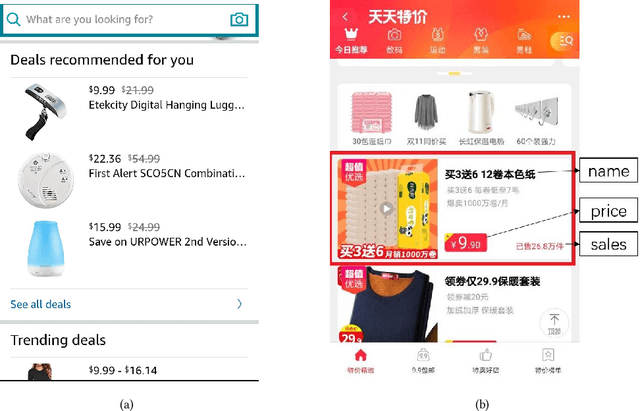
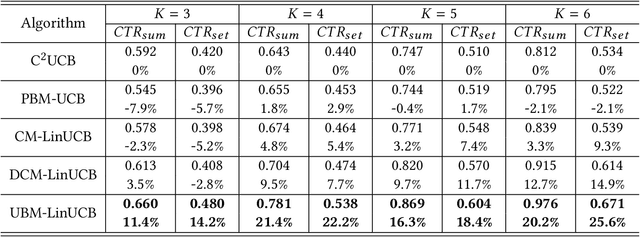
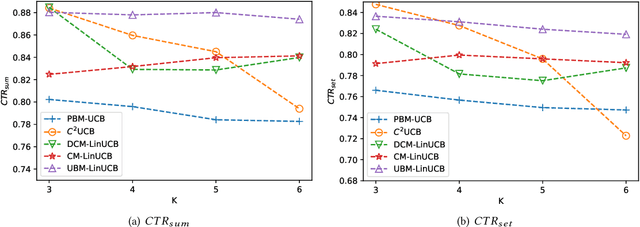
Online recommendation services recommend multiple commodities to users. Nowadays, a considerable proportion of users visit e-commerce platforms by mobile devices. Due to the limited screen size of mobile devices, positions of items have a significant influence on clicks: 1) Higher positions lead to more clicks for one commodity. 2) The 'pseudo-exposure' issue: Only a few recommended items are shown at first glance and users need to slide the screen to browse other items. Therefore, some recommended items ranked behind are not viewed by users and it is not proper to treat this kind of items as negative samples. While many works model the online recommendation as contextual bandit problems, they rarely take the influence of positions into consideration and thus the estimation of the reward function may be biased. In this paper, we aim at addressing these two issues to improve the performance of online mobile recommendation. Our contributions are four-fold. First, since we concern the reward of a set of recommended items, we model the online recommendation as a contextual combinatorial bandit problem and define the reward of a recommended set. Second, we propose a novel contextual combinatorial bandit method called UBM-LinUCB to address two issues related to positions by adopting the User Browsing Model (UBM), a click model for web search. Third, we provide a formal regret analysis and prove that our algorithm achieves sublinear regret independent of the number of items. Finally, we evaluate our algorithm on two real-world datasets by a novel unbiased estimator. An online experiment is also implemented in Taobao, one of the most popular e-commerce platforms in the world. Results on two CTR metrics show that our algorithm outperforms the other contextual bandit algorithms.
