 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassroom-Inspired Multi-Mentor Distillation with Adaptive Learning Strategies
Sep 30, 2024We propose ClassroomKD, a novel multi-mentor knowledge distillation framework inspired by classroom environments to enhance knowledge transfer between student and multiple mentors. Unlike traditional methods that rely on fixed mentor-student relationships, our framework dynamically selects and adapts the teaching strategies of diverse mentors based on their effectiveness for each data sample. ClassroomKD comprises two main modules: the Knowledge Filtering (KF) Module and the Mentoring Module. The KF Module dynamically ranks mentors based on their performance for each input, activating only high-quality mentors to minimize error accumulation and prevent information loss. The Mentoring Module adjusts the distillation strategy by tuning each mentor's influence according to the performance gap between the student and mentors, effectively modulating the learning pace. Extensive experiments on image classification (CIFAR-100 and ImageNet) and 2D human pose estimation (COCO Keypoints and MPII Human Pose) demonstrate that ClassroomKD significantly outperforms existing knowledge distillation methods. Our results highlight that a dynamic and adaptive approach to mentor selection and guidance leads to more effective knowledge transfer, paving the way for enhanced model performance through distillation.
Enhanced Bank Check Security: Introducing a Novel Dataset and Transformer-Based Approach for Detection and Verification
Jun 20, 2024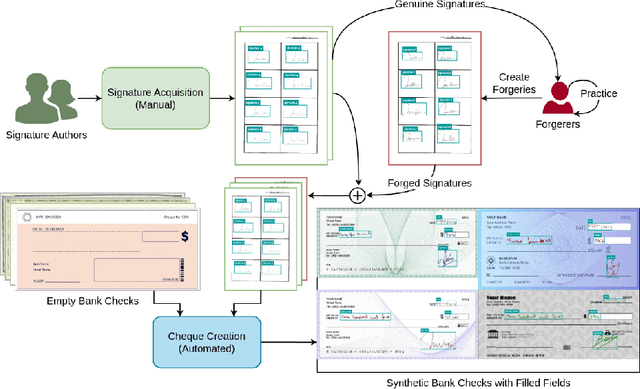
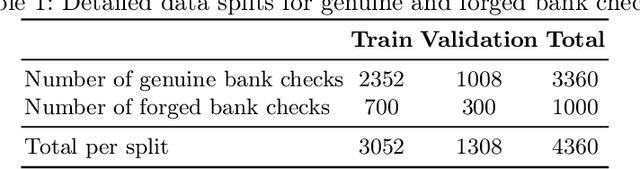
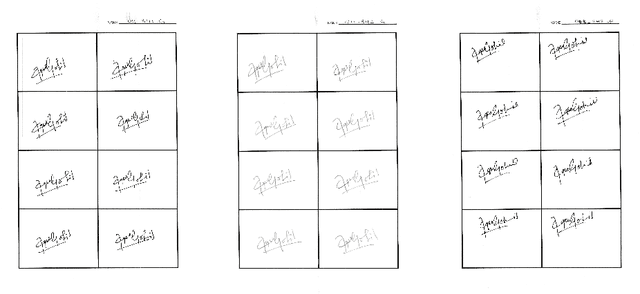
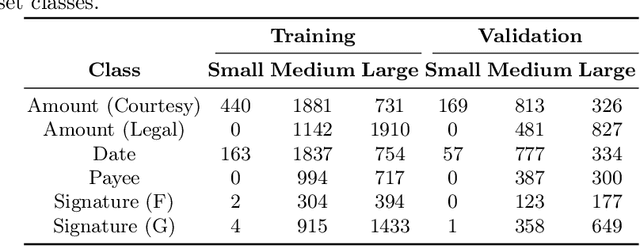
Automated signature verification on bank checks is critical for fraud prevention and ensuring transaction authenticity. This task is challenging due to the coexistence of signatures with other textual and graphical elements on real-world documents. Verification systems must first detect the signature and then validate its authenticity, a dual challenge often overlooked by current datasets and methodologies focusing only on verification. To address this gap, we introduce a novel dataset specifically designed for signature verification on bank checks. This dataset includes a variety of signature styles embedded within typical check elements, providing a realistic testing ground for advanced detection methods. Moreover, we propose a novel approach for writer-independent signature verification using an object detection network. Our detection-based verification method treats genuine and forged signatures as distinct classes within an object detection framework, effectively handling both detection and verification. We employ a DINO-based network augmented with a dilation module to detect and verify signatures on check images simultaneously. Our approach achieves an AP of 99.2 for genuine and 99.4 for forged signatures, a significant improvement over the DINO baseline, which scored 93.1 and 89.3 for genuine and forged signatures, respectively. This improvement highlights our dilation module's effectiveness in reducing both false positives and negatives. Our results demonstrate substantial advancements in detection-based signature verification technology, offering enhanced security and efficiency in financial document processing.
