 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Shadow Generation to Shadow Removal
Mar 24, 2021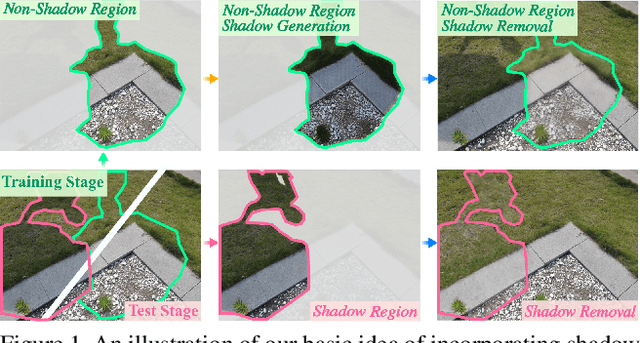
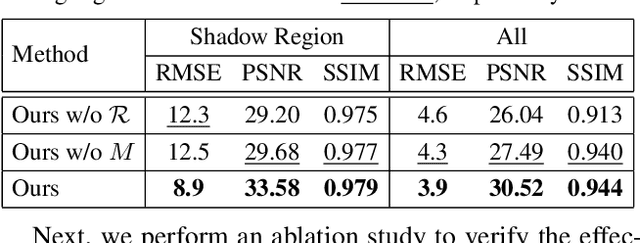
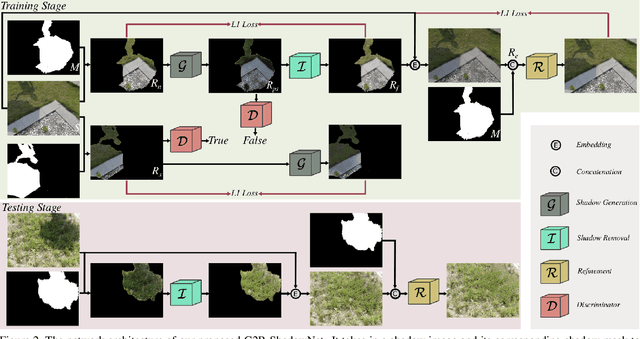
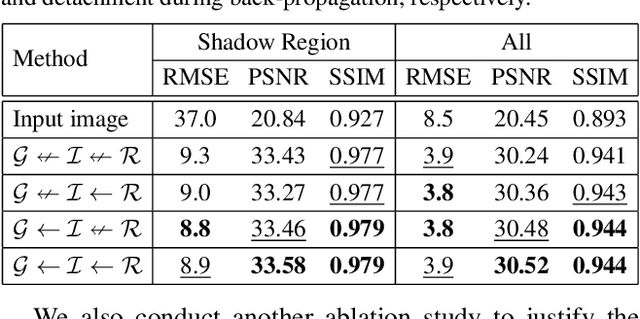
Shadow removal is a computer-vision task that aims to restore the image content in shadow regions. While almost all recent shadow-removal methods require shadow-free images for training, in ECCV 2020 Le and Samaras introduces an innovative approach without this requirement by cropping patches with and without shadows from shadow images as training samples. However, it is still laborious and time-consuming to construct a large amount of such unpaired patches. In this paper, we propose a new G2R-ShadowNet which leverages shadow generation for weakly-supervised shadow removal by only using a set of shadow images and their corresponding shadow masks for training. The proposed G2R-ShadowNet consists of three sub-networks for shadow generation, shadow removal and refinement, respectively and they are jointly trained in an end-to-end fashion. In particular, the shadow generation sub-net stylises non-shadow regions to be shadow ones, leading to paired data for training the shadow-removal sub-net. Extensive experiments on the ISTD dataset and the Video Shadow Removal dataset show that the proposed G2R-ShadowNet achieves competitive performances against the current state of the arts and outperforms Le and Samaras' patch-based shadow-removal method.
