 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning based Autonomous Multi-Rotor Landing on Moving Platforms
Feb 25, 2023Multi-rotor UAVs suffer from a restricted range and flight duration due to limited battery capacity. Autonomous landing on a 2D moving platform offers the possibility to replenish batteries and offload data, thus increasing the utility of the vehicle. Classical approaches rely on accurate, complex and difficult-to-derive models of the vehicle and the environment. Reinforcement learning (RL) provides an attractive alternative due to its ability to learn a suitable control policy exclusively from data during a training procedure. However, current methods require several hours to train, have limited success rates and depend on hyperparameters that need to be tuned by trial-and-error. We address all these issues in this work. First, we decompose the landing procedure into a sequence of simpler, but similar learning tasks. This is enabled by applying two instances of the same RL based controller trained for 1D motion for controlling the multi-rotor's movement in both the longitudinal and the lateral direction. Second, we introduce a powerful state space discretization technique that is based on i) kinematic modeling of the moving platform to derive information about the state space topology and ii) structuring the training as a sequential curriculum using transfer learning. Third, we leverage the kinematics model of the moving platform to also derive interpretable hyperparameters for the training process that ensure sufficient maneuverability of the multi-rotor vehicle. The training is performed using the tabular RL method Double Q-Learning. Through extensive simulations we show that the presented method significantly increases the rate of successful landings, while requiring less training time compared to other deep RL approaches. Finally, we deploy and demonstrate our algorithm on real hardware. For all evaluation scenarios we provide statistics on the agent's performance.
Autonomous Blimp Control using Deep Reinforcement Learning
Sep 27, 2021


Aerial robot solutions are becoming ubiquitous for an increasing number of tasks. Among the various types of aerial robots, blimps are very well suited to perform long-duration tasks while being energy efficient, relatively silent and safe. To address the blimp navigation and control task, in our recent work, we have developed a software-in-the-loop simulation and a PID-based controller for large blimps in the presence of wind disturbance. However, blimps have a deformable structure and their dynamics are inherently non-linear and time-delayed, often resulting in large trajectory tracking errors. Moreover, the buoyancy of a blimp is constantly changing due to changes in the ambient temperature and pressure. In the present paper, we explore a deep reinforcement learning (DRL) approach to address these issues. We train only in simulation, while keeping conditions as close as possible to the real-world scenario. We derive a compact state representation to reduce the training time and a discrete action space to enforce control smoothness. Our initial results in simulation show a significant potential of DRL in solving the blimp control task and robustness against moderate wind and parameter uncertainty. Extensive experiments are presented to study the robustness of our approach. We also openly provide the source code of our approach.
Active Visual SLAM with independently rotating camera
May 19, 2021
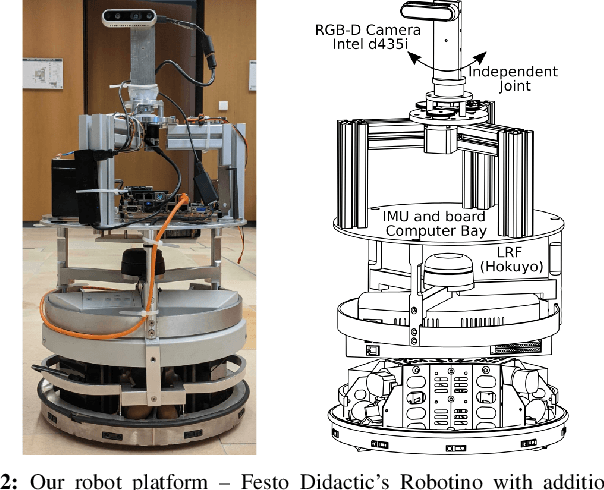
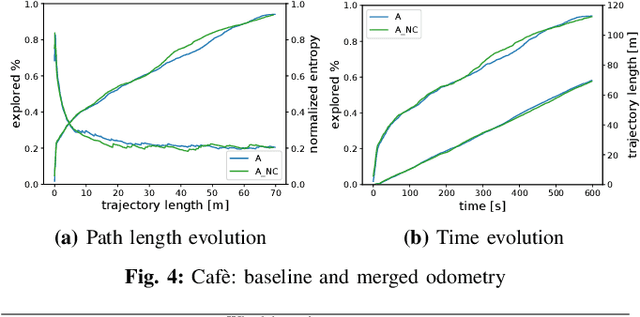
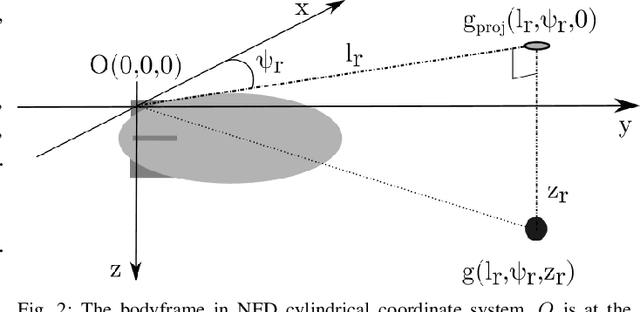
In active Visual-SLAM (V-SLAM), a robot relies on the information retrieved by its cameras to control its own movements for autonomous mapping of the environment. Cameras are usually statically linked to the robot's body, limiting the extra degrees of freedom for visual information acquisition. In this work, we overcome the aforementioned problem by introducing and leveraging an independently rotating camera on the robot base. This enables us to continuously control the heading of the camera, obtaining the desired optimal orientation for active V-SLAM, without rotating the robot itself. However, this additional degree of freedom introduces additional estimation uncertainties, which need to be accounted for. We do this by extending our robot's state estimate to include the camera state and jointly estimate the uncertainties. We develop our method based on a state-of-the-art active V-SLAM approach for omnidirectional robots, and evaluate it through rigorous simulation and real robot experiments. We obtain more accurate maps, with lower energy consumption, while maintaining the benefits of the active approach with respect to the baseline. We also demonstrate how our method easily generalizes to other non-omnidirectional robotic platforms, which was a limitation of the previous approach. Code and implementation details are provided as open-source.
iRotate: Active Visual SLAM for Omnidirectional Robots
Mar 22, 2021

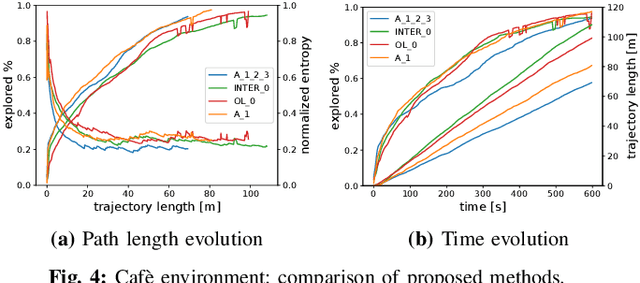
In this letter, we present an active visual SLAM approach for omnidirectional robots. The goal is to generate control commands that allow such a robot to simultaneously localize itself and map an unknown environment while maximizing the amount of information gained and consume as little energy as possible. Leveraging the robot's independent translation and rotation control, we introduce a multi-layered approach for active V-SLAM. The top layer decides on informative goal locations and generates highly informative paths to them. The second and third layers actively re-plan and execute the path, exploiting the continuously updated map. Moreover, they allow the robot to maximize its visibility of 3D visual features in the environment. Through rigorous simulations, real robot experiments and comparisons with the state-of-the-art methods, we demonstrate that our approach achieves similar coverage and lesser overall map entropy while keeping the traversed distance up to 36% less than the other methods. Code and implementation details are provided as open-source.