 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Features Aided Multi-Scale Reconstruction of Inter-Modality Magnetic Resonance Images
Paper and Code
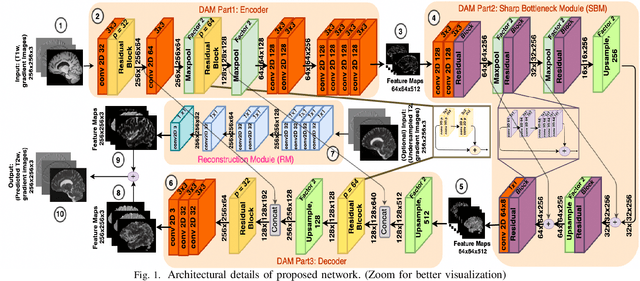
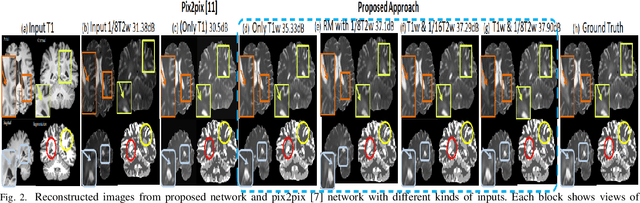
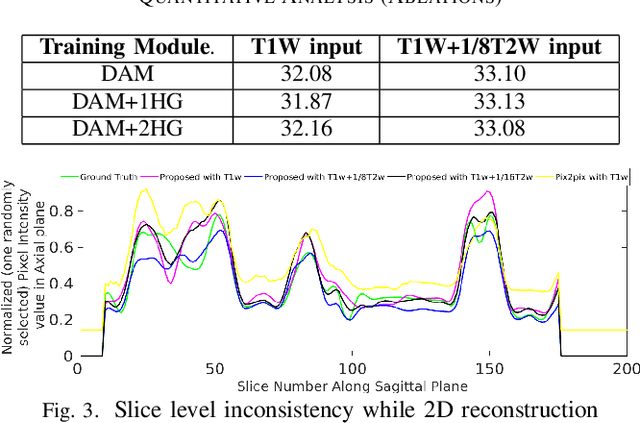

Long acquisition time (AQT) due to series acquisition of multi-modality MR images (especially T2 weighted images (T2WI) with longer AQT), though beneficial for disease diagnosis, is practically undesirable. We propose a novel deep network based solution to reconstruct T2W images from T1W images (T1WI) using an encoder-decoder architecture. The proposed learning is aided with semantic features by using multi-channel input with intensity values and gradient of image in two orthogonal directions. A reconstruction module (RM) augmenting the network along with a domain adaptation module (DAM) which is an encoder-decoder model built-in with sharp bottleneck module (SBM) is trained via modular training. The proposed network significantly reduces the total AQT with negligible qualitative artifacts and quantitative loss (reconstructs one volume in approximately 1 second). The testing is done on publicly available dataset with real MR images, and the proposed network shows (approximately 1dB) increase in PSNR over SOTA.