 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Semi-Supervised approach with Modulated Object Queries for Table Detection in Documents
May 08, 2024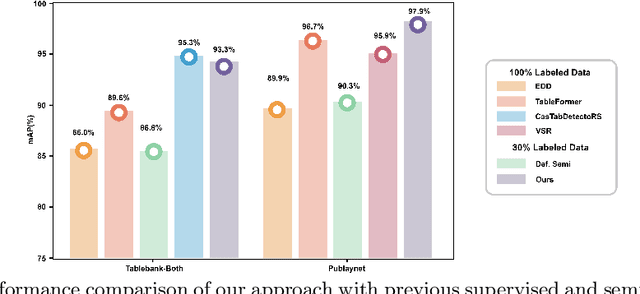
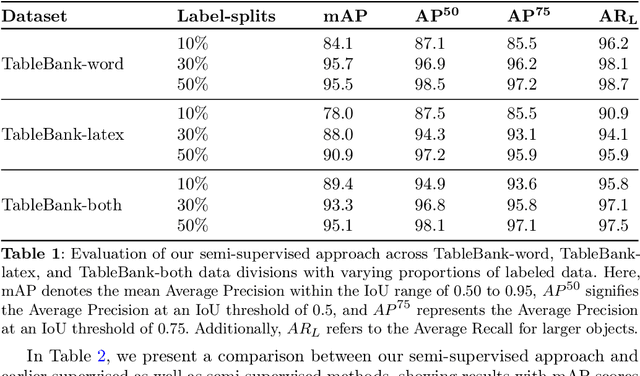
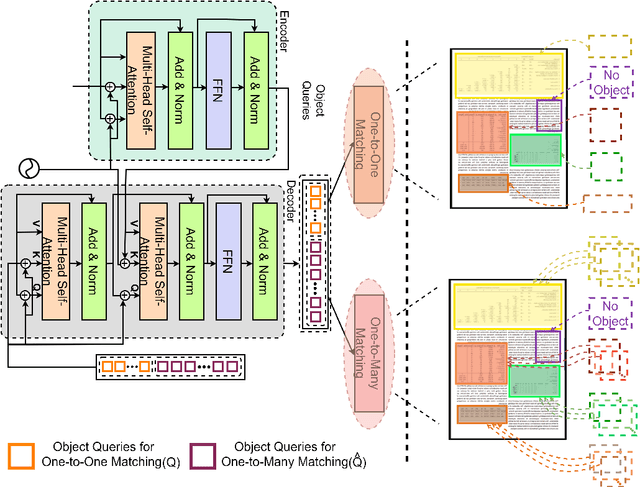

Table detection, a pivotal task in document analysis, aims to precisely recognize and locate tables within document images. Although deep learning has shown remarkable progress in this realm, it typically requires an extensive dataset of labeled data for proficient training. Current CNN-based semi-supervised table detection approaches use the anchor generation process and Non-Maximum Suppression (NMS) in their detection process, limiting training efficiency. Meanwhile, transformer-based semi-supervised techniques adopted a one-to-one match strategy that provides noisy pseudo-labels, limiting overall efficiency. This study presents an innovative transformer-based semi-supervised table detector. It improves the quality of pseudo-labels through a novel matching strategy combining one-to-one and one-to-many assignment techniques. This approach significantly enhances training efficiency during the early stages, ensuring superior pseudo-labels for further training. Our semi-supervised approach is comprehensively evaluated on benchmark datasets, including PubLayNet, ICADR-19, and TableBank. It achieves new state-of-the-art results, with a mAP of 95.7% and 97.9% on TableBank (word) and PubLaynet with 30% label data, marking a 7.4 and 7.6 point improvement over previous semi-supervised table detection approach, respectively. The results clearly show the superiority of our semi-supervised approach, surpassing all existing state-of-the-art methods by substantial margins. This research represents a significant advancement in semi-supervised table detection methods, offering a more efficient and accurate solution for practical document analysis tasks.