 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDUL: CLIP-Driven Unsupervised Learning for Multi-Label Image Classification
Paper and Code
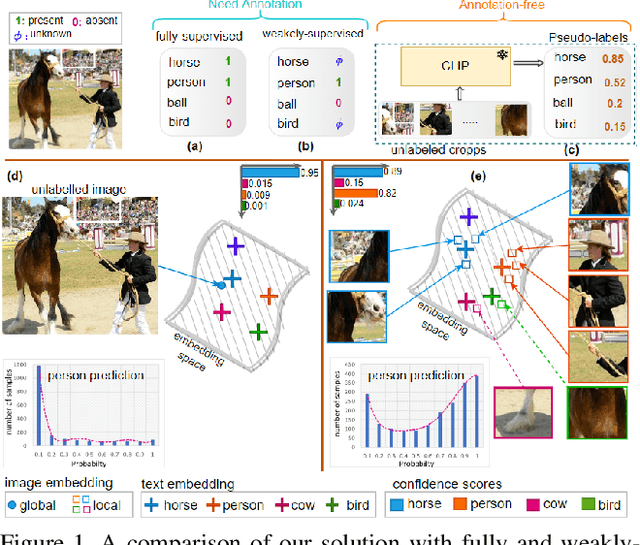
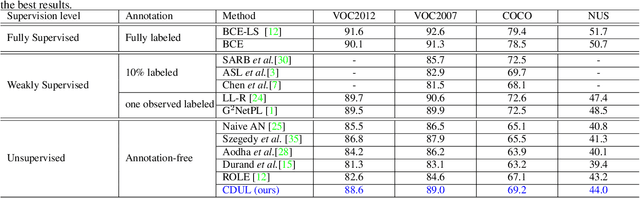
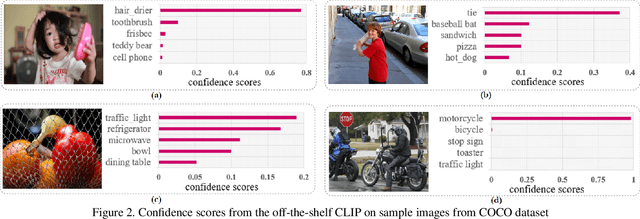

This paper presents a CLIP-based unsupervised learning method for annotation-free multi-label image classification, including three stages: initialization, training, and inference. At the initialization stage, we take full advantage of the powerful CLIP model and propose a novel approach to extend CLIP for multi-label predictions based on global-local image-text similarity aggregation. To be more specific, we split each image into snippets and leverage CLIP to generate the similarity vector for the whole image (global) as well as each snippet (local). Then a similarity aggregator is introduced to leverage the global and local similarity vectors. Using the aggregated similarity scores as the initial pseudo labels at the training stage, we propose an optimization framework to train the parameters of the classification network and refine pseudo labels for unobserved labels. During inference, only the classification network is used to predict the labels of the input image. Extensive experiments show that our method outperforms state-of-the-art unsupervised methods on MS-COCO, PASCAL VOC 2007, PASCAL VOC 2012, and NUS datasets and even achieves comparable results to weakly supervised classification methods.