 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMAligner: Enhancing Image Alignment via Diffusion Model Based View Synthesis
Feb 26, 2026Image alignment is a fundamental task in computer vision with broad applications. Existing methods predominantly employ optical flow-based image warping. However, this technique is susceptible to common challenges such as occlusions and illumination variations, leading to degraded alignment visual quality and compromised accuracy in downstream tasks. In this paper, we present DMAligner, a diffusion-based framework for image alignment through alignment-oriented view synthesis. DMAligner is crafted to tackle the challenges in image alignment from a new perspective, employing a generation-based solution that showcases strong capabilities and avoids the problems associated with flow-based image warping. Specifically, we propose a Dynamics-aware Diffusion Training approach for learning conditional image generation, synthesizing a novel view for image alignment. This incorporates a Dynamics-aware Mask Producing (DMP) module to adaptively distinguish dynamic foreground regions from static backgrounds, enabling the diffusion model to more effectively handle challenges that classical methods struggle to solve. Furthermore, we develop the Dynamic Scene Image Alignment (DSIA) dataset using Blender, which includes 1,033 indoor and outdoor scenes with over 30K image pairs tailored for image alignment. Extensive experimental results demonstrate the superiority of the proposed approach on DSIA benchmarks, as well as on a series of widely-used video datasets for qualitative comparisons. Our code is available at https://github.com/boomluo02/DMAligner.
R^2MoE: Redundancy-Removal Mixture of Experts for Lifelong Concept Learning
Jul 17, 2025Enabling large-scale generative models to continuously learn new visual concepts is essential for personalizing pre-trained models to meet individual user preferences. Existing approaches for continual visual concept learning are constrained by two fundamental challenges: catastrophic forgetting and parameter expansion. In this paper, we propose Redundancy-Removal Mixture of Experts (R^2MoE), a parameter-efficient framework for lifelong visual concept learning that effectively learns new concepts while incurring minimal parameter overhead. Our framework includes three key innovative contributions: First, we propose a mixture-of-experts framework with a routing distillation mechanism that enables experts to acquire concept-specific knowledge while preserving the gating network's routing capability, thereby effectively mitigating catastrophic forgetting. Second, we propose a strategy for eliminating redundant layer-wise experts that reduces the number of expert parameters by fully utilizing previously learned experts. Third, we employ a hierarchical local attention-guided inference approach to mitigate interference between generated visual concepts. Extensive experiments have demonstrated that our method generates images with superior conceptual fidelity compared to the state-of-the-art (SOTA) method, achieving an impressive 87.8\% reduction in forgetting rates and 63.3\% fewer parameters on the CustomConcept 101 dataset. Our code is available at {https://github.com/learninginvision/R2MoE}
DA-STGCN: 4D Trajectory Prediction Based on Spatiotemporal Feature Extraction
Mar 05, 2025The importance of four-dimensional (4D) trajectory prediction within air traffic management systems is on the rise. Key operations such as conflict detection and resolution, aircraft anomaly monitoring, and the management of congested flight paths are increasingly reliant on this foundational technology, underscoring the urgent demand for intelligent solutions. The dynamics in airport terminal zones and crowded airspaces are intricate and ever-changing; however, current methodologies do not sufficiently account for the interactions among aircraft. To tackle these challenges, we propose DA-STGCN, an innovative spatiotemporal graph convolutional network that integrates a dual attention mechanism. Our model reconstructs the adjacency matrix through a self-attention approach, enhancing the capture of node correlations, and employs graph attention to distill spatiotemporal characteristics, thereby generating a probabilistic distribution of predicted trajectories. This novel adjacency matrix, reconstructed with the self-attention mechanism, is dynamically optimized throughout the network's training process, offering a more nuanced reflection of the inter-node relationships compared to traditional algorithms. The performance of the model is validated on two ADS-B datasets, one near the airport terminal area and the other in dense airspace. Experimental results demonstrate a notable improvement over current 4D trajectory prediction methods, achieving a 20% and 30% reduction in the Average Displacement Error (ADE) and Final Displacement Error (FDE), respectively. The incorporation of a Dual-Attention module has been shown to significantly enhance the extraction of node correlations, as verified by ablation experiments.
