 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanizing the Machine: Proxy Attacks to Mislead LLM Detectors
Oct 25, 2024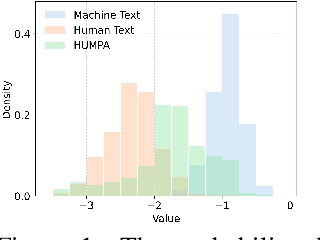
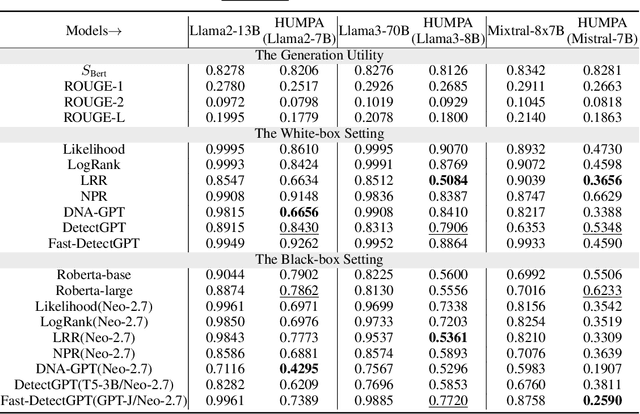
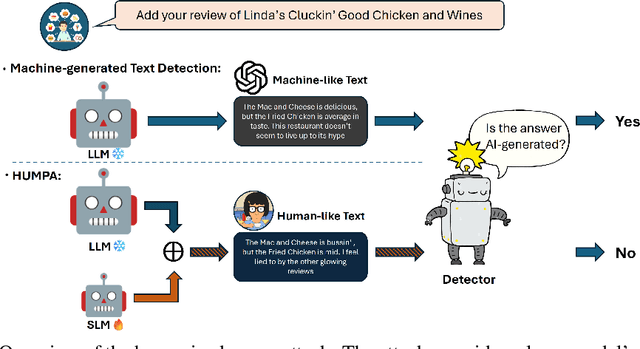
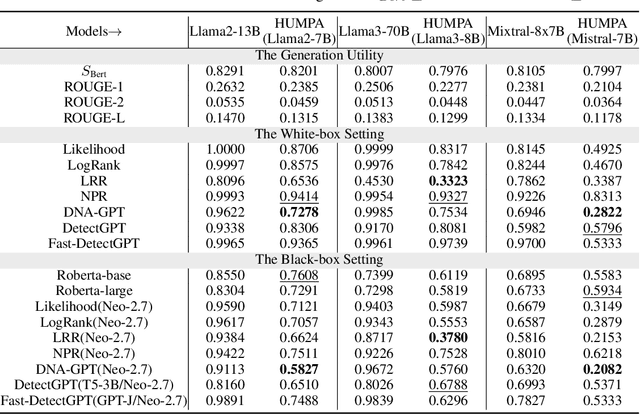
The advent of large language models (LLMs) has revolutionized the field of text generation, producing outputs that closely mimic human-like writing. Although academic and industrial institutions have developed detectors to prevent the malicious usage of LLM-generated texts, other research has doubt about the robustness of these systems. To stress test these detectors, we introduce a proxy-attack strategy that effortlessly compromises LLMs, causing them to produce outputs that align with human-written text and mislead detection systems. Our method attacks the source model by leveraging a reinforcement learning (RL) fine-tuned humanized small language model (SLM) in the decoding phase. Through an in-depth analysis, we demonstrate that our attack strategy is capable of generating responses that are indistinguishable to detectors, preventing them from differentiating between machine-generated and human-written text. We conduct systematic evaluations on extensive datasets using proxy-attacked open-source models, including Llama2-13B, Llama3-70B, and Mixtral-8*7B in both white- and black-box settings. Our findings show that the proxy-attack strategy effectively deceives the leading detectors, resulting in an average AUROC drop of 70.4% across multiple datasets, with a maximum drop of 90.3% on a single dataset. Furthermore, in cross-discipline scenarios, our strategy also bypasses these detectors, leading to a significant relative decrease of up to 90.9%, while in cross-language scenario, the drop reaches 91.3%. Despite our proxy-attack strategy successfully bypassing the detectors with such significant relative drops, we find that the generation quality of the attacked models remains preserved, even within a modest utility budget, when compared to the text produced by the original, unattacked source model.
