 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChainFlow-VLA: Causal Flow Planning with Vision-Language Models
May 22, 2026Current end-to-end autonomous driving systems are fundamentally limited by a mismatch between temporal causal reasoning and global trajectory consistency. Autoregressive (AR) models capture interaction-aware temporal dependencies via causal factorization, but their step-wise decoding leads to error accumulation and suboptimal global structure. In contrast, diffusion models optimize trajectories globally but lack explicit causal constraints, making them unreliable in interactive and safety-critical scenarios. This dichotomy reveals a deeper issue: existing methods treat causal modeling and global optimization as separate paradigms, without a principled way to unify them within a single trajectory distribution. To address this, we propose ChainFlow-VLA, which unifies causal generation and global refinement within a unified probabilistic framework. We formulate planning as a mixture over AR-induced modes and learn Vision-Language Model (VLM)-conditioned residual distributions over these modes. An autoregressive generator (Chain) produces a discrete set of causal trajectory modes, followed by a diffusion-based refiner (Flow) that leverages VLM hidden states as semantic priors to perform mode-conditioned correction in residual space while preserving causal structure. This straightforward conditioning seamlessly injects high-level scene understanding into fine-grained trajectory adjustments. Experiments demonstrate that ChainFlow-VLA achieves robust planning in ambiguous and long-tail scenarios, achieving a state-of-the-art score of 94.85 on the NAVSIM v1 leaderboard, matching human-level performance (94.8). Code will be available at https://github.com/AFARI-Research/ChainFlow-VLA.
CoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving
May 11, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for end-to-end autonomous driving. However, existing reasoning mechanisms still struggle to provide planning-oriented intermediate representations: textual Chain-of-Thought (CoT) fails to preserve continuous spatiotemporal structure, while latent world reasoning remains difficult to use as a direct condition for action generation. In this paper, we propose CoWorld-VLA, a multi-expert world reasoning framework for autonomous driving, where world representations serve as explicit conditions to guide action planning. CoWorld-VLA extracts complementary world information through multi-source supervision and encodes it into expert tokens within the VLA, thereby providing planner-accessible conditioning signals. Specifically, we construct four types of tokens: semantic interaction, geometric structure, dynamic evolution, and ego trajectory tokens, which respectively model interaction intent, spatial structure, future temporal dynamics, and behavioral goals. During action generation, CoWorld-VLA employs a diffusion-based hierarchical multi-expert fusion planner, which is coupled with scene context throughout the joint denoising process to generate continuous ego trajectories. Experiments show that CoWorld-VLA achieves competitive results in both future scene generation and planning on the NAVSIM v1 benchmark, demonstrating strong performance in collision avoidance and trajectory accuracy. Ablation studies further validate the complementarity of expert tokens and their effectiveness as planning conditions for action generation. Code will be available at https://github.com/potatochip1211/CoWorld-VLA.
Any 3D Scene is Worth 1K Tokens: 3D-Grounded Representation for Scene Generation at Scale
Apr 13, 20263D scene generation has long been dominated by 2D multi-view or video diffusion models. This is due not only to the lack of scene-level 3D latent representation, but also to the fact that most scene-level 3D visual data exists in the form of multi-view images or videos, which are naturally compatible with 2D diffusion architectures. Typically, these 2D-based approaches degrade 3D spatial extrapolation to 2D temporal extension, which introduces two fundamental issues: (i) representing 3D scenes via 2D views leads to significant representation redundancy, and (ii) latent space rooted in 2D inherently limits the spatial consistency of the generated 3D scenes. In this paper, we propose, for the first time, to perform 3D scene generation directly within an implicit 3D latent space to address these limitations. First, we repurpose frozen 2D representation encoders to construct our 3D Representation Autoencoder (3DRAE), which grounds view-coupled 2D semantic representations into a view-decoupled 3D latent representation. This enables representing 3D scenes observed from arbitrary numbers of views--at any resolution and aspect ratio--with fixed complexity and rich semantics. Then we introduce 3D Diffusion Transformer (3DDiT), which performs diffusion modeling in this 3D latent space, achieving remarkably efficient and spatially consistent 3D scene generation while supporting diverse conditioning configurations. Moreover, since our approach directly generates a 3D scene representation, it can be decoded to images and optional point maps along arbitrary camera trajectories without requiring per-trajectory diffusion sampling pass, which is common in 2D-based approaches.
