 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Boxes: Mask-Guided Spatio-Temporal Feature Aggregation for Video Object Detection
Dec 06, 2024

The primary challenge in Video Object Detection (VOD) is effectively exploiting temporal information to enhance object representations. Traditional strategies, such as aggregating region proposals, often suffer from feature variance due to the inclusion of background information. We introduce a novel instance mask-based feature aggregation approach, significantly refining this process and deepening the understanding of object dynamics across video frames. We present FAIM, a new VOD method that enhances temporal Feature Aggregation by leveraging Instance Mask features. In particular, we propose the lightweight Instance Feature Extraction Module (IFEM) to learn instance mask features and the Temporal Instance Classification Aggregation Module (TICAM) to aggregate instance mask and classification features across video frames. Using YOLOX as a base detector, FAIM achieves 87.9% mAP on the ImageNet VID dataset at 33 FPS on a single 2080Ti GPU, setting a new benchmark for the speed-accuracy trade-off. Additional experiments on multiple datasets validate that our approach is robust, method-agnostic, and effective in multi-object tracking, demonstrating its broader applicability to video understanding tasks.
Text2CAD: Generating Sequential CAD Models from Beginner-to-Expert Level Text Prompts
Sep 25, 2024



Prototyping complex computer-aided design (CAD) models in modern softwares can be very time-consuming. This is due to the lack of intelligent systems that can quickly generate simpler intermediate parts. We propose Text2CAD, the first AI framework for generating text-to-parametric CAD models using designer-friendly instructions for all skill levels. Furthermore, we introduce a data annotation pipeline for generating text prompts based on natural language instructions for the DeepCAD dataset using Mistral and LLaVA-NeXT. The dataset contains $\sim170$K models and $\sim660$K text annotations, from abstract CAD descriptions (e.g., generate two concentric cylinders) to detailed specifications (e.g., draw two circles with center $(x,y)$ and radius $r_{1}$, $r_{2}$, and extrude along the normal by $d$...). Within the Text2CAD framework, we propose an end-to-end transformer-based auto-regressive network to generate parametric CAD models from input texts. We evaluate the performance of our model through a mixture of metrics, including visual quality, parametric precision, and geometrical accuracy. Our proposed framework shows great potential in AI-aided design applications. Our source code and annotations will be publicly available.
UnSupDLA: Towards Unsupervised Document Layout Analysis
Jun 10, 2024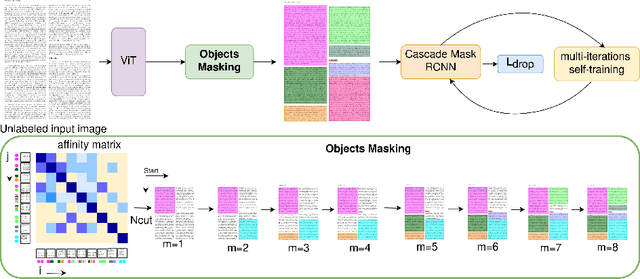


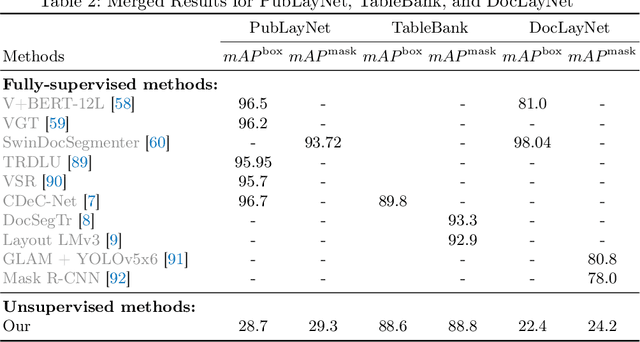
Document layout analysis is a key area in document research, involving techniques like text mining and visual analysis. Despite various methods developed to tackle layout analysis, a critical but frequently overlooked problem is the scarcity of labeled data needed for analyses. With the rise of internet use, an overwhelming number of documents are now available online, making the process of accurately labeling them for research purposes increasingly challenging and labor-intensive. Moreover, the diversity of documents online presents a unique set of challenges in maintaining the quality and consistency of these labels, further complicating document layout analysis in the digital era. To address this, we employ a vision-based approach for analyzing document layouts designed to train a network without labels. Instead, we focus on pre-training, initially generating simple object masks from the unlabeled document images. These masks are then used to train a detector, enhancing object detection and segmentation performance. The model's effectiveness is further amplified through several unsupervised training iterations, continuously refining its performance. This approach significantly advances document layout analysis, particularly precision and efficiency, without labels.
CICA: Content-Injected Contrastive Alignment for Zero-Shot Document Image Classification
May 06, 2024


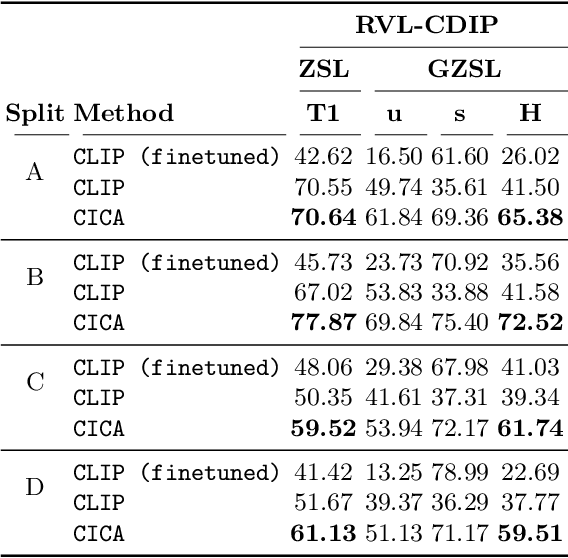
Zero-shot learning has been extensively investigated in the broader field of visual recognition, attracting significant interest recently. However, the current work on zero-shot learning in document image classification remains scarce. The existing studies either focus exclusively on zero-shot inference, or their evaluation does not align with the established criteria of zero-shot evaluation in the visual recognition domain. We provide a comprehensive document image classification analysis in Zero-Shot Learning (ZSL) and Generalized Zero-Shot Learning (GZSL) settings to address this gap. Our methodology and evaluation align with the established practices of this domain. Additionally, we propose zero-shot splits for the RVL-CDIP dataset. Furthermore, we introduce CICA (pronounced 'ki-ka'), a framework that enhances the zero-shot learning capabilities of CLIP. CICA consists of a novel 'content module' designed to leverage any generic document-related textual information. The discriminative features extracted by this module are aligned with CLIP's text and image features using a novel 'coupled-contrastive' loss. Our module improves CLIP's ZSL top-1 accuracy by 6.7% and GZSL harmonic mean by 24% on the RVL-CDIP dataset. Our module is lightweight and adds only 3.3% more parameters to CLIP. Our work sets the direction for future research in zero-shot document classification.