UnSupDLA: Towards Unsupervised Document Layout Analysis
Jun 10, 2024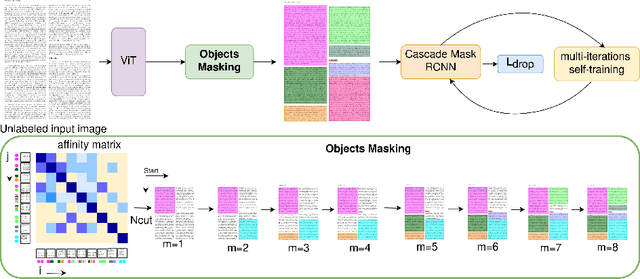


Document layout analysis is a key area in document research, involving techniques like text mining and visual analysis. Despite various methods developed to tackle layout analysis, a critical but frequently overlooked problem is the scarcity of labeled data needed for analyses. With the rise of internet use, an overwhelming number of documents are now available online, making the process of accurately labeling them for research purposes increasingly challenging and labor-intensive. Moreover, the diversity of documents online presents a unique set of challenges in maintaining the quality and consistency of these labels, further complicating document layout analysis in the digital era. To address this, we employ a vision-based approach for analyzing document layouts designed to train a network without labels. Instead, we focus on pre-training, initially generating simple object masks from the unlabeled document images. These masks are then used to train a detector, enhancing object detection and segmentation performance. The model's effectiveness is further amplified through several unsupervised training iterations, continuously refining its performance. This approach significantly advances document layout analysis, particularly precision and efficiency, without labels.
End-to-End Semi-Supervised approach with Modulated Object Queries for Table Detection in Documents
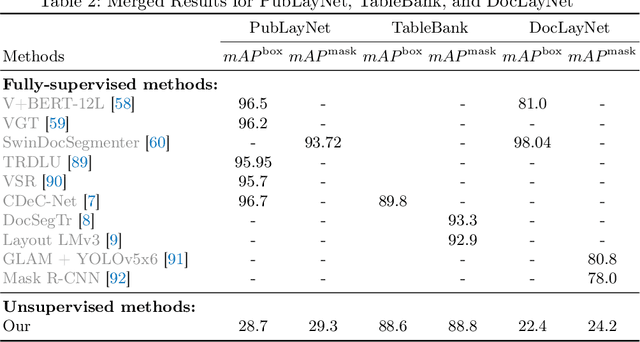
May 08, 2024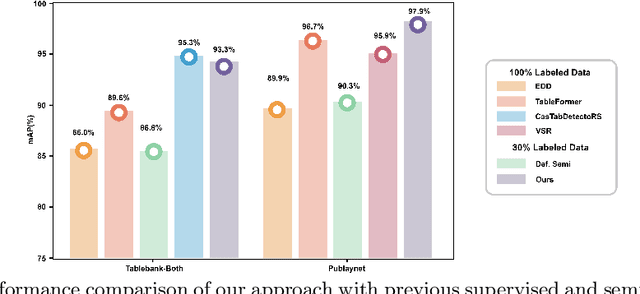
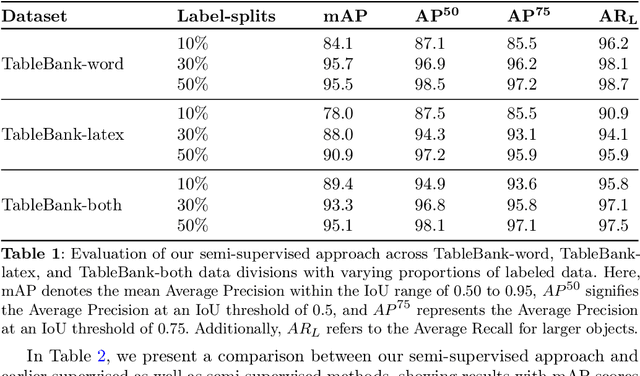
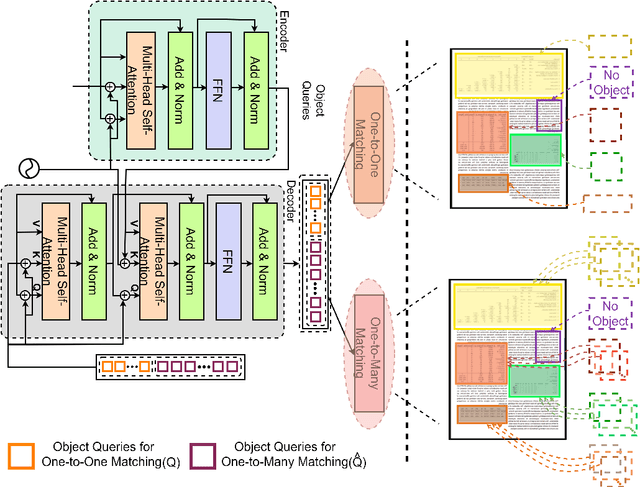