Shadow Removal by a Lightness-Guided Network with Training on Unpaired Data
Jun 28, 2020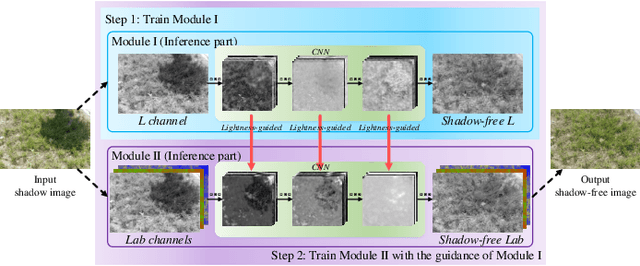
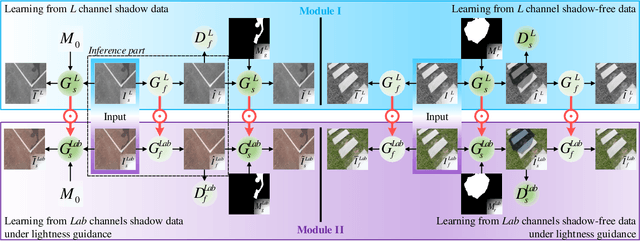
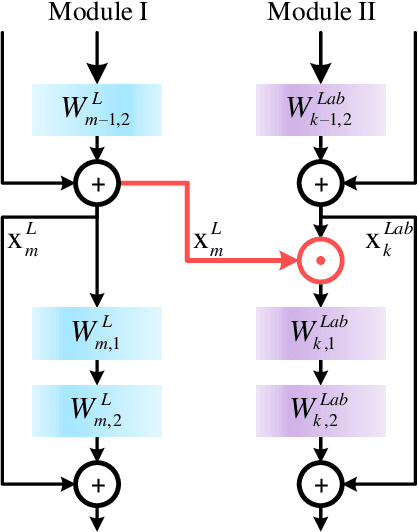
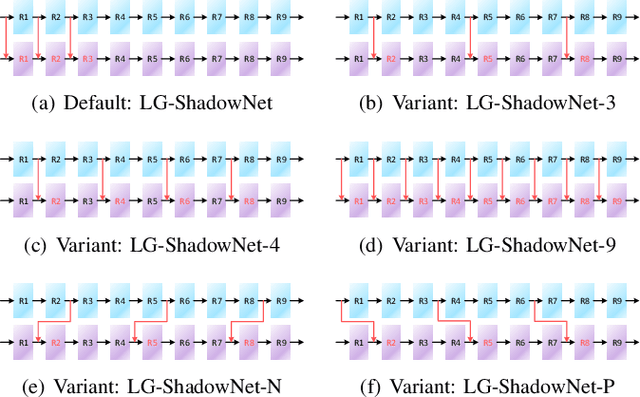
Shadow removal can significantly improve the image visual quality and has many applications in computer vision. Deep learning methods based on CNNs have become the most effective approach for shadow removal by training on either paired data, where both the shadow and underlying shadow-free versions of an image are known, or unpaired data, where shadow and shadow-free training images are totally different with no correspondence. In practice, CNN training on unpaired data is more preferred given the easiness of training data collection. In this paper, we present a new Lightness-Guided Shadow Removal Network (LG-ShadowNet) for shadow removal by training on unpaired data. In this method, we first train a CNN module to compensate for the lightness and then train a second CNN module with the guidance of lightness information from the first CNN module for final shadow removal. We also introduce a loss function to further utilise the colour prior of existing data. Extensive experiments on widely used ISTD, adjusted ISTD and USR datasets demonstrate that the proposed method outperforms the state-of-the-art methods with training on unpaired data.
