 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVGA-Net: Sparse Voxel-Graph Attention Network for 3D Object Detection from Point Clouds
Paper and Code
Jun 07, 2020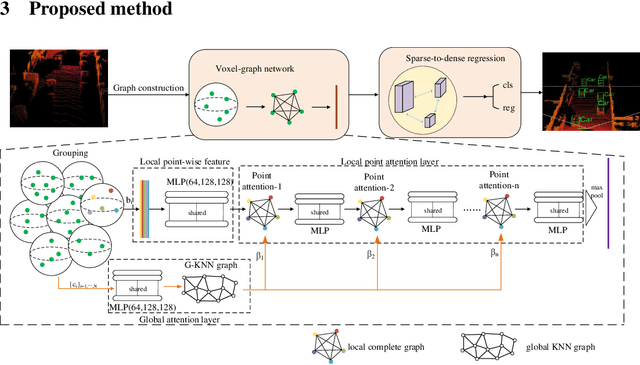
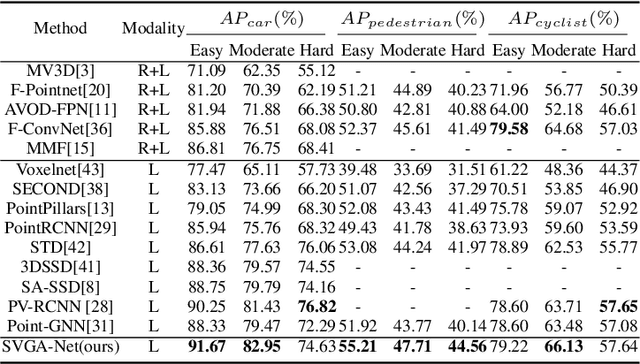
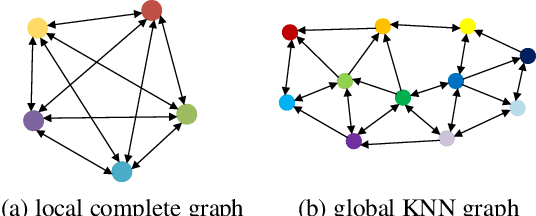
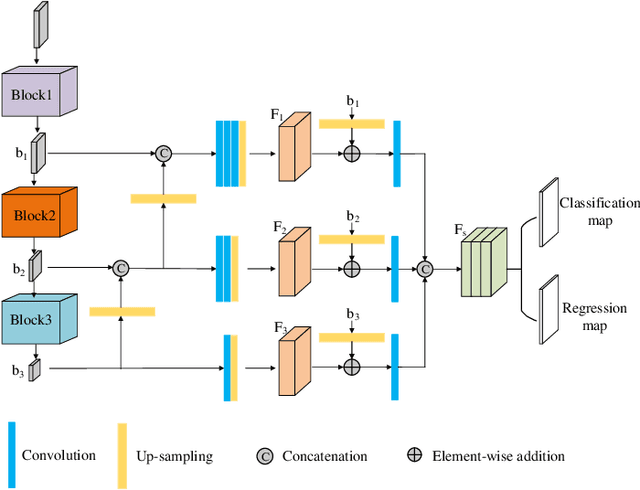
Accurate 3D object detection from point clouds has become a crucial component in autonomous driving. However, the volumetric representations and the projection methods in previous works fail to establish the relationships between the local point sets. In this paper, we propose Sparse Voxel-Graph Attention Network (SVGA-Net), a novel end-to-end trainable network which mainly contains voxel-graph module and sparse-to-dense regression module to achieve comparable 3D detection tasks from raw LIDAR data. Specifically, SVGA-Net constructs the local complete graph within each divided 3D spherical voxel and global KNN graph through all voxels. The local and global graphs serve as the attention mechanism to enhance the extracted features. In addition, the novel sparse-to-dense regression module enhances the 3D box estimation accuracy through feature maps aggregation at different levels. Experiments on KITTI detection benchmark demonstrate the efficiency of extending the graph representation to 3D object detection and the proposed SVGA-Net can achieve decent detection accuracy.