 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Distributed Multi-Agent Reinforcement Learning for Consensus Control of Quadcopters
Jun 01, 2026This paper proposes a Network Distributed Multi-Agent Reinforcement Learning (ND-MARL) framework for quadcopter consensus control. Compared to conventional multi-agent MARL formulations that rely on centralized planning or fully decentralized execution, ND-MARL incorporates the swarm communication graph into the decision process. Under a 2-Neighbor communication topology, each agent observes information of only two neighbors and outputs an action through a distributed policy. A high-level distributed consensus planner is trained using Multi-Agent Soft Actor-Critic (MASAC) and embedded in a hierarchical stack to generate reference target positions tracked by a low-level quadcopter controller. Results demonstrate smooth consensus trajectories and planner-tracker integration when compared to a centralized MARL controller. Most notably, the learned controller exhibits zero-shot scalability, as policies trained on a three-agent system are deployed to swarms of up to 250 agents under the same 2-Neighbor communication topology without retraining or fine-tuning, achieving consistent convergence with increasing steady-state spread at large team sizes due to sparse information propagation. These findings highlight ND-MARL as a stable framework for distributed, communication-aware quadcopter consensus control.
* This is the Author Accepted Manuscript version of a paper accepted for publication. The final published version is available via IEEE Xplore
BirdRecorder's AI on Sky: Safeguarding birds of prey by detection and classification of tiny objects around wind turbines
Aug 25, 2025



