 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-Judge for Semantic Judging of Powerline Segmentation in UAV Inspection
Apr 07, 2026The deployment of lightweight segmentation models on drones for autonomous power line inspection presents a critical challenge: maintaining reliable performance under real-world conditions that differ from training data. Although compact architectures such as U-Net enable real-time onboard inference, their segmentation outputs can degrade unpredictably in adverse environments, raising safety concerns. In this work, we study the feasibility of using a large language model (LLM) as a semantic judge to assess the reliability of power line segmentation results produced by drone-mounted models. Rather than introducing a new inspection system, we formalize a watchdog scenario in which an offboard LLM evaluates segmentation overlays and examine whether such a judge can be trusted to behave consistently and perceptually coherently. To this end, we design two evaluation protocols that analyze the judge's repeatability and sensitivity. First, we assess repeatability by repeatedly querying the LLM with identical inputs and fixed prompts, measuring the stability of its quality scores and confidence estimates. Second, we evaluate perceptual sensitivity by introducing controlled visual corruptions (fog, rain, snow, shadow, and sunflare) and analyzing how the judge's outputs respond to progressive degradation in segmentation quality. Our results show that the LLM produces highly consistent categorical judgments under identical conditions while exhibiting appropriate declines in confidence as visual reliability deteriorates. Moreover, the judge remains responsive to perceptual cues such as missing or misidentified power lines, even under challenging conditions. These findings suggest that, when carefully constrained, an LLM can serve as a reliable semantic judge for monitoring segmentation quality in safety-critical aerial inspection tasks.
Adaptive Anchor Policies for Efficient 4D Gaussian Streaming
Mar 18, 2026Dynamic scene reconstruction with Gaussian Splatting has enabled efficient streaming for real-time rendering and free-viewpoint video. However, most pipelines rely on fixed anchor selection such as Farthest Point Sampling (FPS), typically using 8,192 anchors regardless of scene complexity, which over-allocates computation under strict budgets. We propose Efficient Gaussian Streaming (EGS), a plug-in, budget-aware anchor sampler that replaces FPS with a reinforcement-learned policy while keeping the Gaussian streaming reconstruction backbone unchanged. The policy jointly selects an anchor budget and a subset of informative anchors under discrete constraints, balancing reconstruction quality and runtime using