Autoregressive Meta-Actions for Unified Controllable Trajectory Generation
May 29, 2025



Controllable trajectory generation guided by high-level semantic decisions, termed meta-actions, is crucial for autonomous driving systems. A significant limitation of existing frameworks is their reliance on invariant meta-actions assigned over fixed future time intervals, causing temporal misalignment with the actual behavior trajectories. This misalignment leads to irrelevant associations between the prescribed meta-actions and the resulting trajectories, disrupting task coherence and limiting model performance. To address this challenge, we introduce Autoregressive Meta-Actions, an approach integrated into autoregressive trajectory generation frameworks that provides a unified and precise definition for meta-action-conditioned trajectory prediction. Specifically, We decompose traditional long-interval meta-actions into frame-level meta-actions, enabling a sequential interplay between autoregressive meta-action prediction and meta-action-conditioned trajectory generation. This decomposition ensures strict alignment between each trajectory segment and its corresponding meta-action, achieving a consistent and unified task formulation across the entire trajectory span and significantly reducing complexity. Moreover, we propose a staged pre-training process to decouple the learning of basic motion dynamics from the integration of high-level decision control, which offers flexibility, stability, and modularity. Experimental results validate our framework's effectiveness, demonstrating improved trajectory adaptivity and responsiveness to dynamic decision-making scenarios. We provide the video document and dataset, which are available at https://arma-traj.github.io/.
DRoPE: Directional Rotary Position Embedding for Efficient Agent Interaction Modeling
Mar 19, 2025Accurate and efficient modeling of agent interactions is essential for trajectory generation, the core of autonomous driving systems. Existing methods, scene-centric, agent-centric, and query-centric frameworks, each present distinct advantages and drawbacks, creating an impossible triangle among accuracy, computational time, and memory efficiency. To break this limitation, we propose Directional Rotary Position Embedding (DRoPE), a novel adaptation of Rotary Position Embedding (RoPE), originally developed in natural language processing. Unlike traditional relative position embedding (RPE), which introduces significant space complexity, RoPE efficiently encodes relative positions without explicitly increasing complexity but faces inherent limitations in handling angular information due to periodicity. DRoPE overcomes this limitation by introducing a uniform identity scalar into RoPE's 2D rotary transformation, aligning rotation angles with realistic agent headings to naturally encode relative angular information. We theoretically analyze DRoPE's correctness and efficiency, demonstrating its capability to simultaneously optimize trajectory generation accuracy, time complexity, and space complexity. Empirical evaluations compared with various state-of-the-art trajectory generation models, confirm DRoPE's good performance and significantly reduced space complexity, indicating both theoretical soundness and practical effectiveness. The video documentation is available at https://drope-traj.github.io/.
KiGRAS: Kinematic-Driven Generative Model for Realistic Agent Simulation
Jul 17, 2024Trajectory generation is a pivotal task in autonomous driving. Recent studies have introduced the autoregressive paradigm, leveraging the state transition model to approximate future trajectory distributions. This paradigm closely mirrors the real-world trajectory generation process and has achieved notable success. However, its potential is limited by the ineffective representation of realistic trajectories within the redundant state space. To address this limitation, we propose the Kinematic-Driven Generative Model for Realistic Agent Simulation (KiGRAS). Instead of modeling in the state space, KiGRAS factorizes the driving scene into action probability distributions at each time step, providing a compact space to represent realistic driving patterns. By establishing physical causality from actions (cause) to trajectories (effect) through the kinematic model, KiGRAS eliminates massive redundant trajectories. All states derived from actions in the cause space are constrained to be physically feasible. Furthermore, redundant trajectories representing identical action sequences are mapped to the same representation, reflecting their underlying actions. This approach significantly reduces task complexity and ensures physical feasibility. KiGRAS achieves state-of-the-art performance in Waymo's SimAgents Challenge, ranking first on the WOMD leaderboard with significantly fewer parameters than other models. The video documentation is available at \url{https://kigras-mach.github.io/KiGRAS/}.