Multiple Latent Space Mapping for Compressed Dark Image Enhancement
Mar 12, 2024



Dark image enhancement aims at converting dark images to normal-light images. Existing dark image enhancement methods take uncompressed dark images as inputs and achieve great performance. However, in practice, dark images are often compressed before storage or transmission over the Internet. Current methods get poor performance when processing compressed dark images. Artifacts hidden in the dark regions are amplified by current methods, which results in uncomfortable visual effects for observers. Based on this observation, this study aims at enhancing compressed dark images while avoiding compression artifacts amplification. Since texture details intertwine with compression artifacts in compressed dark images, detail enhancement and blocking artifacts suppression contradict each other in image space. Therefore, we handle the task in latent space. To this end, we propose a novel latent mapping network based on variational auto-encoder (VAE). Firstly, different from previous VAE-based methods with single-resolution features only, we exploit multiple latent spaces with multi-resolution features, to reduce the detail blur and improve image fidelity. Specifically, we train two multi-level VAEs to project compressed dark images and normal-light images into their latent spaces respectively. Secondly, we leverage a latent mapping network to transform features from compressed dark space to normal-light space. Specifically, since the degradation models of darkness and compression are different from each other, the latent mapping process is divided mapping into enlightening branch and deblocking branch. Comprehensive experiments demonstrate that the proposed method achieves state-of-the-art performance in compressed dark image enhancement.
Learning Optical Flow from Event Camera with Rendered Dataset
Mar 20, 2023



We study the problem of estimating optical flow from event cameras. One important issue is how to build a high-quality event-flow dataset with accurate event values and flow labels. Previous datasets are created by either capturing real scenes by event cameras or synthesizing from images with pasted foreground objects. The former case can produce real event values but with calculated flow labels, which are sparse and inaccurate. The later case can generate dense flow labels but the interpolated events are prone to errors. In this work, we propose to render a physically correct event-flow dataset using computer graphics models. In particular, we first create indoor and outdoor 3D scenes by Blender with rich scene content variations. Second, diverse camera motions are included for the virtual capturing, producing images and accurate flow labels. Third, we render high-framerate videos between images for accurate events. The rendered dataset can adjust the density of events, based on which we further introduce an adaptive density module (ADM). Experiments show that our proposed dataset can facilitate event-flow learning, whereas previous approaches when trained on our dataset can improve their performances constantly by a relatively large margin. In addition, event-flow pipelines when equipped with our ADM can further improve performances.
Stereo RGB and Deeper LIDAR Based Network for 3D Object Detection
Jun 09, 2020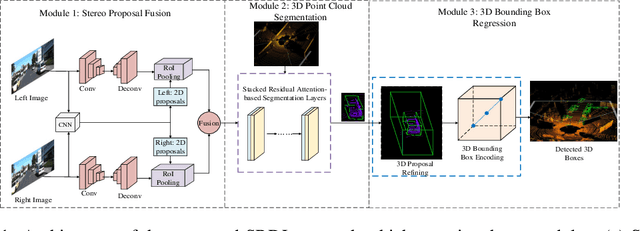
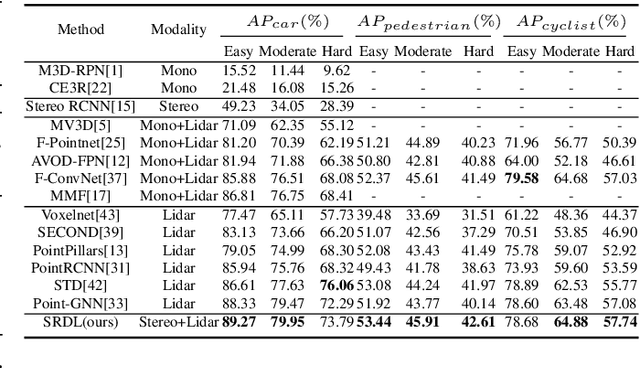
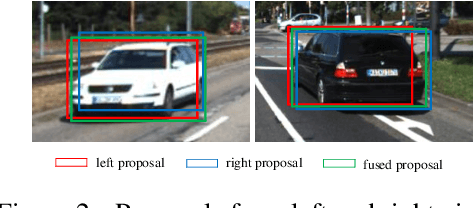
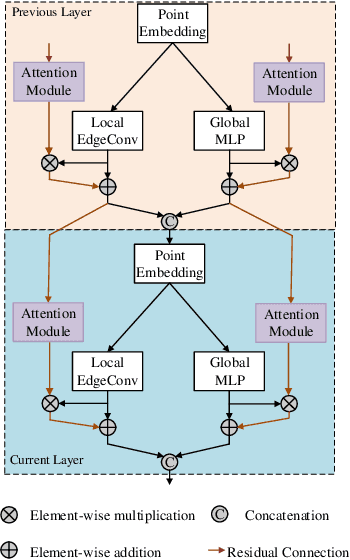
3D object detection has become an emerging task in autonomous driving scenarios. Previous works process 3D point clouds using either projection-based or voxel-based models. However, both approaches contain some drawbacks. The voxel-based methods lack semantic information, while the projection-based methods suffer from numerous spatial information loss when projected to different views. In this paper, we propose the Stereo RGB and Deeper LIDAR (SRDL) framework which can utilize semantic and spatial information simultaneously such that the performance of network for 3D object detection can be improved naturally. Specifically, the network generates candidate boxes from stereo pairs and combines different region-wise features using a deep fusion scheme. The stereo strategy offers more information for prediction compared with prior works. Then, several local and global feature extractors are stacked in the segmentation module to capture richer deep semantic geometric features from point clouds. After aligning the interior points with fused features, the proposed network refines the prediction in a more accurate manner and encodes the whole box in a novel compact method. The decent experimental results on the challenging KITTI detection benchmark demonstrate the effectiveness of utilizing both stereo images and point clouds for 3D object detection.