spatial features of the Gaussian representation. We evaluate EGS in two settings: fast rendering, which prioritizes runtime efficiency, and high-quality refinement, which enables additional optimization. Experiments on dynamic multi-view datasets show consistent improvements in the quality--efficiency trade-off over FPS sampling. On unseen data, in fast rendering at 256 anchors ($32\times$ fewer than 8,192), EGS improves PSNR by $+0.52$--$0.61$\,dB while running $1.29$--$1.35\times$ faster than IGS@8192 (N3DV and MeetingRoom). In high-quality refinement, EGS remains competitive with the full-anchor baseline at substantially lower anchor budgets. \emph{Code and pretrained checkpoints will be released upon acceptance.} \keywords{4D Gaussian Splatting \and 4D Gaussian Streaming \and Reinforcement Learning}
CDUL: CLIP-Driven Unsupervised Learning for Multi-Label Image Classification
Jul 31, 2023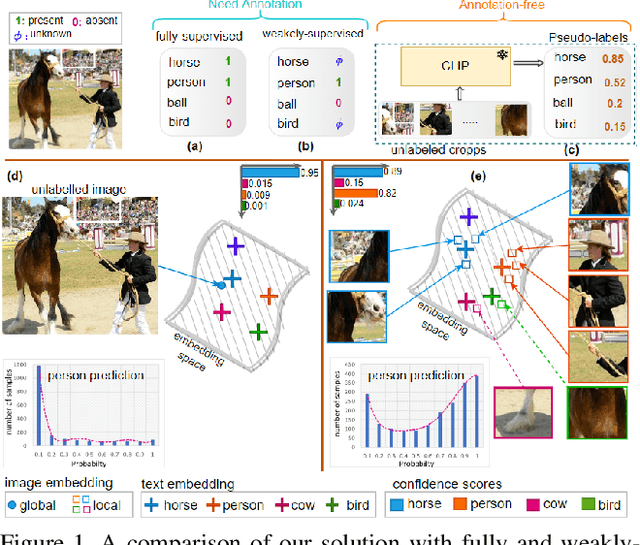
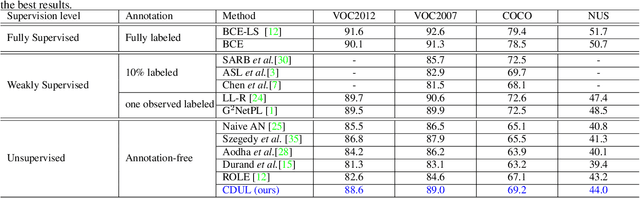
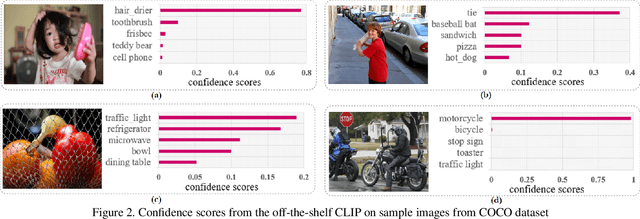

This paper presents a CLIP-based unsupervised learning method for annotation-free multi-label image classification, including three stages: initialization, training, and inference. At the initialization stage, we take full advantage of the powerful CLIP model and propose a novel approach to extend CLIP for multi-label predictions based on global-local image-text similarity aggregation. To be more specific, we split each image into snippets and leverage CLIP to generate the similarity vector for the whole image (global) as well as each snippet (local). Then a similarity aggregator is introduced to leverage the global and local similarity vectors. Using the aggregated similarity scores as the initial pseudo labels at the training stage, we propose an optimization framework to train the parameters of the classification network and refine pseudo labels for unobserved labels. During inference, only the classification network is used to predict the labels of the input image. Extensive experiments show that our method outperforms state-of-the-art unsupervised methods on MS-COCO, PASCAL VOC 2007, PASCAL VOC 2012, and NUS datasets and even achieves comparable results to weakly supervised classification methods.
Leveraging Inpainting for Single-Image Shadow Removal
Feb 10, 2023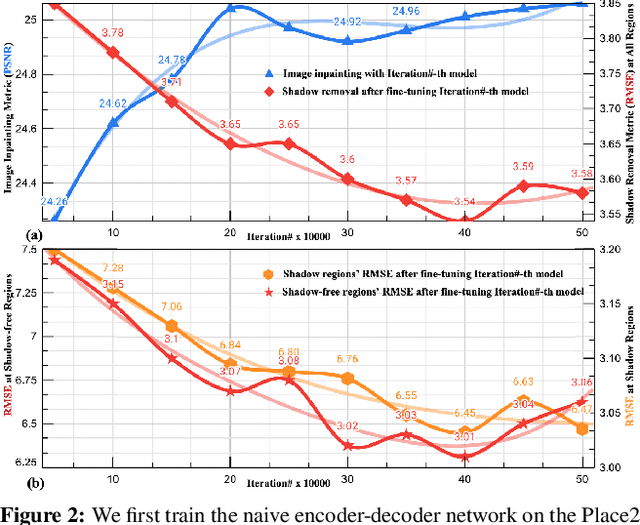
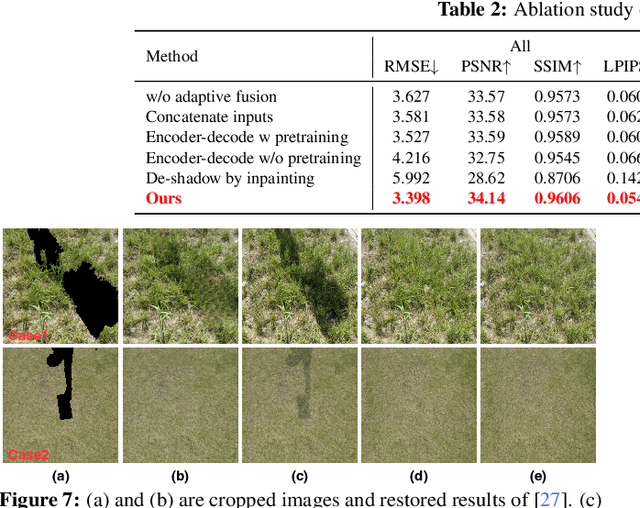
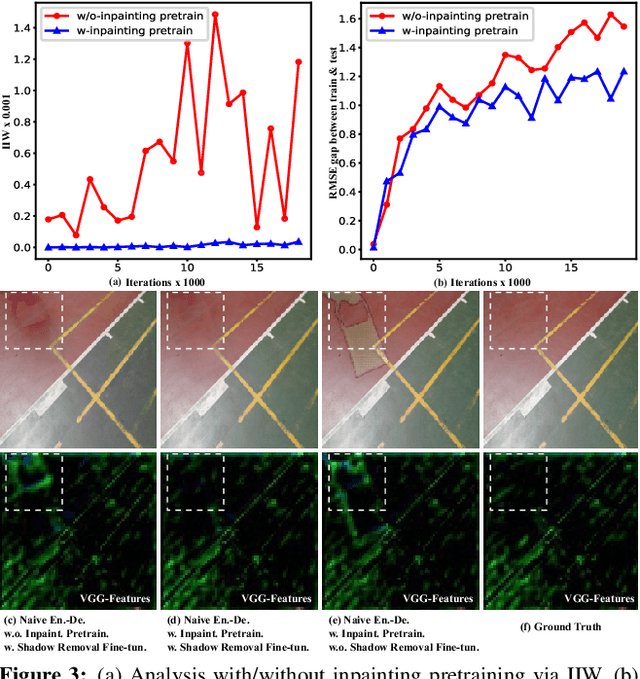
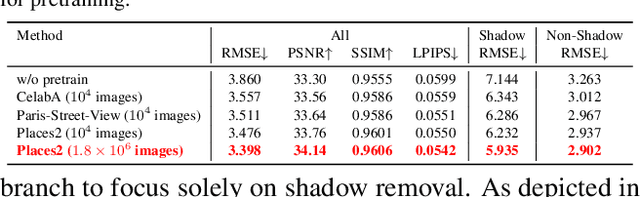