StreamMOTP: Streaming and Unified Framework for Joint 3D Multi-Object Tracking and Trajectory Prediction
Jun 28, 20243D multi-object tracking and trajectory prediction are two crucial modules in autonomous driving systems. Generally, the two tasks are handled separately in traditional paradigms and a few methods have started to explore modeling these two tasks in a joint manner recently. However, these approaches suffer from the limitations of single-frame training and inconsistent coordinate representations between tracking and prediction tasks. In this paper, we propose a streaming and unified framework for joint 3D Multi-Object Tracking and trajectory Prediction (StreamMOTP) to address the above challenges. Firstly, we construct the model in a streaming manner and exploit a memory bank to preserve and leverage the long-term latent features for tracked objects more effectively. Secondly, a relative spatio-temporal positional encoding strategy is introduced to bridge the gap of coordinate representations between the two tasks and maintain the pose-invariance for trajectory prediction. Thirdly, we further improve the quality and consistency of predicted trajectories with a dual-stream predictor. We conduct extensive experiments on popular nuSences dataset and the experimental results demonstrate the effectiveness and superiority of StreamMOTP, which outperforms previous methods significantly on both tasks. Furthermore, we also prove that the proposed framework has great potential and advantages in actual applications of autonomous driving.
SparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.
MacFormer: Map-Agent Coupled Transformer for Real-time and Robust Trajectory Prediction
Aug 31, 2023Predicting the future behavior of agents is a fundamental task in autonomous vehicle domains. Accurate prediction relies on comprehending the surrounding map, which significantly regularizes agent behaviors. However, existing methods have limitations in exploiting the map and exhibit a strong dependence on historical trajectories, which yield unsatisfactory prediction performance and robustness. Additionally, their heavy network architectures impede real-time applications. To tackle these problems, we propose Map-Agent Coupled Transformer (MacFormer) for real-time and robust trajectory prediction. Our framework explicitly incorporates map constraints into the network via two carefully designed modules named coupled map and reference extractor. A novel multi-task optimization strategy (MTOS) is presented to enhance learning of topology and rule constraints. We also devise bilateral query scheme in context fusion for a more efficient and lightweight network. We evaluated our approach on Argoverse 1, Argoverse 2, and nuScenes real-world benchmarks, where it all achieved state-of-the-art performance with the lowest inference latency and smallest model size. Experiments also demonstrate that our framework is resilient to imperfect tracklet inputs. Furthermore, we show that by combining with our proposed strategies, classical models outperform their baselines, further validating the versatility of our framework.
A Rotation Meanout Network with Invariance for Dermoscopy Image Classification and Retrieval
Aug 01, 2022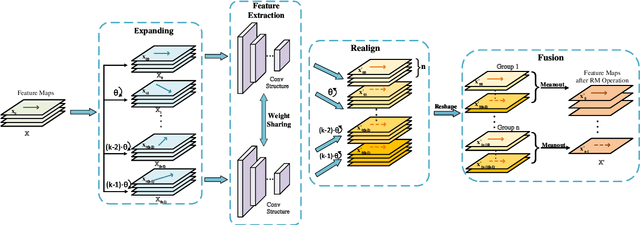
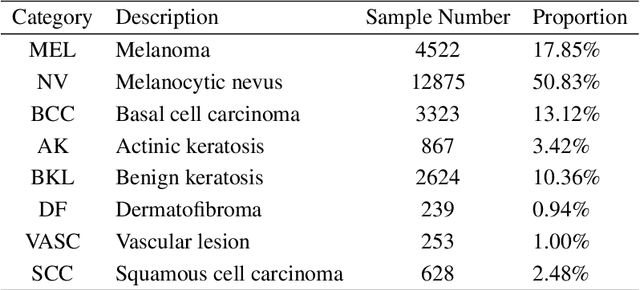


The computer-aided diagnosis (CAD) system can provide a reference basis for the clinical diagnosis of skin diseases. Convolutional neural networks (CNNs) can not only extract visual elements such as colors and shapes but also semantic features. As such they have made great improvements in many tasks of dermoscopy images. The imaging of dermoscopy has no main direction, indicating that there are a large number of skin lesion target rotations in the datasets. However, CNNs lack anti-rotation ability, which is bound to affect the feature extraction ability of CNNs. We propose a rotation meanout (RM) network to extract rotation invariance features from dermoscopy images. In RM, each set of rotated feature maps corresponds to a set of weight-sharing convolution outputs and they are fused using meanout operation to obtain the final feature maps. Through theoretical derivation, the proposed RM network is rotation-equivariant and can extract rotation-invariant features when being followed by the global average pooling (GAP) operation. The extracted rotation-invariant features can better represent the original data in classification and retrieval tasks for dermoscopy images. The proposed RM is a general operation, which does not change the network structure or increase any parameter, and can be flexibly embedded in any part of CNNs. Extensive experiments are conducted on a dermoscopy image dataset. The results show our method outperforms other anti-rotation methods and achieves great improvements in dermoscopy image classification and retrieval tasks, indicating the potential of rotation invariance in the field of dermoscopy images.