 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeFedLLM: Efficient LLM Inference Based on Federated Learning
Nov 24, 2024



Large Language Models (LLMs) herald a transformative era in artificial intelligence (AI). However, the expansive scale of data and parameters of LLMs requires high-demand computational and memory resources, restricting their accessibility to a broader range of users and researchers. This paper introduces an effective approach that enhances the operational efficiency and affordability of LLM inference. By utilizing transformer-based federated learning (FL) with model-parallel distributed training, our model efficiently distributes the computational loads and memory requirements across a network of participants. This strategy permits users, especially those with limited resources to train state-of-the-art LLMs collaboratively. We also innovate an incentive mechanism within the FL framework, rewarding constructive contributions and filtering out malicious activities, thereby safeguarding the integrity and reliability of the training process. Concurrently, we leverage memory hierarchy strategies and Singular Value Decomposition (SVD) on weight matrices to boost computational and memory efficiencies further. Our results, derived from formulaic analyses and numerical calculations, demonstrate significant optimization of resource use and democratize access to cutting-edge LLMs, ensuring that a wide scale of users can both contribute to and benefit from these advanced models.
An Investigation of Smart Contract for Collaborative Machine Learning Model Training
Sep 12, 2022
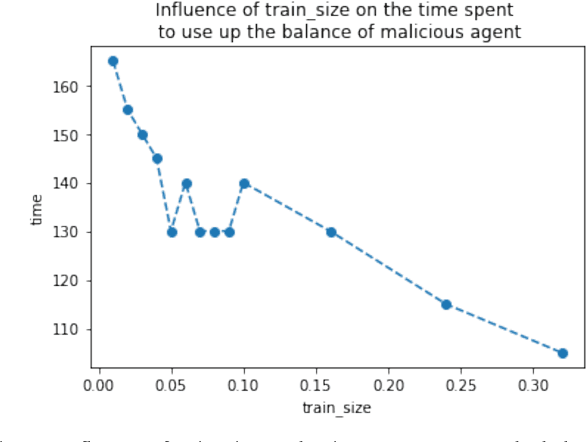
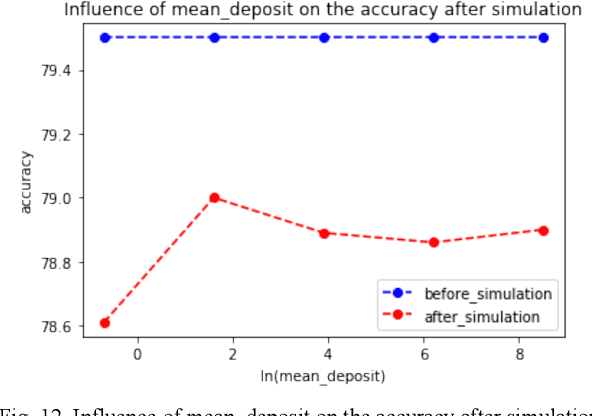
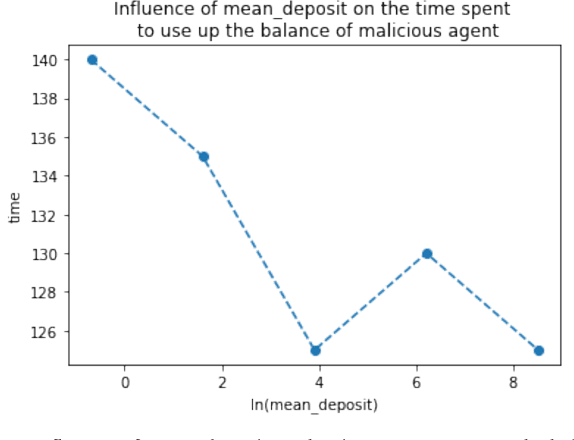
Machine learning (ML) has penetrated various fields in the era of big data. The advantage of collaborative machine learning (CML) over most conventional ML lies in the joint effort of decentralized nodes or agents that results in better model performance and generalization. As the training of ML models requires a massive amount of good quality data, it is necessary to eliminate concerns about data privacy and ensure high-quality data. To solve this problem, we cast our eyes on the integration of CML and smart contracts. Based on blockchain, smart contracts enable automatic execution of data preserving and validation, as well as the continuity of CML model training. In our simulation experiments, we define incentive mechanisms on the smart contract, investigate the important factors such as the number of features in the dataset (num_words), the size of the training data, the cost for the data holders to submit data, etc., and conclude how these factors impact the performance metrics of the model: the accuracy of the trained model, the gap between the accuracies of the model before and after simulation, and the time to use up the balance of bad agent. For instance, the increase of the value of num_words leads to higher model accuracy and eliminates the negative influence of malicious agents in a shorter time from our observation of the experiment results. Statistical analyses show that with the help of smart contracts, the influence of invalid data is efficiently diminished and model robustness is maintained. We also discuss the gap in existing research and put forward possible future directions for further works.
Survey on the Convergence of Machine Learning and Blockchain
Jan 04, 2022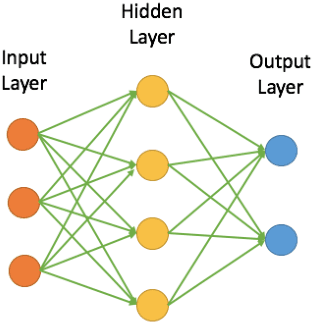
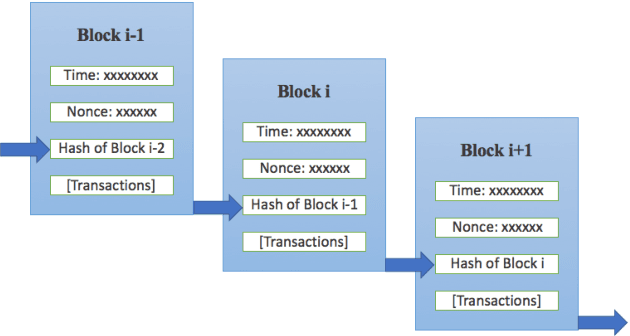

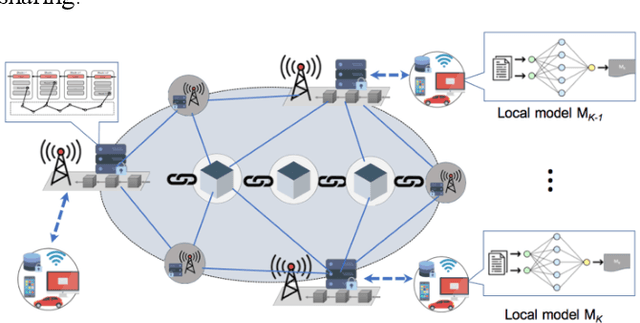
Machine learning (ML) has been pervasively researched nowadays and it has been applied in many aspects of real life. Nevertheless, issues of model and data still accompany the development of ML. For instance, training of traditional ML models is limited to the access of data sets, which are generally proprietary; published ML models may soon be out of date without update of new data and continuous training; malicious data contributors may upload wrongly labeled data that leads to undesirable training results; and the abuse of private data and data leakage also exit. With the utilization of blockchain, an emerging and swiftly developing technology, these problems can be efficiently solved. In this paper, we conduct a survey of the convergence of collaborative ML and blockchain. We investigate different ways of combination of these two technologies, and their fields of application. We also discuss the limitations of current research and their future directions.