Fully-supervised shadow removal methods achieve top restoration qualities on public datasets but still generate some shadow remnants. One of the reasons is the lack of large-scale shadow & shadow-free image pairs. Unsupervised methods can alleviate the issue but their restoration qualities are much lower than those of fully-supervised methods. In this work, we find that pretraining shadow removal networks on the image inpainting dataset can reduce the shadow remnants significantly: a naive encoder-decoder network gets competitive restoration quality w.r.t. the state-of-the-art methods via only 10% shadow & shadow-free image pairs. We further analyze the difference between networks with/without inpainting pretraining and observe that: inpainting pretraining enhances networks' capability of filling missed semantic information; shadow removal fine-tuning makes the networks know how to fill details of the shadow regions. Inspired by the above observations, we formulate shadow removal as a shadow-guided inpainting task to take advantage of the shadow removal and image inpainting. Specifically, we build a shadow-informed dynamic filtering network with two branches: the image inpainting branch takes the shadow-masked image as input while the second branch takes the shadow image as input and is to estimate dynamic kernels and offsets for the first branch to provide missing semantic information and details. The extensive experiments show that our method empowered with inpainting outperforms all state-of-the-art methods.
Depth Monocular Estimation with Attention-based Encoder-Decoder Network from Single Image
Oct 24, 2022



Depth information is the foundation of perception, essential for autonomous driving, robotics, and other source-constrained applications. Promptly obtaining accurate and efficient depth information allows for a rapid response in dynamic environments. Sensor-based methods using LIDAR and RADAR obtain high precision at the cost of high power consumption, price, and volume. While due to advances in deep learning, vision-based approaches have recently received much attention and can overcome these drawbacks. In this work, we explore an extreme scenario in vision-based settings: estimate a depth map from one monocular image severely plagued by grid artifacts and blurry edges. To address this scenario, We first design a convolutional attention mechanism block (CAMB) which consists of channel attention and spatial attention sequentially and insert these CAMBs into skip connections. As a result, our novel approach can find the focus of current image with minimal overhead and avoid losses of depth features. Next, by combining the depth value, the gradients of X axis, Y axis and diagonal directions, and the structural similarity index measure (SSIM), we propose our novel loss function. Moreover, we utilize pixel blocks to accelerate the computation of the loss function. Finally, we show, through comprehensive experiments on two large-scale image datasets, i.e. KITTI and NYU-V2, that our method outperforms several representative baselines.
