 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Reinforcement Learning for Quadcopter Attitude Stabilization and Tracking using Graph Policy
Mar 11, 2025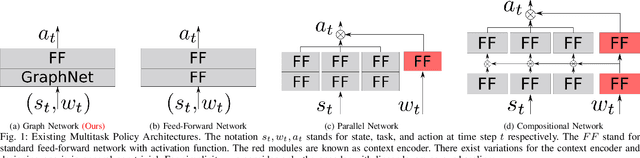
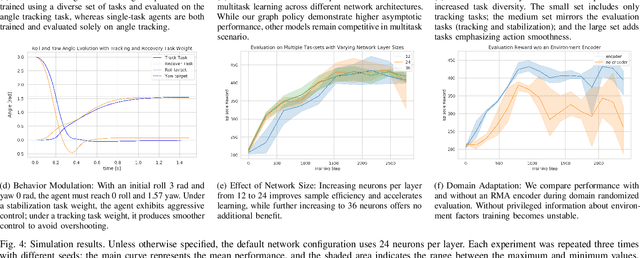
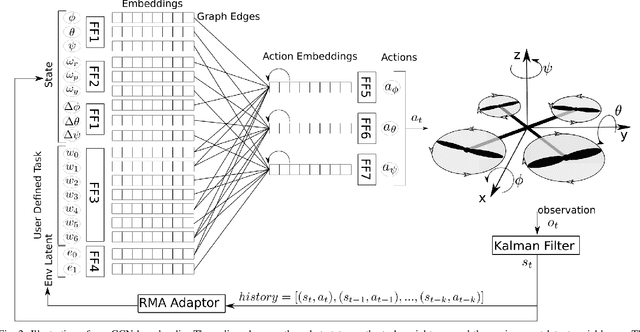
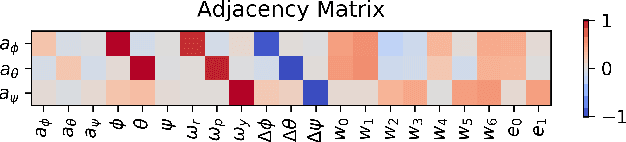
Quadcopter attitude control involves two tasks: smooth attitude tracking and aggressive stabilization from arbitrary states. Although both can be formulated as tracking problems, their distinct state spaces and control strategies complicate a unified reward function. We propose a multitask deep reinforcement learning framework that leverages parallel simulation with IsaacGym and a Graph Convolutional Network (GCN) policy to address both tasks effectively. Our multitask Soft Actor-Critic (SAC) approach achieves faster, more reliable learning and higher sample efficiency than single-task methods. We validate its real-world applicability by deploying the learned policy - a compact two-layer network with 24 neurons per layer - on a Pixhawk flight controller, achieving 400 Hz control without extra computational resources. We provide our code at https://github.com/robot-perception-group/GraphMTSAC\_UAV/.
Adaptive Reinforcement Learning for Robot Control
Apr 29, 2024Deep reinforcement learning (DRL) has shown remarkable success in simulation domains, yet its application in designing robot controllers remains limited, due to its single-task orientation and insufficient adaptability to environmental changes. To overcome these limitations, we present a novel adaptive agent that leverages transfer learning techniques to dynamically adapt policy in response to different tasks and environmental conditions. The approach is validated through the blimp control challenge, where multitasking capabilities and environmental adaptability are essential. The agent is trained using a custom, highly parallelized simulator built on IsaacGym. We perform zero-shot transfer to fly the blimp in the real world to solve various tasks. We share our code at \url{https://github.com/robot-perception-group/adaptive\_agent/}.
Autonomous Blimp Control via H-infinity Robust Deep Residual Reinforcement Learning
Mar 24, 2023Due to their superior energy efficiency, blimps may replace quadcopters for long-duration aerial tasks. However, designing a controller for blimps to handle complex dynamics, modeling errors, and disturbances remains an unsolved challenge. One recent work combines reinforcement learning (RL) and a PID controller to address this challenge and demonstrates its effectiveness in real-world experiments. In the current work, we build on that using an H-infinity robust controller to expand the stability margin and improve the RL agent's performance. Empirical analysis of different mixing methods reveals that the resulting H-infinity-RL controller outperforms the prior PID-RL combination and can handle more complex tasks involving intensive thrust vectoring. We provide our code as open-source at https://github.com/robot-perception-group/robust_deep_residual_blimp.
