 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeFedLLM: Efficient LLM Inference Based on Federated Learning
Nov 24, 2024



Large Language Models (LLMs) herald a transformative era in artificial intelligence (AI). However, the expansive scale of data and parameters of LLMs requires high-demand computational and memory resources, restricting their accessibility to a broader range of users and researchers. This paper introduces an effective approach that enhances the operational efficiency and affordability of LLM inference. By utilizing transformer-based federated learning (FL) with model-parallel distributed training, our model efficiently distributes the computational loads and memory requirements across a network of participants. This strategy permits users, especially those with limited resources to train state-of-the-art LLMs collaboratively. We also innovate an incentive mechanism within the FL framework, rewarding constructive contributions and filtering out malicious activities, thereby safeguarding the integrity and reliability of the training process. Concurrently, we leverage memory hierarchy strategies and Singular Value Decomposition (SVD) on weight matrices to boost computational and memory efficiencies further. Our results, derived from formulaic analyses and numerical calculations, demonstrate significant optimization of resource use and democratize access to cutting-edge LLMs, ensuring that a wide scale of users can both contribute to and benefit from these advanced models.
CFSafety: Comprehensive Fine-grained Safety Assessment for LLMs
Oct 29, 2024As large language models (LLMs) rapidly evolve, they bring significant conveniences to our work and daily lives, but also introduce considerable safety risks. These models can generate texts with social biases or unethical content, and under specific adversarial instructions, may even incite illegal activities. Therefore, rigorous safety assessments of LLMs are crucial. In this work, we introduce a safety assessment benchmark, CFSafety, which integrates 5 classic safety scenarios and 5 types of instruction attacks, totaling 10 categories of safety questions, to form a test set with 25k prompts. This test set was used to evaluate the natural language generation (NLG) capabilities of LLMs, employing a combination of simple moral judgment and a 1-5 safety rating scale for scoring. Using this benchmark, we tested eight popular LLMs, including the GPT series. The results indicate that while GPT-4 demonstrated superior safety performance, the safety effectiveness of LLMs, including this model, still requires improvement. The data and code associated with this study are available on GitHub.
Knowledge in Superposition: Unveiling the Failures of Lifelong Knowledge Editing for Large Language Models
Aug 14, 2024



Knowledge editing aims to update outdated or incorrect knowledge in large language models (LLMs). However, current knowledge editing methods have limited scalability for lifelong editing. This study explores the fundamental reason why knowledge editing fails in lifelong editing. We begin with the closed-form solution derived from linear associative memory, which underpins state-of-the-art knowledge editing methods. We extend the solution from single editing to lifelong editing, and through rigorous mathematical derivation, identify an interference term in the final solution, suggesting that editing knowledge may impact irrelevant knowledge. Further analysis of the interference term reveals a close relationship with superposition between knowledge representations. When knowledge superposition does not exist in language models, the interference term vanishes, allowing for lossless knowledge editing. Experiments across numerous language models reveal that knowledge superposition is universal, exhibiting high kurtosis, zero mean, and heavy-tailed distributions with clear scaling laws. Ultimately, by combining theory and experiments, we demonstrate that knowledge superposition is the fundamental reason for the failure of lifelong editing. Moreover, this is the first study to investigate knowledge editing from the perspective of superposition and provides a comprehensive observation of superposition across numerous real-world language models. Code available at https://github.com/ChenhuiHu/knowledge_in_superposition.
Exploring Vulnerabilities and Protections in Large Language Models: A Survey
Jun 01, 2024

As Large Language Models (LLMs) increasingly become key components in various AI applications, understanding their security vulnerabilities and the effectiveness of defense mechanisms is crucial. This survey examines the security challenges of LLMs, focusing on two main areas: Prompt Hacking and Adversarial Attacks, each with specific types of threats. Under Prompt Hacking, we explore Prompt Injection and Jailbreaking Attacks, discussing how they work, their potential impacts, and ways to mitigate them. Similarly, we analyze Adversarial Attacks, breaking them down into Data Poisoning Attacks and Backdoor Attacks. This structured examination helps us understand the relationships between these vulnerabilities and the defense strategies that can be implemented. The survey highlights these security challenges and discusses robust defensive frameworks to protect LLMs against these threats. By detailing these security issues, the survey contributes to the broader discussion on creating resilient AI systems that can resist sophisticated attacks.
WilKE: Wise-Layer Knowledge Editor for Lifelong Knowledge Editing
Feb 16, 2024