An Effective Approach for Multi-label Classification with Missing Labels
Oct 24, 2022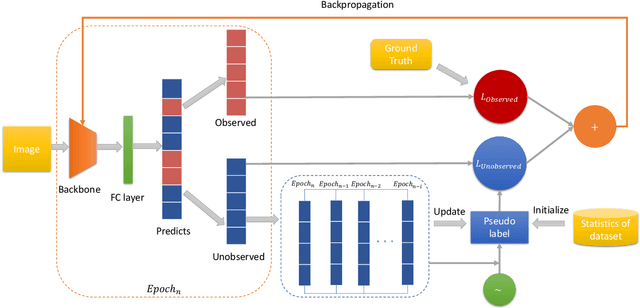
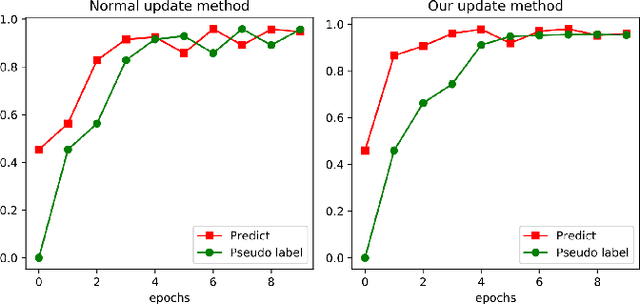
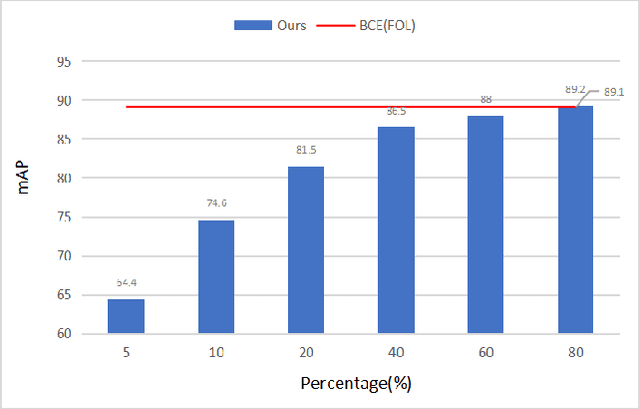
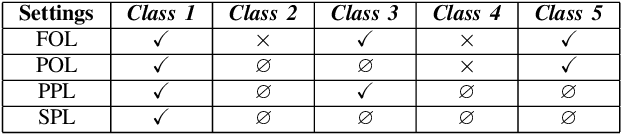
Compared with multi-class classification, multi-label classification that contains more than one class is more suitable in real life scenarios. Obtaining fully labeled high-quality datasets for multi-label classification problems, however, is extremely expensive, and sometimes even infeasible, with respect to annotation efforts, especially when the label spaces are too large. This motivates the research on partial-label classification, where only a limited number of labels are annotated and the others are missing. To address this problem, we first propose a pseudo-label based approach to reduce the cost of annotation without bringing additional complexity to the existing classification networks. Then we quantitatively study the impact of missing labels on the performance of classifier. Furthermore, by designing a novel loss function, we are able to relax the requirement that each instance must contain at least one positive label, which is commonly used in most existing approaches. Through comprehensive experiments on three large-scale multi-label image datasets, i.e. MS-COCO, NUS-WIDE, and Pascal VOC12, we show that our method can handle the imbalance between positive labels and negative labels, while still outperforming existing missing-label learning approaches in most cases, and in some cases even approaches with fully labeled datasets.