Understanding and Visualizing Deep Visual Saliency Models
Apr 03, 2019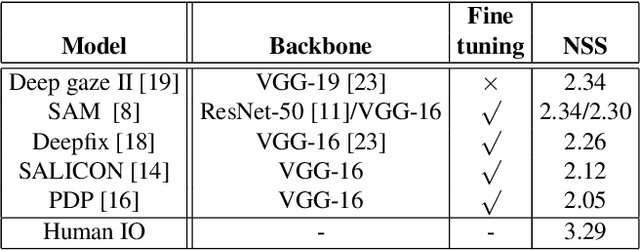
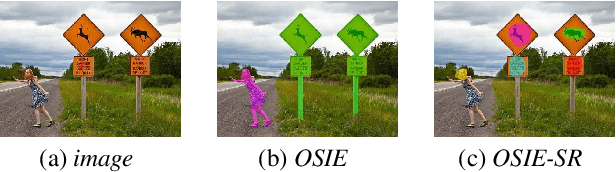

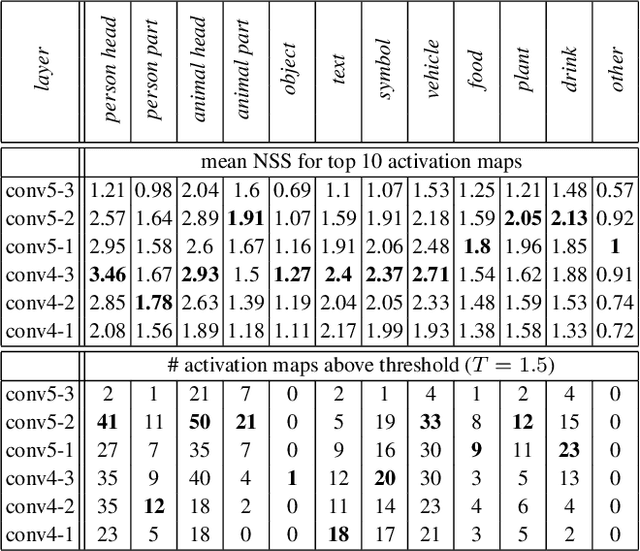
Recently, data-driven deep saliency models have achieved high performance and have outperformed classical saliency models, as demonstrated by results on datasets such as the MIT300 and SALICON. Yet, there remains a large gap between the performance of these models and the inter-human baseline. Some outstanding questions include what have these models learned, how and where they fail, and how they can be improved. This article attempts to answer these questions by analyzing the representations learned by individual neurons located at the intermediate layers of deep saliency models. To this end, we follow the steps of existing deep saliency models, that is borrowing a pre-trained model of object recognition to encode the visual features and learning a decoder to infer the saliency. We consider two cases when the encoder is used as a fixed feature extractor and when it is fine-tuned, and compare the inner representations of the network. To study how the learned representations depend on the task, we fine-tune the same network using the same image set but for two different tasks: saliency prediction versus scene classification. Our analyses reveal that: 1) some visual regions (e.g. head, text, symbol, vehicle) are already encoded within various layers of the network pre-trained for object recognition, 2) using modern datasets, we find that fine-tuning pre-trained models for saliency prediction makes them favor some categories (e.g. head) over some others (e.g. text), 3) although deep models of saliency outperform classical models on natural images, the converse is true for synthetic stimuli (e.g. pop-out search arrays), an evidence of significant difference between human and data-driven saliency models, and 4) we confirm that, after-fine tuning, the change in inner-representations is mostly due to the task and not the domain shift in the data.
