Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling Using Distributed Word Embeddings
Paper and Code
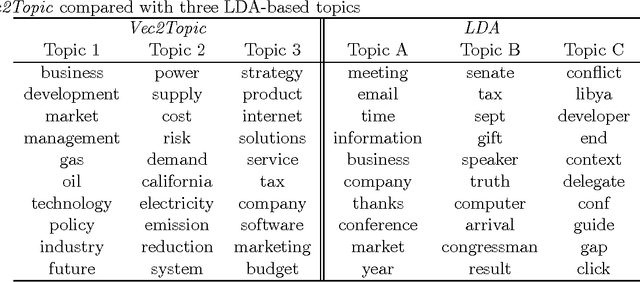
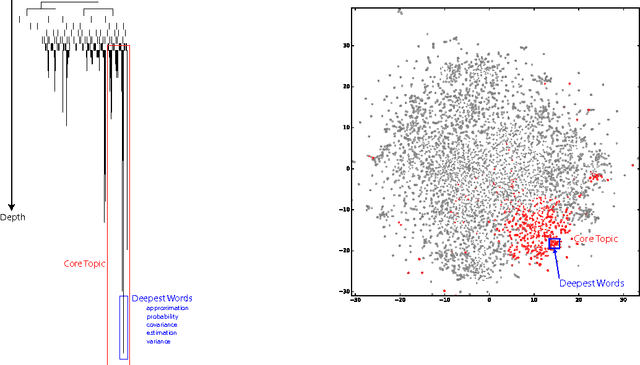

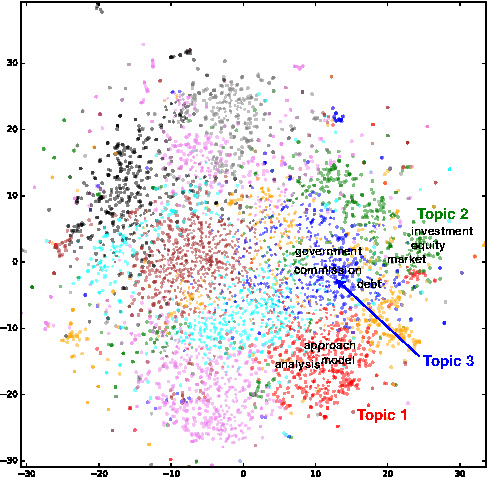
We propose a new algorithm for topic modeling, Vec2Topic, that identifies the main topics in a corpus using semantic information captured via high-dimensional distributed word embeddings. Our technique is unsupervised and generates a list of topics ranked with respect to importance. We find that it works better than existing topic modeling techniques such as Latent Dirichlet Allocation for identifying key topics in user-generated content, such as emails, chats, etc., where topics are diffused across the corpus. We also find that Vec2Topic works equally well for non-user generated content, such as papers, reports, etc., and for small corpora such as a single-document.
View paper on