G2NetPL: Generic Game-Theoretic Network for Partial-Label Image Classification
Oct 20, 2022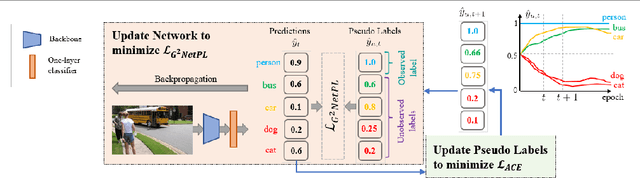
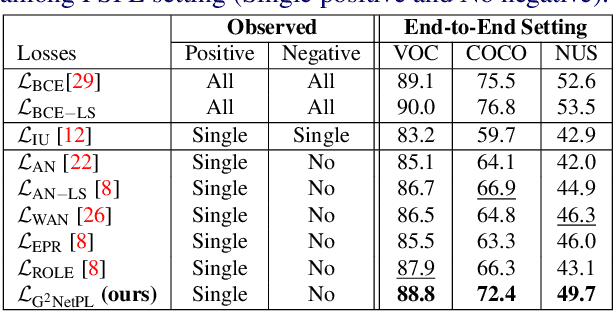
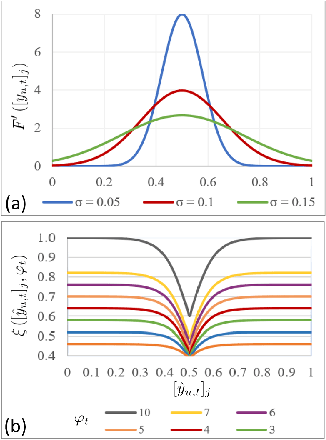
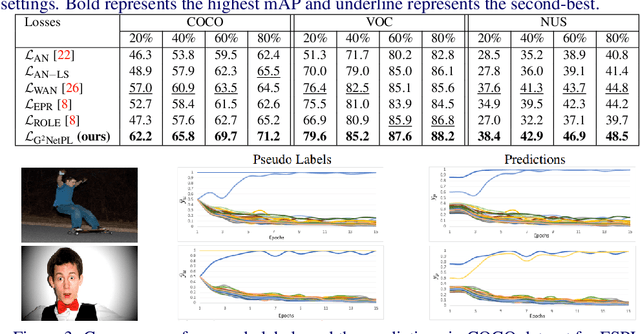
Multi-label image classification aims to predict all possible labels in an image. It is usually formulated as a partial-label learning problem, since it could be expensive in practice to annotate all the labels in every training image. Existing works on partial-label learning focus on the case where each training image is labeled with only a subset of its positive/negative labels. To effectively address partial-label classification, this paper proposes an end-to-end Generic Game-theoretic Network (G2NetPL) for partial-label learning, which can be applied to most partial-label settings, including a very challenging, but annotation-efficient case where only a subset of the training images are labeled, each with only one positive label, while the rest of the training images remain unlabeled. In G2NetPL, each unobserved label is associated with a soft pseudo label, which, together with the network, formulates a two-player non-zero-sum non-cooperative game. The objective of the network is to minimize the loss function with given pseudo labels, while the pseudo labels will seek convergence to 1 (positive) or 0 (negative) with a penalty of deviating from the predicted labels determined by the network. In addition, we introduce a confidence-aware scheduler into the loss of the network to adaptively perform easy-to-hard learning for different labels. Extensive experiments demonstrate that our proposed G2NetPL outperforms many state-of-the-art multi-label classification methods under various partial-label settings on three different datasets.
PLMCL: Partial-Label Momentum Curriculum Learning for Multi-Label Image Classification
Aug 22, 2022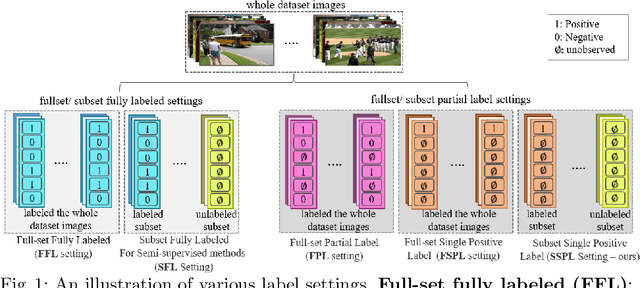
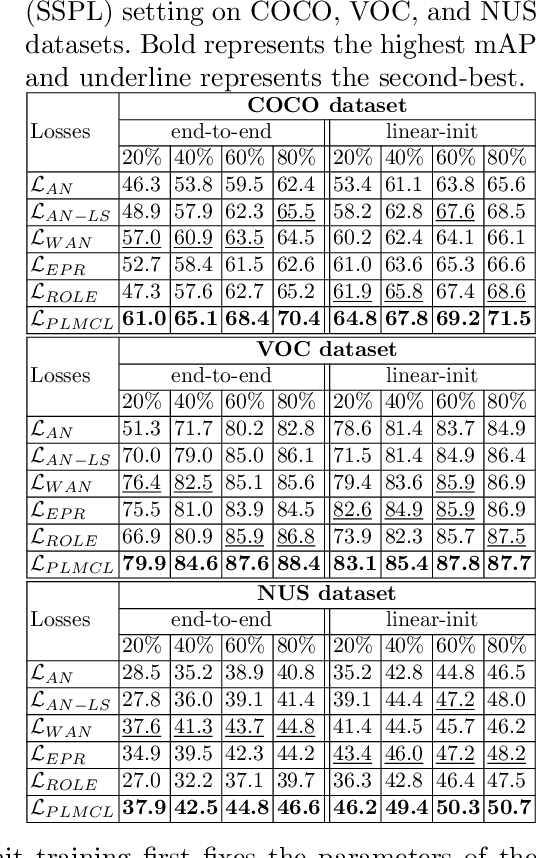
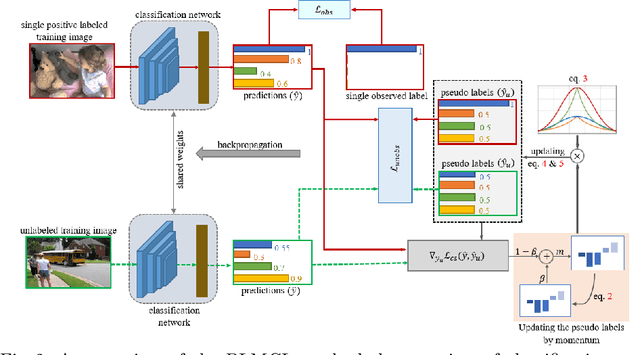
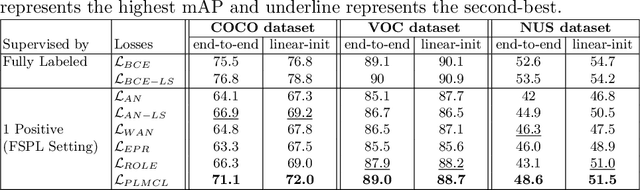