Table detection, a pivotal task in document analysis, aims to precisely recognize and locate tables within document images. Although deep learning has shown remarkable progress in this realm, it typically requires an extensive dataset of labeled data for proficient training. Current CNN-based semi-supervised table detection approaches use the anchor generation process and Non-Maximum Suppression (NMS) in their detection process, limiting training efficiency. Meanwhile, transformer-based semi-supervised techniques adopted a one-to-one match strategy that provides noisy pseudo-labels, limiting overall efficiency. This study presents an innovative transformer-based semi-supervised table detector. It improves the quality of pseudo-labels through a novel matching strategy combining one-to-one and one-to-many assignment techniques. This approach significantly enhances training efficiency during the early stages, ensuring superior pseudo-labels for further training. Our semi-supervised approach is comprehensively evaluated on benchmark datasets, including PubLayNet, ICADR-19, and TableBank. It achieves new state-of-the-art results, with a mAP of 95.7% and 97.9% on TableBank (word) and PubLaynet with 30% label data, marking a 7.4 and 7.6 point improvement over previous semi-supervised table detection approach, respectively. The results clearly show the superiority of our semi-supervised approach, surpassing all existing state-of-the-art methods by substantial margins. This research represents a significant advancement in semi-supervised table detection methods, offering a more efficient and accurate solution for practical document analysis tasks.