Characterizing Datasets for Social Visual Question Answering, and the New TinySocial Dataset
Oct 08, 2020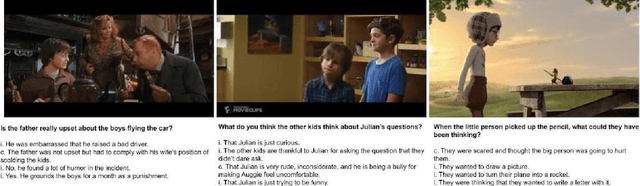
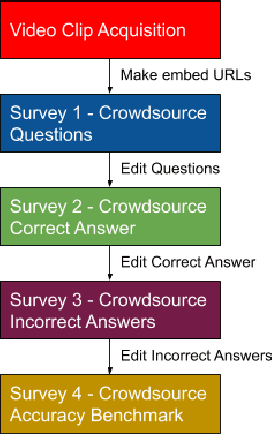
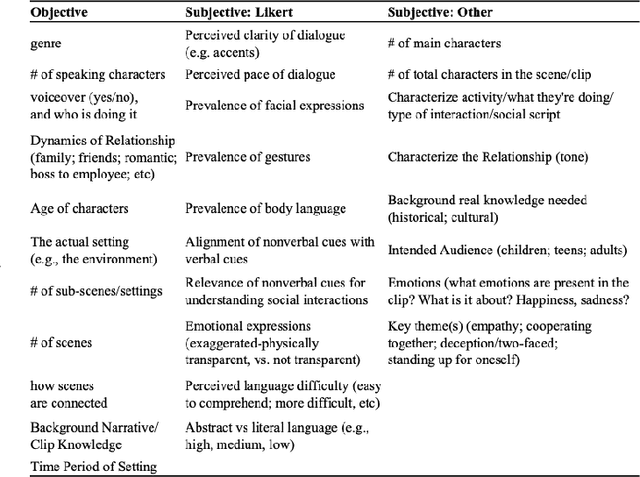
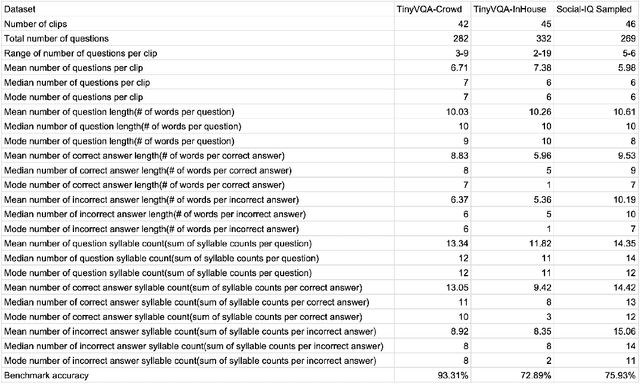
Modern social intelligence includes the ability to watch videos and answer questions about social and theory-of-mind-related content, e.g., for a scene in Harry Potter, "Is the father really upset about the boys flying the car?" Social visual question answering (social VQA) is emerging as a valuable methodology for studying social reasoning in both humans (e.g., children with autism) and AI agents. However, this problem space spans enormous variations in both videos and questions. We discuss methods for creating and characterizing social VQA datasets, including 1) crowdsourcing versus in-house authoring, including sample comparisons of two new datasets that we created (TinySocial-Crowd and TinySocial-InHouse) and the previously existing Social-IQ dataset; 2) a new rubric for characterizing the difficulty and content of a given video; and 3) a new rubric for characterizing question types. We close by describing how having well-characterized social VQA datasets will enhance the explainability of AI agents and can also inform assessments and educational interventions for people.