Multi-Task Reinforcement Learning in Continuous Control with Successor Feature-Based Concurrent Composition
Mar 24, 2023Deep reinforcement learning (DRL) frameworks are increasingly used to solve high-dimensional continuous-control tasks in robotics. However, due to the lack of sample efficiency, applying DRL for online learning is still practically infeasible in the robotics domain. One reason is that DRL agents do not leverage the solution of previous tasks for new tasks. Recent work on multi-tasking DRL agents based on successor features has proven to be quite promising in increasing sample efficiency. In this work, we present a new approach that unifies two prior multi-task RL frameworks, SF-GPI and value composition, for the continuous control domain. We exploit compositional properties of successor features to compose a policy distribution from a set of primitives without training any new policy. Lastly, to demonstrate the multi-tasking mechanism, we present a new benchmark for multi-task continuous control environment based on Raisim. This also facilitates large-scale parallelization to accelerate the experiments. Our experimental results in the Pointmass environment show that our multi-task agent has single task performance on par with soft actor critic (SAC) and the agent can successfully transfer to new unseen tasks where SAC fails. We provide our code as open-source at https://github.com/robot-perception-group/concurrent_composition for the benefit of the community.
Deep Residual Reinforcement Learning based Autonomous Blimp Control
Mar 10, 2022
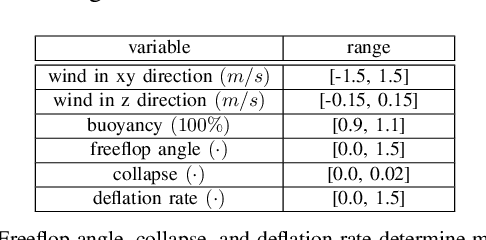
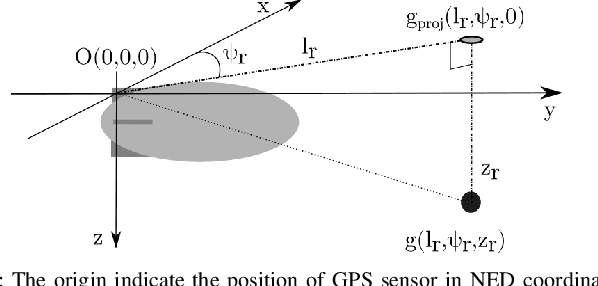
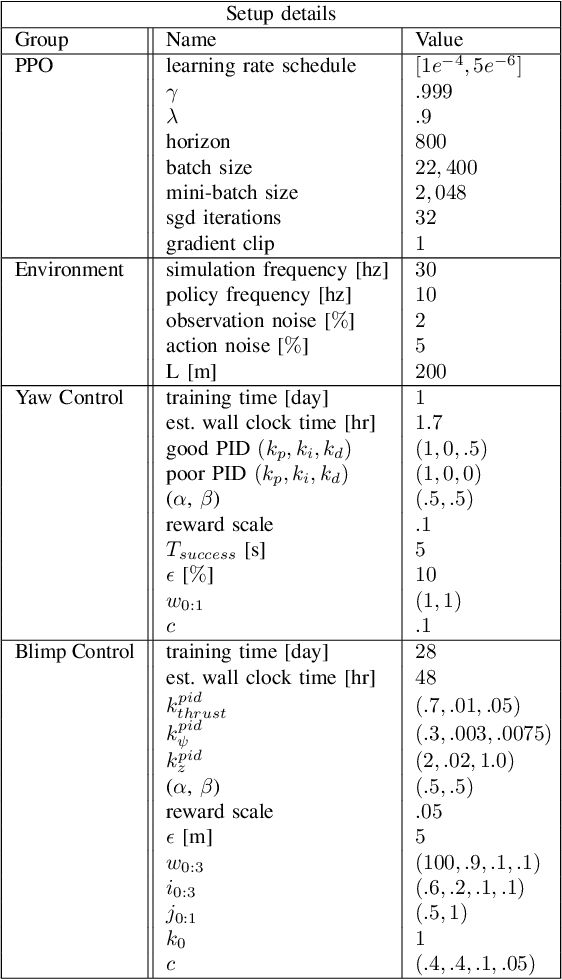
Blimps are well suited to perform long-duration aerial tasks as they are energy efficient, relatively silent and safe. To address the blimp navigation and control task, in previous work we developed a hardware and software-in-the-loop framework and a PID-based controller for large blimps in the presence of wind disturbance. However, blimps have a deformable structure and their dynamics are inherently non-linear and time-delayed, making PID controllers difficult to tune. Thus, often resulting in large tracking errors. Moreover, the buoyancy of a blimp is constantly changing due to variations in ambient temperature and pressure. To address these issues, in this paper we present a learning-based framework based on deep residual reinforcement learning (DRRL), for the blimp control task. Within this framework, we first employ a PID controller to provide baseline performance. Subsequently, the DRRL agent learns to modify the PID decisions by interaction with the environment. We demonstrate in simulation that DRRL agent consistently improves the PID performance. Through rigorous simulation experiments, we show that the agent is robust to changes in wind speed and buoyancy. In real-world experiments, we demonstrate that the agent, trained only in simulation, is sufficiently robust to control an actual blimp in windy conditions. We openly provide the source code of our approach at https://github.com/ robot-perception-group/AutonomousBlimpDRL.