Learning to Collaborate: Multi-Scenario Ranking via Multi-Agent Reinforcement Learning
Sep 17, 2018

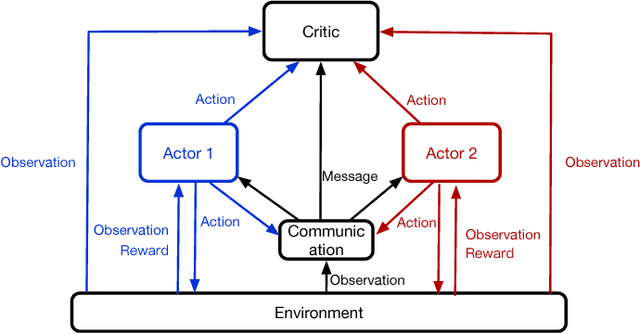

Ranking is a fundamental and widely studied problem in scenarios such as search, advertising, and recommendation. However, joint optimization for multi-scenario ranking, which aims to improve the overall performance of several ranking strategies in different scenarios, is rather untouched. Separately optimizing each individual strategy has two limitations. The first one is lack of collaboration between scenarios meaning that each strategy maximizes its own objective but ignores the goals of other strategies, leading to a sub-optimal overall performance. The second limitation is the inability of modeling the correlation between scenarios meaning that independent optimization in one scenario only uses its own user data but ignores the context in other scenarios. In this paper, we formulate multi-scenario ranking as a fully cooperative, partially observable, multi-agent sequential decision problem. We propose a novel model named Multi-Agent Recurrent Deterministic Policy Gradient (MA-RDPG) which has a communication component for passing messages, several private actors (agents) for making actions for ranking, and a centralized critic for evaluating the overall performance of the co-working actors. Each scenario is treated as an agent (actor). Agents collaborate with each other by sharing a global action-value function (the critic) and passing messages that encodes historical information across scenarios. The model is evaluated with online settings on a large E-commerce platform. Results show that the proposed model exhibits significant improvements against baselines in terms of the overall performance.
Alternating Multi-bit Quantization for Recurrent Neural Networks
Feb 01, 2018
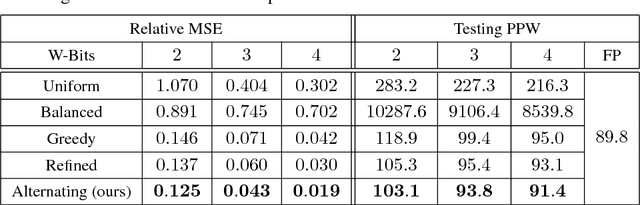
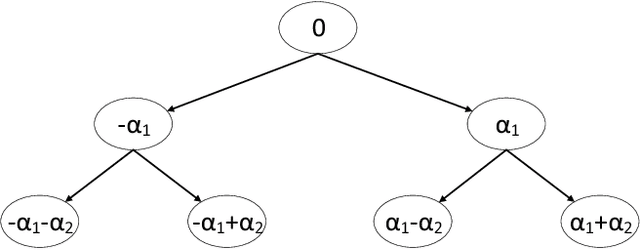
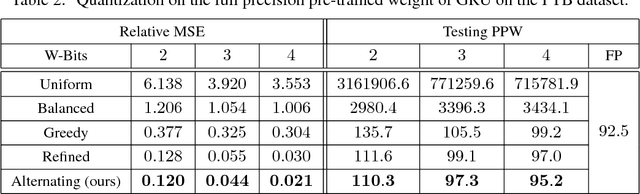
Recurrent neural networks have achieved excellent performance in many applications. However, on portable devices with limited resources, the models are often too large to deploy. For applications on the server with large scale concurrent requests, the latency during inference can also be very critical for costly computing resources. In this work, we address these problems by quantizing the network, both weights and activations, into multiple binary codes {-1,+1}. We formulate the quantization as an optimization problem. Under the key observation that once the quantization coefficients are fixed the binary codes can be derived efficiently by binary search tree, alternating minimization is then applied. We test the quantization for two well-known RNNs, i.e., long short term memory (LSTM) and gated recurrent unit (GRU), on the language models. Compared with the full-precision counter part, by 2-bit quantization we can achieve ~16x memory saving and ~6x real inference acceleration on CPUs, with only a reasonable loss in the accuracy. By 3-bit quantization, we can achieve almost no loss in the accuracy or even surpass the original model, with ~10.5x memory saving and ~3x real inference acceleration. Both results beat the exiting quantization works with large margins. We extend our alternating quantization to image classification tasks. In both RNNs and feedforward neural networks, the method also achieves excellent performance.