The urgent need for renewable energy expansion, particularly wind power, is hindered by conflicts with wildlife conservation. To address this, we developed BirdRecorder, an advanced AI-based anti-collision system to protect endangered birds, especially the red kite (Milvus milvus). Integrating robotics, telemetry, and high-performance AI algorithms, BirdRecorder aims to detect, track, and classify avian species within a range of 800 m to minimize bird-turbine collisions. BirdRecorder integrates advanced AI methods with optimized hardware and software architectures to enable real-time image processing. Leveraging Single Shot Detector (SSD) for detection, combined with specialized hardware acceleration and tracking algorithms, our system achieves high detection precision while maintaining the speed necessary for real-time decision-making. By combining these components, BirdRecorder outperforms existing approaches in both accuracy and efficiency. In this paper, we summarize results on field tests and performance of the BirdRecorder system. By bridging the gap between renewable energy expansion and wildlife conservation, BirdRecorder contributes to a more sustainable coexistence of technology and nature.
Multitask Reinforcement Learning for Quadcopter Attitude Stabilization and Tracking using Graph Policy
Mar 11, 2025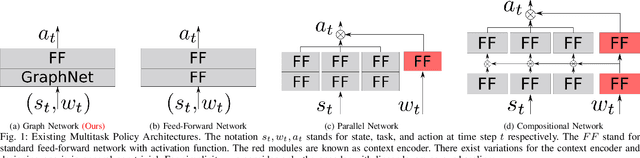
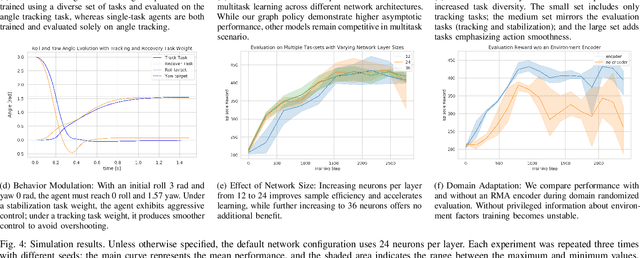
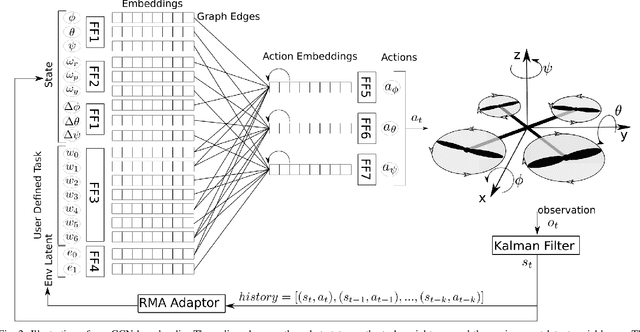
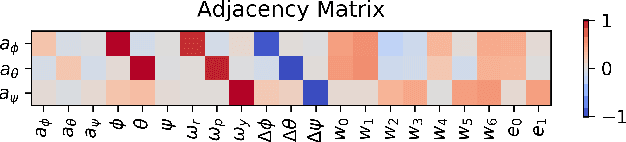
Quadcopter attitude control involves two tasks: smooth attitude tracking and aggressive stabilization from arbitrary states. Although both can be formulated as tracking problems, their distinct state spaces and control strategies complicate a unified reward function. We propose a multitask deep reinforcement learning framework that leverages parallel simulation with IsaacGym and a Graph Convolutional Network (GCN) policy to address both tasks effectively. Our multitask Soft Actor-Critic (SAC) approach achieves faster, more reliable learning and higher sample efficiency than single-task methods. We validate its real-world applicability by deploying the learned policy - a compact two-layer network with 24 neurons per layer - on a Pixhawk flight controller, achieving 400 Hz control without extra computational resources. We provide our code at https://github.com/robot-perception-group/GraphMTSAC\_UAV/.
ZebraPose: Zebra Detection and Pose Estimation using only Synthetic Data
Aug 20, 2024Synthetic data is increasingly being used to address the lack of labeled images in uncommon domains for deep learning tasks. A prominent example is 2D pose estimation of animals, particularly wild species like zebras, for which collecting real-world data is complex and impractical. However, many approaches still require real images, consistency and style constraints, sophisticated animal models, and/or powerful pre-trained networks to bridge the syn-to-real gap. Moreover, they often assume that the animal can be reliably detected in images or videos, a hypothesis that often does not hold, e.g. in wildlife scenarios or aerial images. To solve this, we use synthetic data generated with a 3D photorealistic simulator to obtain the first synthetic dataset that can be used for both detection and 2D pose estimation of zebras without applying any of the aforementioned bridging strategies. Unlike previous works, we extensively train and benchmark our detection and 2D pose estimation models on multiple real-world and synthetic datasets using both pre-trained and non-pre-trained backbones. These experiments show how the models trained from scratch and only with synthetic data can consistently generalize to real-world images of zebras in both tasks. Moreover, we show it is possible to easily generalize those same models to 2D pose estimation of horses with a minimal amount of real-world images to account for the domain transfer. Code, results, trained models; and the synthetic, training, and validation data, including 104K manually labeled frames, are provided as open-source at https://zebrapose.is.tue.mpg.de/
Adaptive Reinforcement Learning for Robot Control
Apr 29, 2024Deep reinforcement learning (DRL) has shown remarkable success in simulation domains, yet its application in designing robot controllers remains limited, due to its single-task orientation and insufficient adaptability to environmental changes. To overcome these limitations, we present a novel adaptive agent that leverages transfer learning techniques to dynamically adapt policy in response to different tasks and environmental conditions. The approach is validated through the blimp control challenge, where multitasking capabilities and environmental adaptability are essential. The agent is trained using a custom, highly parallelized simulator built on IsaacGym. We perform zero-shot transfer to fly the blimp in the real world to solve various tasks. We share our code at \url{https://github.com/robot-perception-group/adaptive\_agent/}.
Airship Formations for Animal Motion Capture and Behavior Analysis
Apr 13, 2024
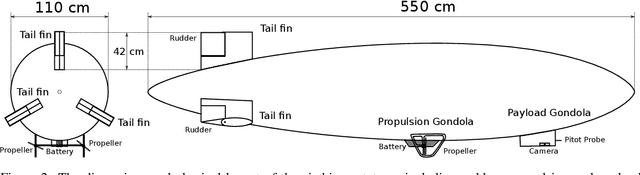

Using UAVs for wildlife observation and motion capture offers manifold advantages for studying animals in the wild, especially grazing herds in open terrain. The aerial perspective allows observation at a scale and depth that is not possible on the ground, offering new insights into group behavior. However, the very nature of wildlife field-studies puts traditional fixed wing and multi-copter systems to their limits: limited flight time, noise and safety aspects affect their efficacy, where lighter than air systems can remain on station for many hours. Nevertheless, airships are challenging from a ground handling perspective as well as from a control point of view, being voluminous and highly affected by wind. In this work, we showcase a system designed to use airship formations to track, follow, and visually record wild horses from multiple angles, including airship design, simulation, control, on board computer vision, autonomous operation and practical aspects of field experiments.
DynaPix SLAM: A Pixel-Based Dynamic SLAM Approach
Sep 18, 2023In static environments, visual simultaneous localization and mapping (V-SLAM) methods achieve remarkable performance. However, moving objects severely affect core modules of such systems like state estimation and loop closure detection. To address this, dynamic SLAM approaches often use semantic information, geometric constraints, or optical flow to mask features associated with dynamic entities. These are limited by various factors such as a dependency on the quality of the underlying method, poor generalization to unknown or unexpected moving objects, and often produce noisy results, e.g. by masking static but movable objects or making use of predefined thresholds. In this paper, to address these trade-offs, we introduce a novel visual SLAM system, DynaPix, based on per-pixel motion probability values. Our approach consists of a new semantic-free probabilistic pixel-wise motion estimation module and an improved pose optimization process. Our per-pixel motion probability estimation combines a novel static background differencing method on both images and optical flows from splatted frames. DynaPix fully integrates those motion probabilities into both map point selection and weighted bundle adjustment within the tracking and optimization modules of ORB-SLAM2. We evaluate DynaPix against ORB-SLAM2 and DynaSLAM on both GRADE and TUM-RGBD datasets, obtaining lower errors and longer trajectory tracking times. We will release both source code and data upon acceptance of this work.
Simulation of Dynamic Environments for SLAM
May 07, 2023