Autonomous Blimp Control using Deep Reinforcement Learning
Sep 27, 2021

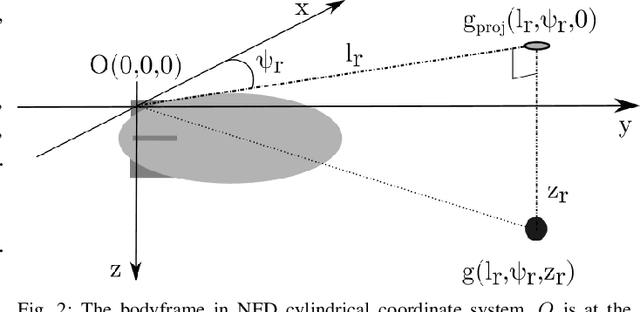

Aerial robot solutions are becoming ubiquitous for an increasing number of tasks. Among the various types of aerial robots, blimps are very well suited to perform long-duration tasks while being energy efficient, relatively silent and safe. To address the blimp navigation and control task, in our recent work, we have developed a software-in-the-loop simulation and a PID-based controller for large blimps in the presence of wind disturbance. However, blimps have a deformable structure and their dynamics are inherently non-linear and time-delayed, often resulting in large trajectory tracking errors. Moreover, the buoyancy of a blimp is constantly changing due to changes in the ambient temperature and pressure. In the present paper, we explore a deep reinforcement learning (DRL) approach to address these issues. We train only in simulation, while keeping conditions as close as possible to the real-world scenario. We derive a compact state representation to reduce the training time and a discrete action space to enforce control smoothness. Our initial results in simulation show a significant potential of DRL in solving the blimp control task and robustness against moderate wind and parameter uncertainty. Extensive experiments are presented to study the robustness of our approach. We also openly provide the source code of our approach.
Simulation and Control of Deformable Autonomous Airships in Turbulent Wind
Dec 31, 2020

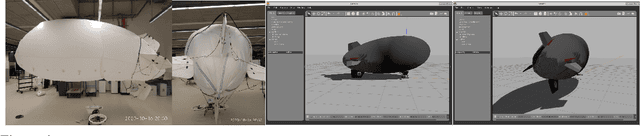
Abstract. Fixed wing and multirotor UAVs are common in the field of robotics. Solutions for simulation and control of these vehicles are ubiquitous. This is not the case for airships, a simulation of which needs to address unique properties, i) dynamic deformation in response to aerodynamic and control forces, ii) high susceptibility to wind and turbulence at low airspeed, iii) high variability in airship designs regarding placement, direction and vectoring of thrusters and control surfaces. We present a flexible framework for modeling, simulation and control of airships, based on the Robot operating system (ROS), simulation environment (Gazebo) and commercial off the shelf (COTS) electronics, both of which are open source. Based on simulated wind and deformation, we predict substantial effects on controllability, verified in real world flight experiments. All our code is shared as open source, for the benefit of the community and to facilitate lighter-than-air vehicle (LTAV) research. https://github.com/robot-perception-group/airship_simulation
AirCapRL: Autonomous Aerial Human Motion Capture using Deep Reinforcement Learning
Aug 01, 2020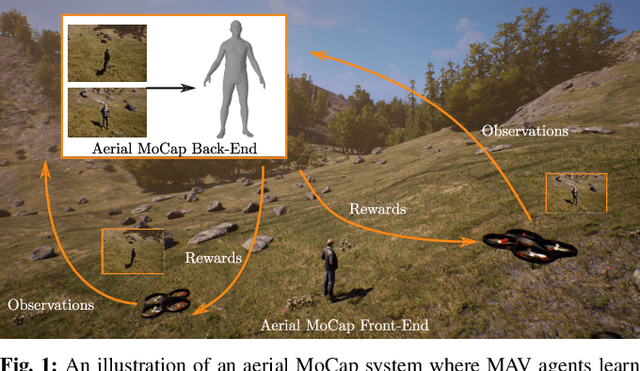



In this letter, we introduce a deep reinforcement learning (RL) based multi-robot formation controller for the task of autonomous aerial human motion capture (MoCap). We focus on vision-based MoCap, where the objective is to estimate the trajectory of body pose and shape of a single moving person using multiple micro aerial vehicles. State-of-the-art solutions to this problem are based on classical control methods, which depend on hand-crafted system and observation models. Such models are difficult to derive and generalize across different systems. Moreover, the non-linearity and non-convexities of these models lead to sub-optimal controls. In our work, we formulate this problem as a sequential decision making task to achieve the vision-based motion capture objectives, and solve it using a deep neural network-based RL method. We leverage proximal policy optimization (PPO) to train a stochastic decentralized control policy for formation control. The neural network is trained in a parallelized setup in synthetic environments. We performed extensive simulation experiments to validate our approach. Finally, real-robot experiments demonstrate that our policies generalize to real world conditions. Video Link: https://bit.ly/38SJfjo Supplementary: https://bit.ly/3evfo1O