 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiRotate: Active Visual SLAM for Omnidirectional Robots
Mar 22, 2021

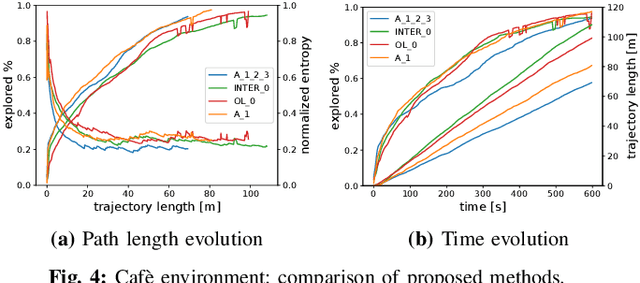
In this letter, we present an active visual SLAM approach for omnidirectional robots. The goal is to generate control commands that allow such a robot to simultaneously localize itself and map an unknown environment while maximizing the amount of information gained and consume as little energy as possible. Leveraging the robot's independent translation and rotation control, we introduce a multi-layered approach for active V-SLAM. The top layer decides on informative goal locations and generates highly informative paths to them. The second and third layers actively re-plan and execute the path, exploiting the continuously updated map. Moreover, they allow the robot to maximize its visibility of 3D visual features in the environment. Through rigorous simulations, real robot experiments and comparisons with the state-of-the-art methods, we demonstrate that our approach achieves similar coverage and lesser overall map entropy while keeping the traversed distance up to 36% less than the other methods. Code and implementation details are provided as open-source.
AirCapRL: Autonomous Aerial Human Motion Capture using Deep Reinforcement Learning
Aug 01, 2020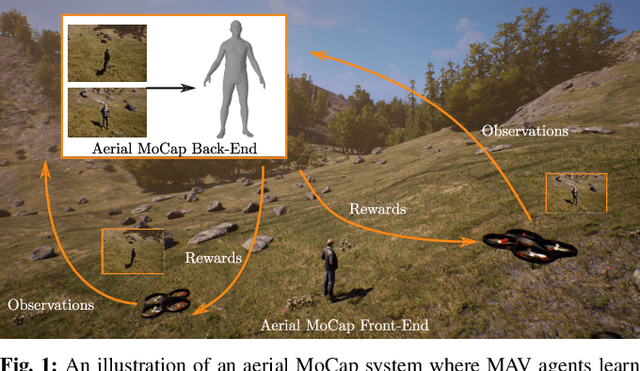



In this letter, we introduce a deep reinforcement learning (RL) based multi-robot formation controller for the task of autonomous aerial human motion capture (MoCap). We focus on vision-based MoCap, where the objective is to estimate the trajectory of body pose and shape of a single moving person using multiple micro aerial vehicles. State-of-the-art solutions to this problem are based on classical control methods, which depend on hand-crafted system and observation models. Such models are difficult to derive and generalize across different systems. Moreover, the non-linearity and non-convexities of these models lead to sub-optimal controls. In our work, we formulate this problem as a sequential decision making task to achieve the vision-based motion capture objectives, and solve it using a deep neural network-based RL method. We leverage proximal policy optimization (PPO) to train a stochastic decentralized control policy for formation control. The neural network is trained in a parallelized setup in synthetic environments. We performed extensive simulation experiments to validate our approach. Finally, real-robot experiments demonstrate that our policies generalize to real world conditions. Video Link: https://bit.ly/38SJfjo Supplementary: https://bit.ly/3evfo1O