What Catches the Eye? Visualizing and Understanding Deep Saliency Models
Mar 22, 2018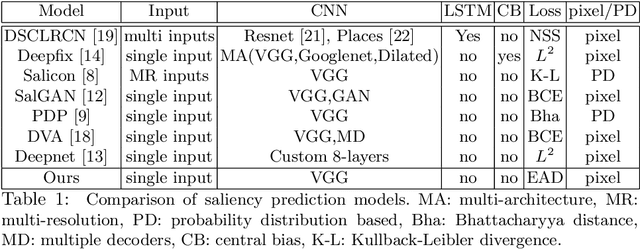
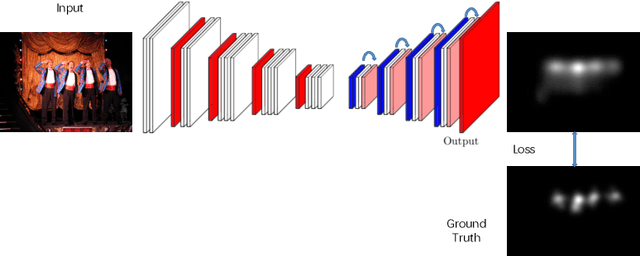
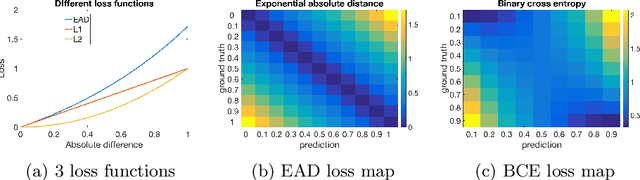
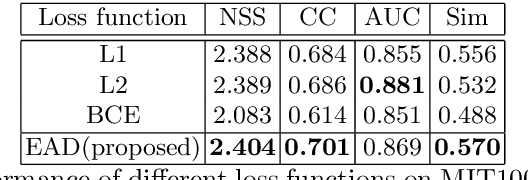
Deep convolutional neural networks have demonstrated high performances for fixation prediction in recent years. How they achieve this, however, is less explored and they remain to be black box models. Here, we attempt to shed light on the internal structure of deep saliency models and study what features they extract for fixation prediction. Specifically, we use a simple yet powerful architecture, consisting of only one CNN and a single resolution input, combined with a new loss function for pixel-wise fixation prediction during free viewing of natural scenes. We show that our simple method is on par or better than state-of-the-art complicated saliency models. Furthermore, we propose a method, related to saliency model evaluation metrics, to visualize deep models for fixation prediction. Our method reveals the inner representations of deep models for fixation prediction and provides evidence that saliency, as experienced by humans, is likely to involve high-level semantic knowledge in addition to low-level perceptual cues. Our results can be useful to measure the gap between current saliency models and the human inter-observer model and to build new models to close this gap.
Aggregated Sparse Attention for Steering Angle Prediction
Mar 15, 2018



In this paper, we apply the attention mechanism to autonomous driving for steering angle prediction. We propose the first model, applying the recently introduced sparse attention mechanism to visual domain, as well as the aggregated extension for this model. We show the improvement of the proposed method, comparing to no attention as well as to different types of attention.
Action Recognition with Coarse-to-Fine Deep Feature Integration and Asynchronous Fusion
Nov 20, 2017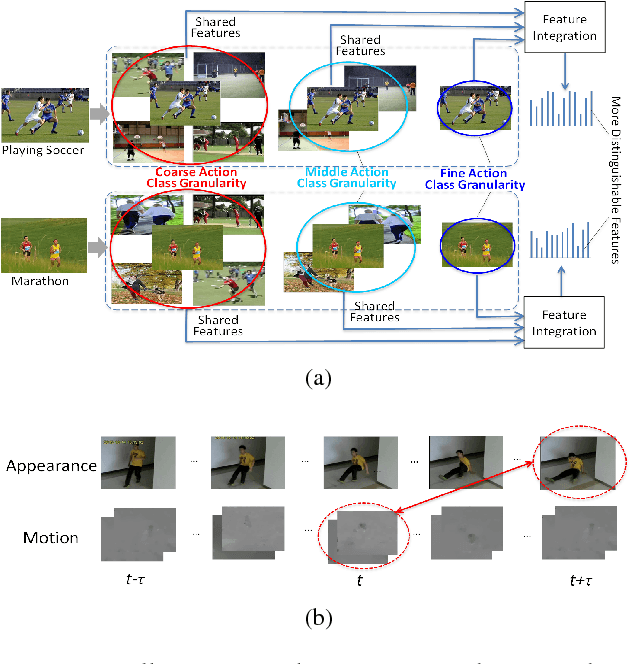
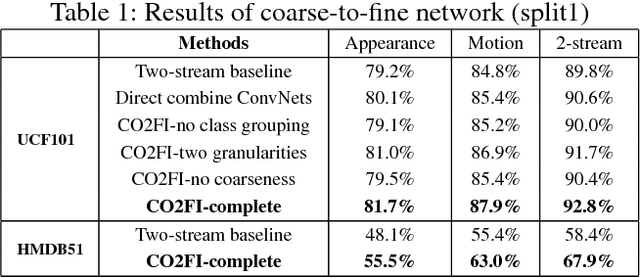
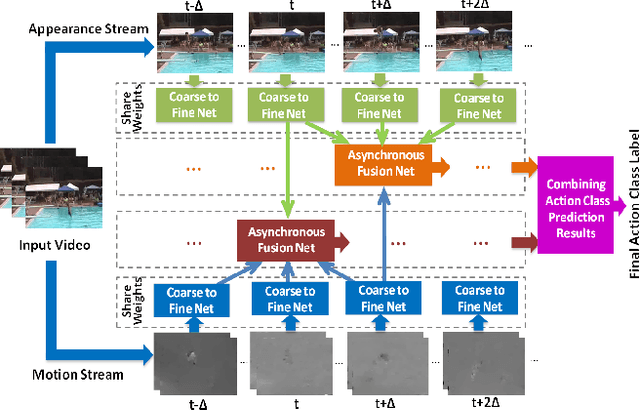

