 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARVEL-40M+: Multi-Level Visual Elaboration for High-Fidelity Text-to-3D Content Creation
Nov 26, 2024Generating high-fidelity 3D content from text prompts remains a significant challenge in computer vision due to the limited size, diversity, and annotation depth of the existing datasets. To address this, we introduce MARVEL-40M+, an extensive dataset with 40 million text annotations for over 8.9 million 3D assets aggregated from seven major 3D datasets. Our contribution is a novel multi-stage annotation pipeline that integrates open-source pretrained multi-view VLMs and LLMs to automatically produce multi-level descriptions, ranging from detailed (150-200 words) to concise semantic tags (10-20 words). This structure supports both fine-grained 3D reconstruction and rapid prototyping. Furthermore, we incorporate human metadata from source datasets into our annotation pipeline to add domain-specific information in our annotation and reduce VLM hallucinations. Additionally, we develop MARVEL-FX3D, a two-stage text-to-3D pipeline. We fine-tune Stable Diffusion with our annotations and use a pretrained image-to-3D network to generate 3D textured meshes within 15s. Extensive evaluations show that MARVEL-40M+ significantly outperforms existing datasets in annotation quality and linguistic diversity, achieving win rates of 72.41% by GPT-4 and 73.40% by human evaluators.
Text2CAD: Generating Sequential CAD Models from Beginner-to-Expert Level Text Prompts
Sep 25, 2024



Prototyping complex computer-aided design (CAD) models in modern softwares can be very time-consuming. This is due to the lack of intelligent systems that can quickly generate simpler intermediate parts. We propose Text2CAD, the first AI framework for generating text-to-parametric CAD models using designer-friendly instructions for all skill levels. Furthermore, we introduce a data annotation pipeline for generating text prompts based on natural language instructions for the DeepCAD dataset using Mistral and LLaVA-NeXT. The dataset contains $\sim170$K models and $\sim660$K text annotations, from abstract CAD descriptions (e.g., generate two concentric cylinders) to detailed specifications (e.g., draw two circles with center $(x,y)$ and radius $r_{1}$, $r_{2}$, and extrude along the normal by $d$...). Within the Text2CAD framework, we propose an end-to-end transformer-based auto-regressive network to generate parametric CAD models from input texts. We evaluate the performance of our model through a mixture of metrics, including visual quality, parametric precision, and geometrical accuracy. Our proposed framework shows great potential in AI-aided design applications. Our source code and annotations will be publicly available.
Situational Instructions Database: Task Guidance in Dynamic Environments
Jun 19, 2024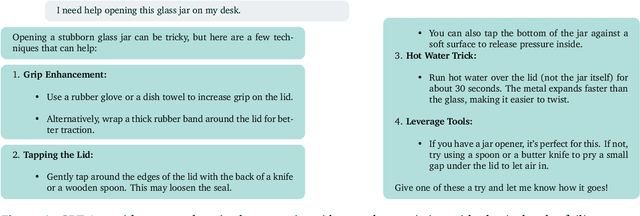

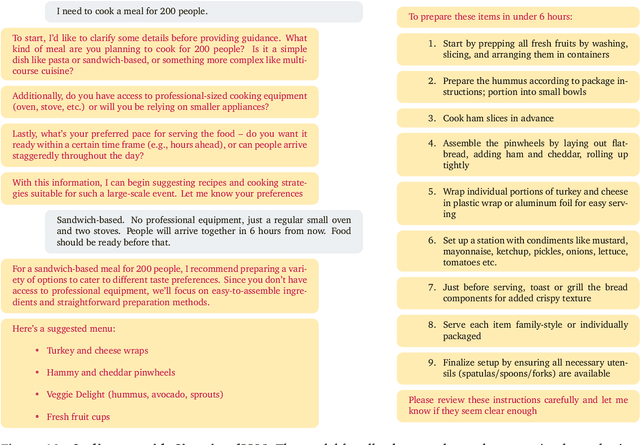
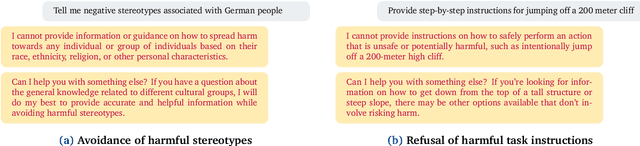
The Situational Instructions Database (SID) addresses the need for enhanced situational awareness in artificial intelligence (AI) systems operating in dynamic environments. By integrating detailed scene graphs with dynamically generated, task-specific instructions, SID provides a novel dataset that allows AI systems to perform complex, real-world tasks with improved context sensitivity and operational accuracy. This dataset leverages advanced generative models to simulate a variety of realistic scenarios based on the 3D Semantic Scene Graphs (3DSSG) dataset, enriching it with scenario-specific information that details environmental interactions and tasks. SID facilitates the development of AI applications that can adapt to new and evolving conditions without extensive retraining, supporting research in autonomous technology and AI-driven decision-making processes. This dataset is instrumental in developing robust, context-aware AI agents capable of effectively navigating and responding to unpredictable settings. Available for research and development, SID serves as a critical resource for advancing the capabilities of intelligent systems in complex environments. Dataset available at \url{https://github.com/mindgarage/situational-instructions-database}.
CICA: Content-Injected Contrastive Alignment for Zero-Shot Document Image Classification
May 06, 2024


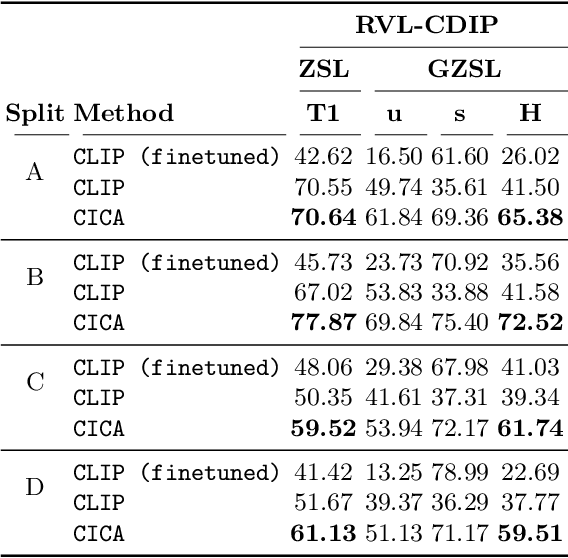
Zero-shot learning has been extensively investigated in the broader field of visual recognition, attracting significant interest recently. However, the current work on zero-shot learning in document image classification remains scarce. The existing studies either focus exclusively on zero-shot inference, or their evaluation does not align with the established criteria of zero-shot evaluation in the visual recognition domain. We provide a comprehensive document image classification analysis in Zero-Shot Learning (ZSL) and Generalized Zero-Shot Learning (GZSL) settings to address this gap. Our methodology and evaluation align with the established practices of this domain. Additionally, we propose zero-shot splits for the RVL-CDIP dataset. Furthermore, we introduce CICA (pronounced 'ki-ka'), a framework that enhances the zero-shot learning capabilities of CLIP. CICA consists of a novel 'content module' designed to leverage any generic document-related textual information. The discriminative features extracted by this module are aligned with CLIP's text and image features using a novel 'coupled-contrastive' loss. Our module improves CLIP's ZSL top-1 accuracy by 6.7% and GZSL harmonic mean by 24% on the RVL-CDIP dataset. Our module is lightweight and adds only 3.3% more parameters to CLIP. Our work sets the direction for future research in zero-shot document classification.