 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Inpainting for Single-Image Shadow Removal
Paper and Code
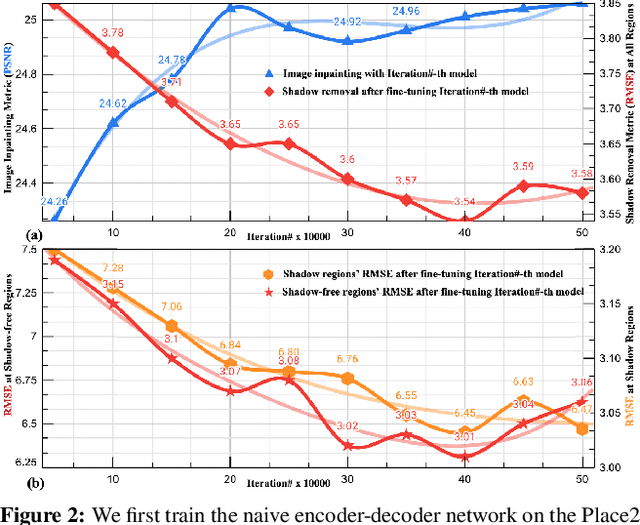
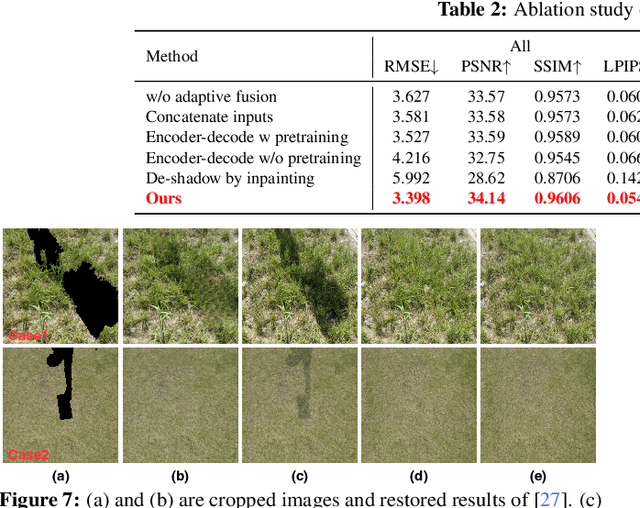
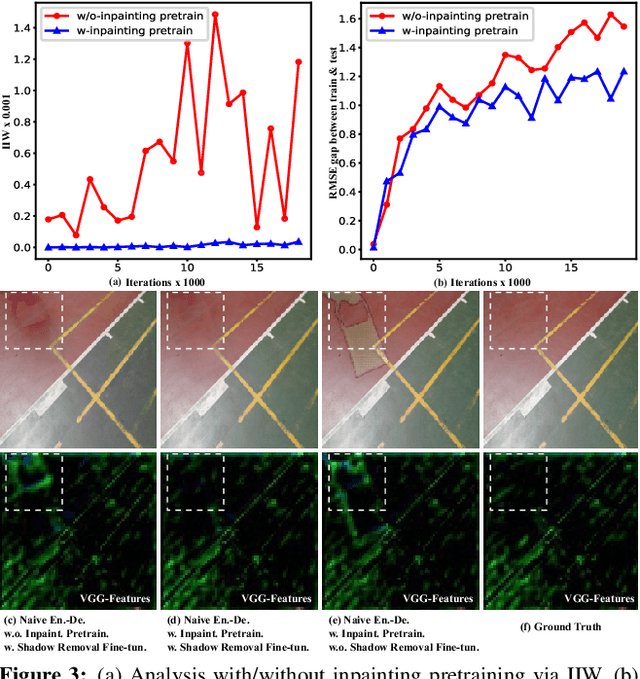
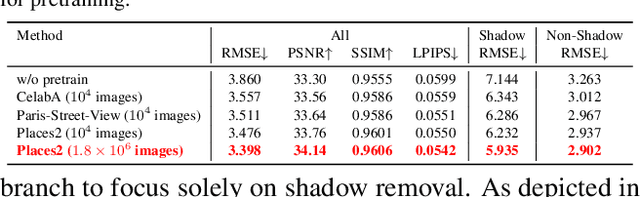
Fully-supervised shadow removal methods achieve top restoration qualities on public datasets but still generate some shadow remnants. One of the reasons is the lack of large-scale shadow & shadow-free image pairs. Unsupervised methods can alleviate the issue but their restoration qualities are much lower than those of fully-supervised methods. In this work, we find that pretraining shadow removal networks on the image inpainting dataset can reduce the shadow remnants significantly: a naive encoder-decoder network gets competitive restoration quality w.r.t. the state-of-the-art methods via only 10% shadow & shadow-free image pairs. We further analyze the difference between networks with/without inpainting pretraining and observe that: inpainting pretraining enhances networks' capability of filling missed semantic information; shadow removal fine-tuning makes the networks know how to fill details of the shadow regions. Inspired by the above observations, we formulate shadow removal as a shadow-guided inpainting task to take advantage of the shadow removal and image inpainting. Specifically, we build a shadow-informed dynamic filtering network with two branches: the image inpainting branch takes the shadow-masked image as input while the second branch takes the shadow image as input and is to estimate dynamic kernels and offsets for the first branch to provide missing semantic information and details. The extensive experiments show that our method empowered with inpainting outperforms all state-of-the-art methods.