Multi-label image classification aims to predict all possible labels in an image. It is usually formulated as a partial-label learning problem, given the fact that it could be expensive in practice to annotate all labels in every training image. Existing works on partial-label learning focus on the case where each training image is annotated with only a subset of its labels. A special case is to annotate only one positive label in each training image. To further relieve the annotation burden and enhance the performance of the classifier, this paper proposes a new partial-label setting in which only a subset of the training images are labeled, each with only one positive label, while the rest of the training images remain unlabeled. To handle this new setting, we propose an end-to-end deep network, PLMCL (Partial Label Momentum Curriculum Learning), that can learn to produce confident pseudo labels for both partially-labeled and unlabeled training images. The novel momentum-based law updates soft pseudo labels on each training image with the consideration of the updating velocity of pseudo labels, which help avoid trapping to low-confidence local minimum, especially at the early stage of training in lack of both observed labels and confidence on pseudo labels. In addition, we present a confidence-aware scheduler to adaptively perform easy-to-hard learning for different labels. Extensive experiments demonstrate that our proposed PLMCL outperforms many state-of-the-art multi-label classification methods under various partial-label settings on three different datasets.
PLGAN: Generative Adversarial Networks for Power-Line Segmentation in Aerial Images
Apr 14, 2022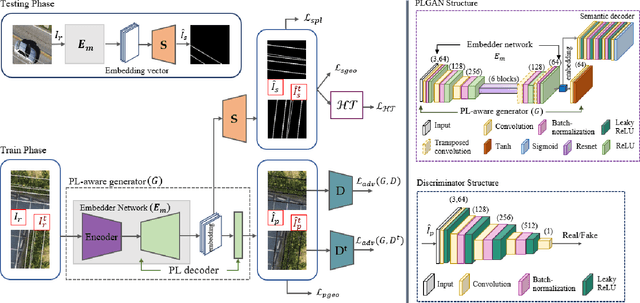

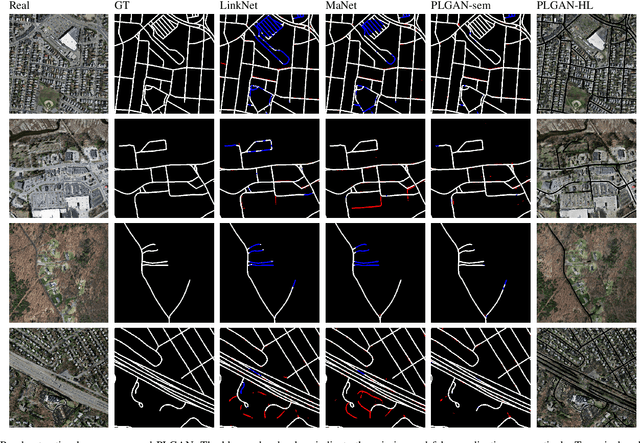
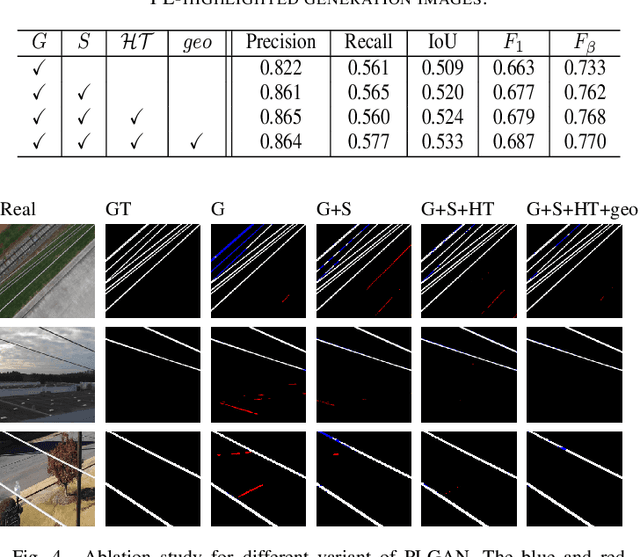
Accurate segmentation of power lines in various aerial images is very important for UAV flight safety. The complex background and very thin structures of power lines, however, make it an inherently difficult task in computer vision. This paper presents PLGAN, a simple yet effective method based on generative adversarial networks, to segment power lines from aerial images with different