Knowledge editing aims to rectify inaccuracies in large language models (LLMs) without costly retraining for outdated or erroneous knowledge. However, current knowledge editing methods primarily focus on single editing, failing to meet the requirements for lifelong editing. In this paper, lifelong editing is synonymous with lifelong knowledge editing. This study reveals a performance degradation encountered by knowledge editing in lifelong editing, characterized by toxicity buildup and toxicity flash, with the primary cause identified as pattern unmatch. We introduce a knowledge editing approach named WilKE, which selects editing layer based on the pattern matching degree of editing knowledge across different layers. Experimental results demonstrate that, in lifelong editing, WilKE exhibits an average improvement of 46.2\% and 67.8\% on editing GPT2-XL and GPT-J relative to state-of-the-art knowledge editing methods.
Enhancing E-Commerce Recommendation using Pre-Trained Language Model and Fine-Tuning
Feb 09, 2023
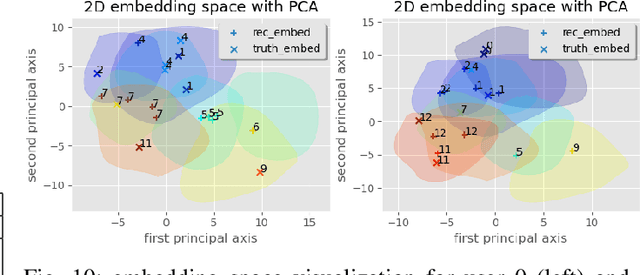