Simulation engines are widely adopted in robotics. However, they lack either full simulation control, ROS integration, realistic physics, or photorealism. Recently, synthetic data generation and realistic rendering has advanced tasks like target tracking and human pose estimation. However, when focusing on vision applications, there is usually a lack of information like sensor measurements or time continuity. On the other hand, simulations for most robotics tasks are performed in (semi)static environments, with specific sensors and low visual fidelity. To solve this, we introduced in our previous work a fully customizable framework for generating realistic animated dynamic environments (GRADE) [1]. We use GRADE to generate an indoor dynamic environment dataset and then compare multiple SLAM algorithms on different sequences. By doing that, we show how current research over-relies on known benchmarks, failing to generalize. Our tests with refined YOLO and Mask R-CNN models provide further evidence that additional research in dynamic SLAM is necessary. The code, results, and generated data are provided as open-source at https://eliabntt.github.io/grade-rrSimulation of Dynamic Environments for SLAM
Learning from synthetic data generated with GRADE
May 07, 2023



Recently, synthetic data generation and realistic rendering has advanced tasks like target tracking and human pose estimation. Simulations for most robotics applications are obtained in (semi)static environments, with specific sensors and low visual fidelity. To solve this, we present a fully customizable framework for generating realistic animated dynamic environments (GRADE) for robotics research, first introduced in [1]. GRADE supports full simulation control, ROS integration, realistic physics, while being in an engine that produces high visual fidelity images and ground truth data. We use GRADE to generate a dataset focused on indoor dynamic scenes with people and flying objects. Using this, we evaluate the performance of YOLO and Mask R-CNN on the tasks of segmenting and detecting people. Our results provide evidence that using data generated with GRADE can improve the model performance when used for a pre-training step. We also show that, even training using only synthetic data, can generalize well to real-world images in the same application domain such as the ones from the TUM-RGBD dataset. The code, results, trained models, and the generated data are provided as open-source at https://eliabntt.github.io/grade-rr.
* 5 pages, 5 tables, 2 figures. Accepted for the ICRA 2023 workshop Pretraining for Robotics (https://microsoft.github.io/robotics.pretraining.workshop.icra/). arXiv admin note: substantial text overlap with arXiv:2303.04466
Synthetic Data-based Detection of Zebras in Drone Imagery
Apr 30, 2023



Datasets that allow the training of common objects or human detectors are widely available. These come in the form of labelled real-world images and require either a significant amount of human effort, with a high probability of errors such as missing labels, or very constrained scenarios, e.g. VICON systems. Likewise, uncommon scenarios, like aerial views, animals, like wild zebras, or difficult-to-obtain information as human shapes, are hardly available. To overcome this, usage of synthetic data generation with realistic rendering technologies has recently gained traction and advanced tasks like target tracking and human pose estimation. However, subjects such as wild animals are still usually not well represented in such datasets. In this work, we first show that a pre-trained YOLO detector can not identify zebras in real images recorded from aerial viewpoints. To solve this, we present an approach for training an animal detector using only synthetic data. We start by generating a novel synthetic zebra dataset using GRADE, a state-of-the-art framework for data generation. The dataset includes RGB, depth, skeletal joint locations, pose, shape and instance segmentations for each subject. We use this to train a YOLO detector from scratch. Through extensive evaluations of our model with real-world data from i) limited datasets available on the internet and ii) a new one collected and manually labelled by us, we show that we can detect zebras by using only synthetic data during training. The code, results, trained models, and both the generated and training data are provided as open-source at https://keeper.mpdl.mpg.de/d/12abb3bb6b12491480d5/.