backgrounds. Instead of directly using the adversarial networks to generate the segmentation, we take their certain decoding features and embed them into another semantic segmentation network by considering more context, geometry, and appearance information of power lines. We further exploit the appropriate form of the generated images for high-quality feature embedding and define a new loss function in the Hough-transform parameter space to enhance the segmentation of very thin power lines. Extensive experiments and comprehensive analysis demonstrate that our proposed PLGAN outperforms the prior state-of-the-art methods for semantic segmentation and line detection.
TTPLA: An Aerial-Image Dataset for Detection and Segmentation of Transmission Towers and Power Lines
Oct 20, 2020
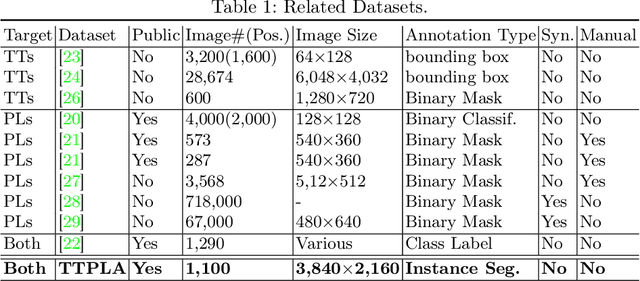

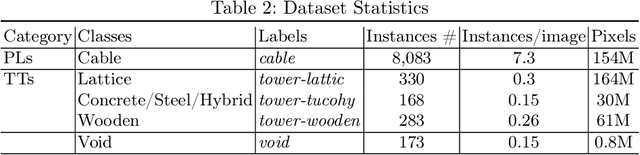
Accurate detection and segmentation of transmission towers~(TTs) and power lines~(PLs) from aerial images plays a key role in protecting power-grid security and low-altitude UAV safety. Meanwhile, aerial images of TTs and PLs pose a number of new challenges to the computer vision researchers who work on object detection and segmentation -- PLs are long and thin, and may show similar color as the background; TTs can be of various shapes and most likely made up of line structures of various sparsity; The background scene, lighting, and object sizes can vary significantly from one image to another. In this paper we collect and release a new TT/PL Aerial-image (TTPLA) dataset, consisting of 1,100 images with the resolution of 3,840$\times$2,160 pixels, as well as manually labeled 8,987 instances of TTs and PLs. We develop novel policies for collecting, annotating, and labeling the images in TTPLA. Different from other relevant datasets, TTPLA supports evaluation of instance segmentation, besides detection and semantic segmentation. To build a baseline for detection and segmentation tasks on TTPLA, we report the performance of several state-of-the-art deep learning models on our dataset. TTPLA dataset is publicly available at https://github.com/r3ab/ttpla_dataset