 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnSupDLA: Towards Unsupervised Document Layout Analysis
Paper and Code
Jun 10, 2024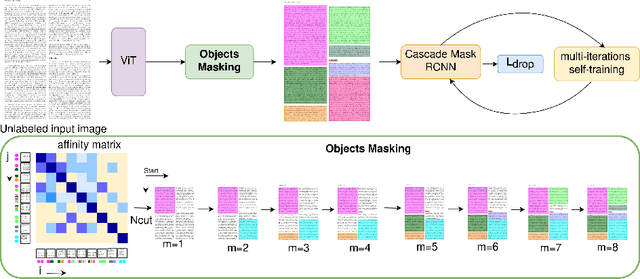


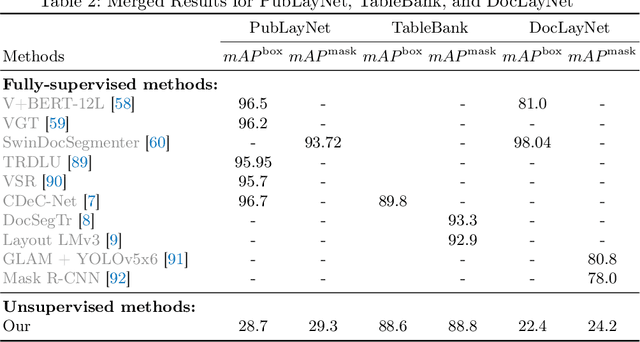
Document layout analysis is a key area in document research, involving techniques like text mining and visual analysis. Despite various methods developed to tackle layout analysis, a critical but frequently overlooked problem is the scarcity of labeled data needed for analyses. With the rise of internet use, an overwhelming number of documents are now available online, making the process of accurately labeling them for research purposes increasingly challenging and labor-intensive. Moreover, the diversity of documents online presents a unique set of challenges in maintaining the quality and consistency of these labels, further complicating document layout analysis in the digital era. To address this, we employ a vision-based approach for analyzing document layouts designed to train a network without labels. Instead, we focus on pre-training, initially generating simple object masks from the unlabeled document images. These masks are then used to train a detector, enhancing object detection and segmentation performance. The model's effectiveness is further amplified through several unsupervised training iterations, continuously refining its performance. This approach significantly advances document layout analysis, particularly precision and efficiency, without labels.