A Hybrid Approach for Document Layout Analysis in Document images
Apr 30, 2024Document layout analysis involves understanding the arrangement of elements within a document. This paper navigates the complexities of understanding various elements within document images, such as text, images, tables, and headings. The approach employs an advanced Transformer-based object detection network as an innovative graphical page object detector for identifying tables, figures, and displayed elements. We introduce a query encoding mechanism to provide high-quality object queries for contrastive learning, enhancing efficiency in the decoder phase. We also present a hybrid matching scheme that integrates the decoder's original one-to-one matching strategy with the one-to-many matching strategy during the training phase. This approach aims to improve the model's accuracy and versatility in detecting various graphical elements on a page. Our experiments on PubLayNet, DocLayNet, and PubTables benchmarks show that our approach outperforms current state-of-the-art methods. It achieves an average precision of 97.3% on PubLayNet, 81.6% on DocLayNet, and 98.6 on PubTables, demonstrating its superior performance in layout analysis. These advancements not only enhance the conversion of document images into editable and accessible formats but also streamline information retrieval and data extraction processes.
Sparse Semi-DETR: Sparse Learnable Queries for Semi-Supervised Object Detection
Apr 02, 2024In this paper, we address the limitations of the DETR-based semi-supervised object detection (SSOD) framework, particularly focusing on the challenges posed by the quality of object queries. In DETR-based SSOD, the one-to-one assignment strategy provides inaccurate pseudo-labels, while the one-to-many assignments strategy leads to overlapping predictions. These issues compromise training efficiency and degrade model performance, especially in detecting small or occluded objects. We introduce Sparse Semi-DETR, a novel transformer-based, end-to-end semi-supervised object detection solution to overcome these challenges. Sparse Semi-DETR incorporates a Query Refinement Module to enhance the quality of object queries, significantly improving detection capabilities for small and partially obscured objects. Additionally, we integrate a Reliable Pseudo-Label Filtering Module that selectively filters high-quality pseudo-labels, thereby enhancing detection accuracy and consistency. On the MS-COCO and Pascal VOC object detection benchmarks, Sparse Semi-DETR achieves a significant improvement over current state-of-the-art methods that highlight Sparse Semi-DETR's effectiveness in semi-supervised object detection, particularly in challenging scenarios involving small or partially obscured objects.
Object Detection with Transformers: A Review
Jun 27, 2023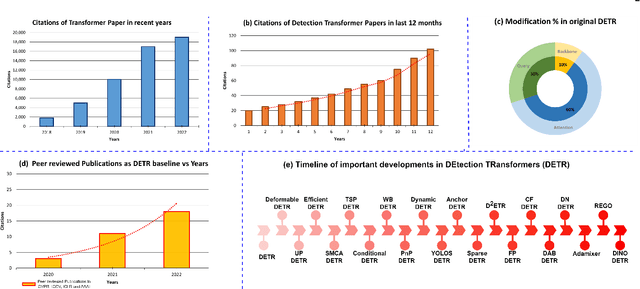
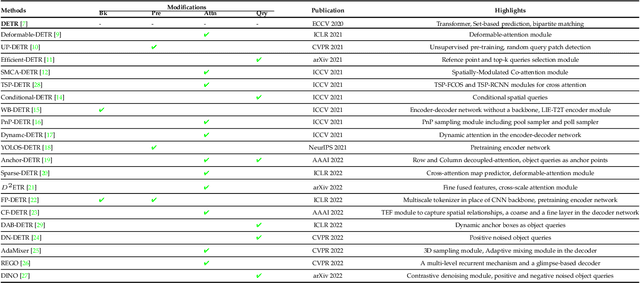
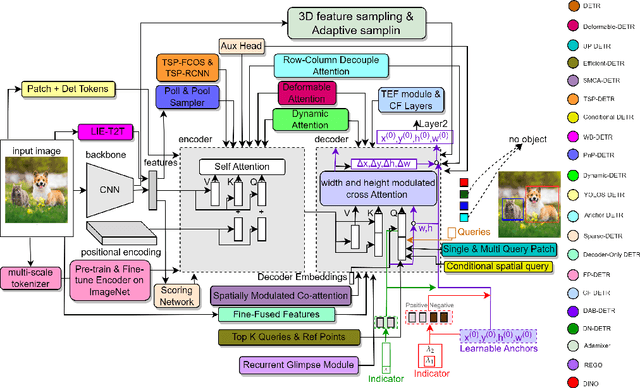
Astounding performance of Transformers in natural language processing (NLP) has delighted researchers to explore their utilization in computer vision tasks. Like other computer vision tasks, DEtection TRansformer (DETR) introduces transformers for object detection tasks by considering the detection as a set prediction problem without needing proposal generation and post-processing steps. It is a state-of-the-art (SOTA) method for object detection, particularly in scenarios where the number of objects in an image is relatively small. Despite the success of DETR, it suffers from slow training convergence and performance drops for small objects. Therefore, many improvements are proposed to address these issues, leading to immense refinement in DETR. Since 2020, transformer-based object detection has attracted increasing interest and demonstrated impressive performance. Although numerous surveys have been conducted on transformers in vision in general, a review regarding advancements