SVGA-Net: Sparse Voxel-Graph Attention Network for 3D Object Detection from Point Clouds
Jun 07, 2020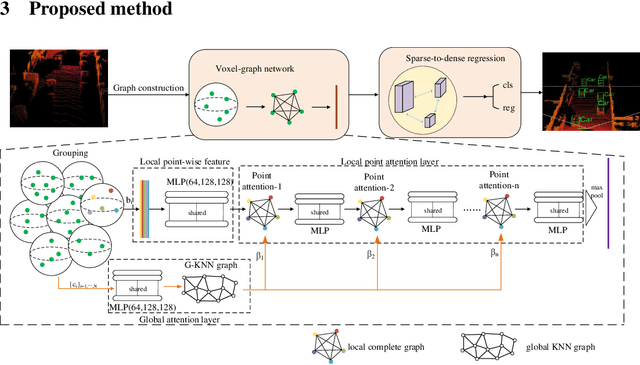
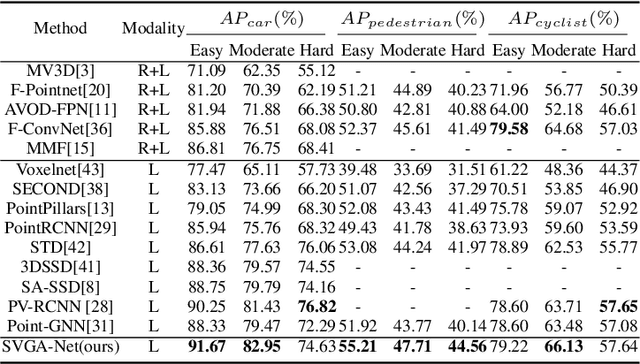
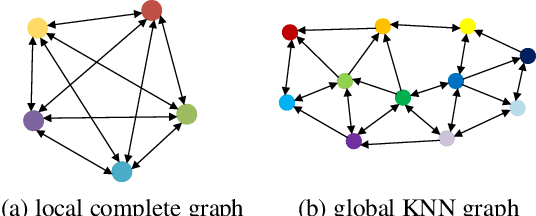
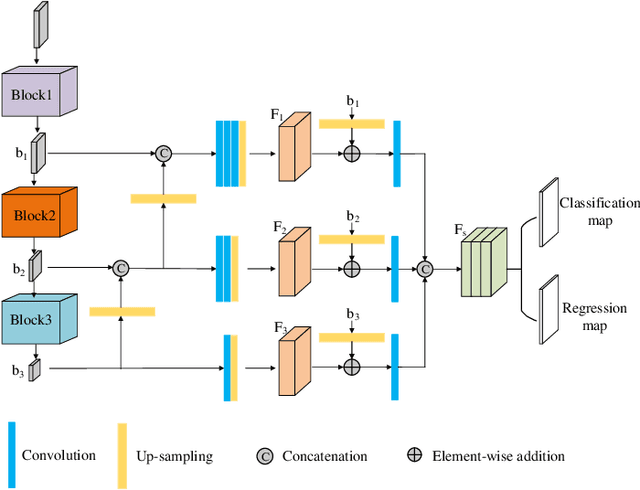
Accurate 3D object detection from point clouds has become a crucial component in autonomous driving. However, the volumetric representations and the projection methods in previous works fail to establish the relationships between the local point sets. In this paper, we propose Sparse Voxel-Graph Attention Network (SVGA-Net), a novel end-to-end trainable network which mainly contains voxel-graph module and sparse-to-dense regression module to achieve comparable 3D detection tasks from raw LIDAR data. Specifically, SVGA-Net constructs the local complete graph within each divided 3D spherical voxel and global KNN graph through all voxels. The local and global graphs serve as the attention mechanism to enhance the extracted features. In addition, the novel sparse-to-dense regression module enhances the 3D box estimation accuracy through feature maps aggregation at different levels. Experiments on KITTI detection benchmark demonstrate the efficiency of extending the graph representation to 3D object detection and the proposed SVGA-Net can achieve decent detection accuracy.