Action recognition is an important yet challenging task in computer vision. In this paper, we propose a novel deep-based framework for action recognition, which improves the recognition accuracy by: 1) deriving more precise features for representing actions, and 2) reducing the asynchrony between different information streams. We first introduce a coarse-to-fine network which extracts shared deep features at different action class granularities and progressively integrates them to obtain a more accurate feature representation for input actions. We further introduce an asynchronous fusion network. It fuses information from different streams by asynchronously integrating stream-wise features at different time points, hence better leveraging the complementary information in different streams. Experimental results on action recognition benchmarks demonstrate that our approach achieves the state-of-the-art performance.
A diffusion and clustering-based approach for finding coherent motions and understanding crowd scenes
Feb 16, 2016
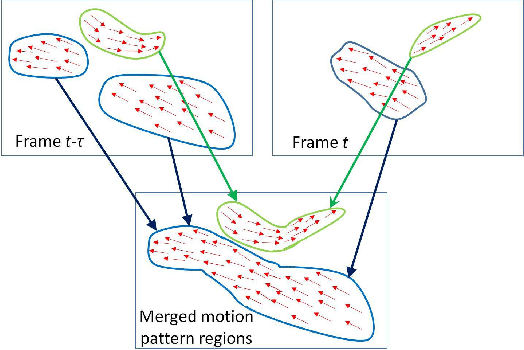
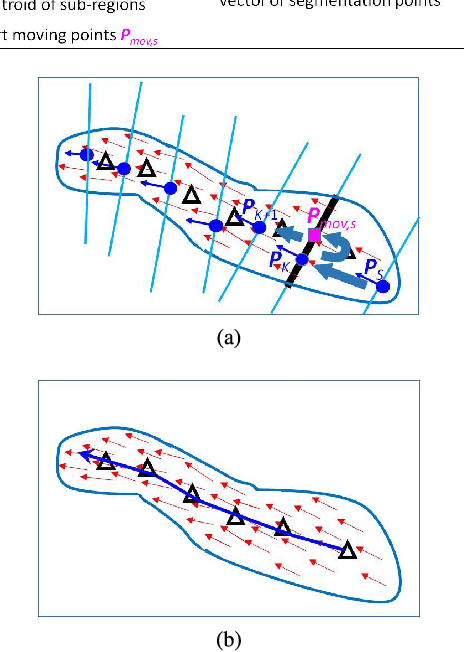

This paper addresses the problem of detecting coherent motions in crowd scenes and presents its two applications in crowd scene understanding: semantic region detection and recurrent activity mining. It processes input motion fields (e.g., optical flow fields) and produces a coherent motion filed, named as thermal energy field. The thermal energy field is able to capture both motion correlation among particles and the motion trends of individual particles which are helpful to discover coherency among them. We further introduce a two-step clustering process to construct stable semantic regions from the extracted time-varying coherent motions. These semantic regions can be used to recognize pre-defined activities in crowd scenes. Finally, we introduce a cluster-and-merge process which automatically discovers recurrent activities in crowd scenes by clustering and merging the extracted coherent motions. Experiments on various videos demonstrate the effectiveness of our approach.