 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated speech tools for helping communities process restricted-access corpora for language revival efforts
Apr 24, 2022
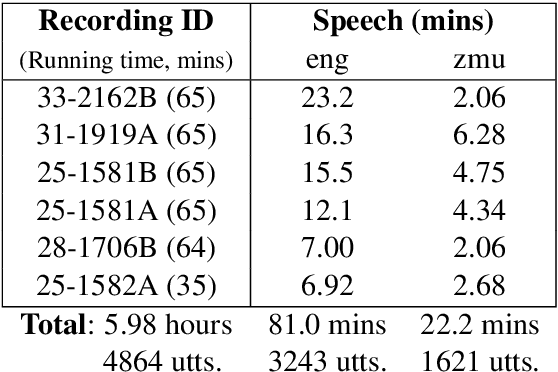
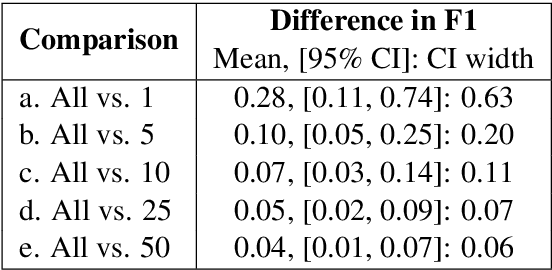
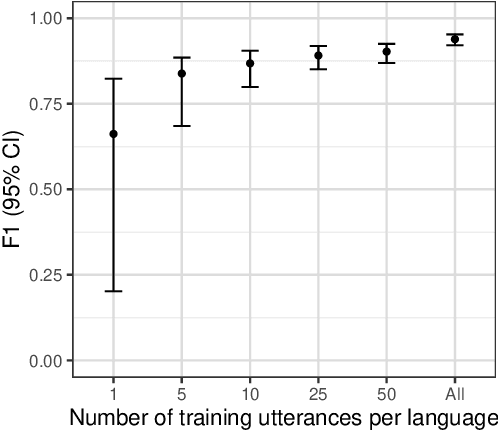
Many archival recordings of speech from endangered languages remain unannotated and inaccessible to community members and language learning programs. One bottleneck is the time-intensive nature of annotation. An even narrower bottleneck occurs for recordings with access constraints, such as language that must be vetted or filtered by authorised community members before annotation can begin. We propose a privacy-preserving workflow to widen both bottlenecks for recordings where speech in the endangered language is intermixed with a more widely-used language such as English for meta-linguistic commentary and questions (e.g. What is the word for 'tree'?). We integrate voice activity detection (VAD), spoken language identification (SLI), and automatic speech recognition (ASR) to transcribe the metalinguistic content, which an authorised person can quickly scan to triage recordings that can be annotated by people with lower levels of access. We report work-in-progress processing 136 hours archival audio containing a mix of English and Muruwari. Our collaborative work with the Muruwari custodian of the archival materials show that this workflow reduces metalanguage transcription time by 20% even given only minimal amounts of annotated training data: 10 utterances per language for SLI and for ASR at most 39 minutes, and possibly as little as 39 seconds.
Leveraging neural representations for facilitating access to untranscribed speech from endangered languages
Mar 26, 2021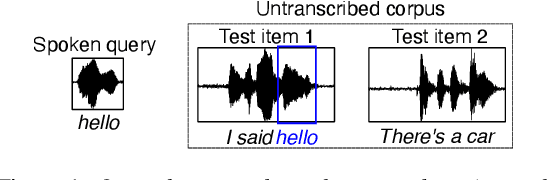
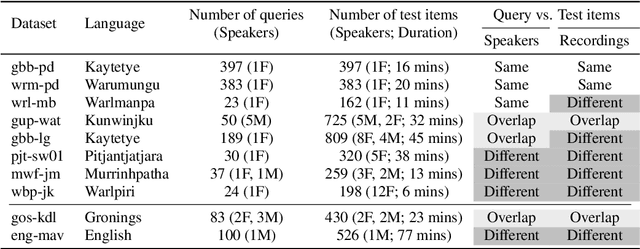
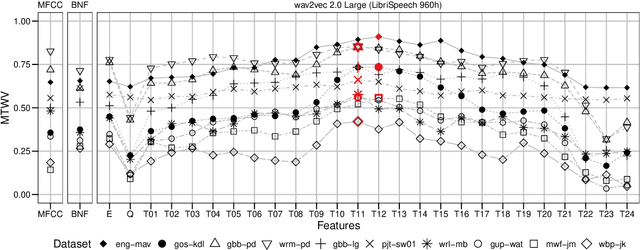
For languages with insufficient resources to train speech recognition systems, query-by-example spoken term detection (QbE-STD) offers a way of accessing an untranscribed speech corpus by helping identify regions where spoken query terms occur. Yet retrieval performance can be poor when the query and corpus are spoken by different speakers and produced in different recording conditions. Using data selected from a variety of speakers and recording conditions from 7 Australian Aboriginal languages and a regional variety of Dutch, all of which are endangered or vulnerable, we evaluated whether QbE-STD performance on these languages could be improved by leveraging representations extracted from the pre-trained English wav2vec 2.0 model. Compared to the use of Mel-frequency cepstral coefficients and bottleneck features, we find that representations from the middle layers of the wav2vec 2.0 Transformer offer large gains in task performance (between 56% and 86%). While features extracted using the pre-trained English model yielded improved detection on all the evaluation languages, better detection performance was associated with the evaluation language's phonological similarity to English.