Pretrained Language Models (PLM) have been greatly successful on a board range of natural language processing (NLP) tasks. However, it has just started being applied to the domain of recommendation systems. Traditional recommendation algorithms failed to incorporate the rich textual information in e-commerce datasets, which hinderss the performance of those models. We present a thorough investigation on the effect of various strategy of incorporating PLMs into traditional recommender algorithms on one of the e-commerce datasets, and we compare the results with vanilla recommender baseline models. We show that the application of PLMs and domain specific fine-tuning lead to an increase on the predictive capability of combined models. These results accentuate the importance of utilizing textual information in the context of e-commerce, and provides insight on how to better apply PLMs alongside traditional recommender system algorithms. The code used in this paper is available on Github: https://github.com/NuofanXu/bert_retail_recommender.
An Investigation of Smart Contract for Collaborative Machine Learning Model Training
Sep 12, 2022
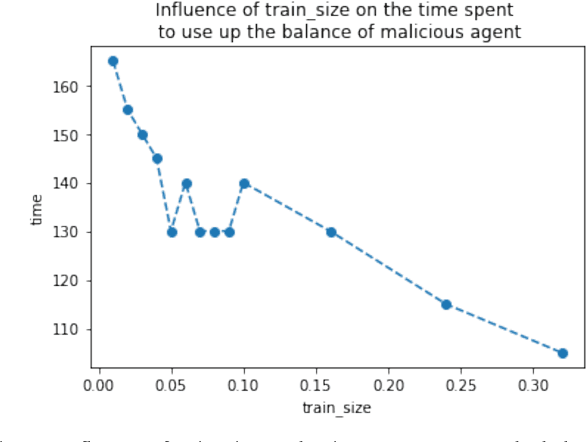
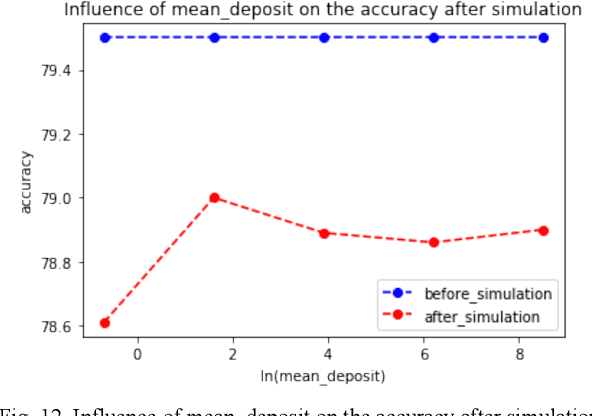
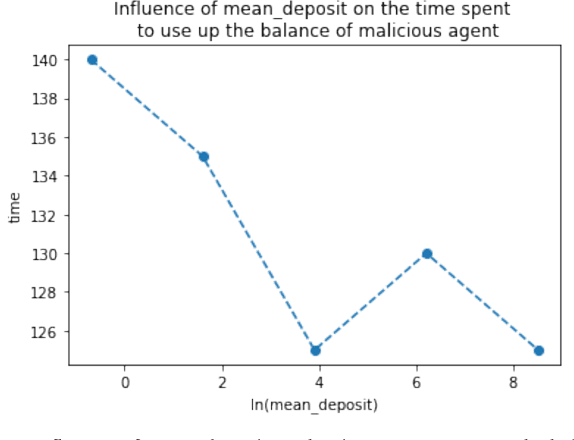
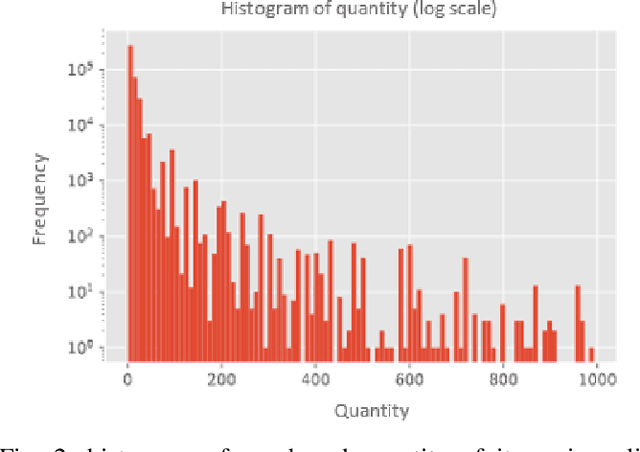
Machine learning (ML) has penetrated various fields in the era of big data. The advantage of collaborative machine learning (CML) over most conventional ML lies in the joint effort of decentralized nodes or agents that results in better model performance and generalization. As the training of ML models requires a massive amount of good quality data, it is necessary to eliminate concerns about data privacy and ensure high-quality data. To solve this problem, we cast our eyes on the integration of CML and smart contracts. Based on blockchain, smart contracts enable automatic execution of data preserving and validation, as well as the continuity of CML model training. In our simulation experiments, we define incentive mechanisms on the smart contract, investigate the important factors such as the number of features in the dataset (num_words), the size of the training data, the cost for the data holders to submit data, etc., and conclude how these factors impact the performance metrics of the model: the accuracy of the trained model, the gap between the accuracies of the model before and after simulation, and the time to use up the balance of bad agent. For instance, the increase of the value of num_words leads to higher model accuracy and eliminates the negative influence of malicious agents in a shorter time from our observation of the experiment results. Statistical analyses show that with the help of smart contracts, the influence of invalid data is efficiently diminished and model robustness is maintained. We also discuss the gap in existing research and put forward possible future directions for further works.
Survey on the Convergence of Machine Learning and Blockchain
Jan 04, 2022
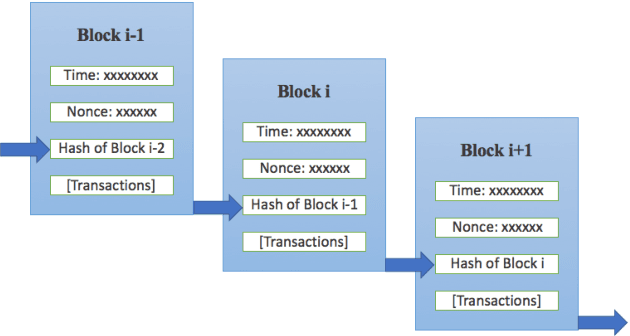

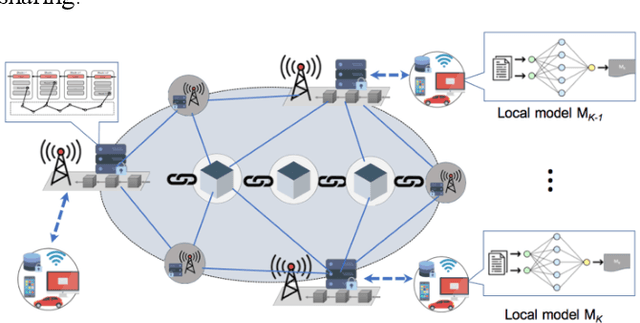
Machine learning (ML) has been pervasively researched nowadays and it has been applied in many aspects of real life. Nevertheless, issues of model and data still accompany the development of ML. For instance, training of traditional ML models is limited to the access of data sets, which are generally proprietary; published ML models may soon be out of date without update of new data and continuous training; malicious data contributors may upload wrongly labeled data that leads to undesirable training results; and the abuse of private data and data leakage also exit. With the utilization of blockchain, an emerging and swiftly developing technology, these problems can be efficiently solved. In this paper, we conduct a survey of the convergence of collaborative ML and blockchain. We investigate different ways of combination of these two technologies, and their fields of application. We also discuss the limitations of current research and their future directions.