made in 2D object detection using transformers is still missing. This paper gives a detailed review of twenty-one papers about recent developments in DETR. We begin with the basic modules of Transformers, such as self-attention, object queries and input features encoding. Then, we cover the latest advancements in DETR, including backbone modification, query design and attention refinement. We also compare all detection transformers in terms of performance and network design. We hope this study will increase the researcher's interest in solving existing challenges towards applying transformers in the object detection domain. Researchers can follow newer improvements in detection transformers on this webpage available at: https://github.com/mindgarage-shan/trans_object_detection_survey
Bridging the Performance Gap between DETR and R-CNN for Graphical Object Detection in Document Images
Jun 23, 2023This paper takes an important step in bridging the performance gap between DETR and R-CNN for graphical object detection. Existing graphical object detection approaches have enjoyed recent enhancements in CNN-based object detection methods, achieving remarkable progress. Recently, Transformer-based detectors have considerably boosted the generic object detection performance, eliminating the need for hand-crafted features or post-processing steps such as Non-Maximum Suppression (NMS) using object queries. However, the effectiveness of such enhanced transformer-based detection algorithms has yet to be verified for the problem of graphical object detection. Essentially, inspired by the latest advancements in the DETR, we employ the existing detection transformer with few modifications for graphical object detection. We modify object queries in different ways, using points, anchor boxes and adding positive and negative noise to the anchors to boost performance. These modifications allow for better handling of objects with varying sizes and aspect ratios, more robustness to small variations in object positions and sizes, and improved image discrimination between objects and non-objects. We evaluate our approach on the four graphical datasets: PubTables, TableBank, NTable and PubLaynet. Upon integrating query modifications in the DETR, we outperform prior works and achieve new state-of-the-art results with the mAP of 96.9\%, 95.7\% and 99.3\% on TableBank, PubLaynet, PubTables, respectively. The results from extensive ablations show that transformer-based methods are more effective for document analysis analogous to other applications. We hope this study draws more attention to the research of using detection transformers in document image analysis.
Towards End-to-End Semi-Supervised Table Detection with Deformable Transformer
May 07, 2023Table detection is the task of classifying and localizing table objects within document images. With the recent development in deep learning methods, we observe remarkable success in table detection. However, a significant amount of labeled data is required to train these models effectively. Many semi-supervised approaches are introduced to mitigate the need for a substantial amount of label data. These approaches use CNN-based detectors that rely on anchor proposals and post-processing stages such as NMS. To tackle these limitations, this paper presents a novel end-to-end semi-supervised table detection method that employs the deformable transformer for detecting table objects. We evaluate our semi-supervised method on PubLayNet, DocBank, ICADR-19 and TableBank datasets, and it achieves superior performance compared to previous methods. It outperforms the fully supervised method (Deformable transformer) by +3.4 points on 10\% labels of TableBank-both dataset and the previous CNN-based semi-supervised approach (Soft Teacher) by +1.8 points on 10\% labels of PubLayNet dataset. We hope this work opens new possibilities towards semi-supervised and unsupervised table detection methods.