 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration
May 27, 2026Visual outcomes are increasingly central to multimodal large language models, making reliable and fine-grained verification essential for scaling generalist foundation models. In this work, we investigate multimodal meta-verification, which leverages verifier-generated rationales rather than decision-only signals, and explore how to effectively incorporate meta-verification feedback into multimodal verifier training. We identify two key findings. First, symbolic verifier outputs (e.g., bounding boxes) outperform textual explanations as meta-verification rationales, enabling efficient rule-based reinforcement learning rewards while avoiding reliance on model-based rewards from auxiliary judge models. Second, decoupling reinforcement learning objectives for binary judgment and meta-verification substantially outperforms joint reward optimization, due to intrinsic differences in output structure and learning dynamics. Based on these insights, we train OmniVerifier-M1, a generalist visual verifier leveraging symbolic meta-verification and decoupled reinforcement learning. OmniVerifier-M1 provides robust verification and fine-grained error localization, and further enables M1-TTS, a verifier-driven agentic generation system achieving dynamic region-level self-correction. This approach paves the way for more reliable, interpretable, and fine-grained multimodal verification, supporting safer and more controllable foundation model deployment.
Compositional Attribute Imbalance in Vision Datasets
Jun 17, 2025



Visual attribute imbalance is a common yet underexplored issue in image classification, significantly impacting model performance and generalization. In this work, we first define the first-level and second-level attributes of images and then introduce a CLIP-based framework to construct a visual attribute dictionary, enabling automatic evaluation of image attributes. By systematically analyzing both single-attribute imbalance and compositional attribute imbalance, we reveal how the rarity of attributes affects model performance. To tackle these challenges, we propose adjusting the sampling probability of samples based on the rarity of their compositional attributes. This strategy is further integrated with various data augmentation techniques (such as CutMix, Fmix, and SaliencyMix) to enhance the model's ability to represent rare attributes. Extensive experiments on benchmark datasets demonstrate that our method effectively mitigates attribute imbalance, thereby improving the robustness and fairness of deep neural networks. Our research highlights the importance of modeling visual attribute distributions and provides a scalable solution for long-tail image classification tasks.
ProTCT: Projection quantification and fidelity constraint integrated deep reconstruction for Tangential CT
May 09, 2025Tangential computed tomography (TCT) is a useful tool for imaging the large-diameter samples, such as oil pipelines and rockets. However, TCT projections are truncated along the detector direction, resulting in degraded slices with radial artifacts. Meanwhile, existing methods fail to reconstruct decent images because of the ill-defined sampling condition in the projection domain and oversmoothing in the cross-section domain. In this paper, we propose a projection quantification and fidelity constraint integrated deep TCT reconstruction method (ProTCT) to improve the slice quality. Specifically, the sampling conditions for reconstruction are analysed, offering practical guidelines for TCT system design. Besides, a deep artifact-suppression network together with a fidelity-constraint module that operates across both projection and cross-section domains to remove artifacts and restore edge details. Demonstrated on simulated and real datasets, the ProTCT shows good performance in structure restoration and detail retention. This work contributes to exploring the sampling condition and improving the slice quality of TCT, further promoting the application of large view field CT imaging.
Revealing Bias Formation in Deep Neural Networks Through the Geometric Mechanisms of Human Visual Decoupling
Feb 17, 2025Deep neural networks (DNNs) often exhibit biases toward certain categories during object recognition, even under balanced training data conditions. The intrinsic mechanisms underlying these biases remain unclear. Inspired by the human visual system, which decouples object manifolds through hierarchical processing to achieve object recognition, we propose a geometric analysis framework linking the geometric complexity of class-specific perceptual manifolds in DNNs to model bias. Our findings reveal that differences in geometric complexity can lead to varying recognition capabilities across categories, introducing biases. To support this analysis, we present the Perceptual-Manifold-Geometry library, designed for calculating the geometric properties of perceptual manifolds.
Koopman Methods for Estimation of Animal Motions over Unknown, Regularly Embedded Submanifolds
Mar 10, 2022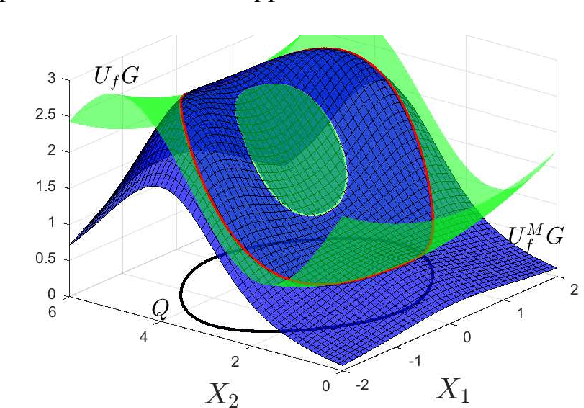
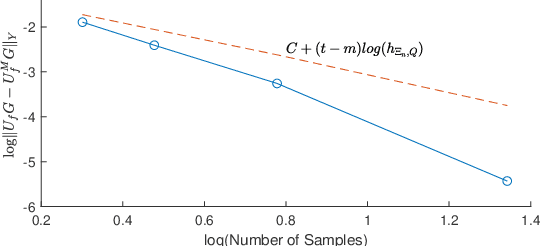
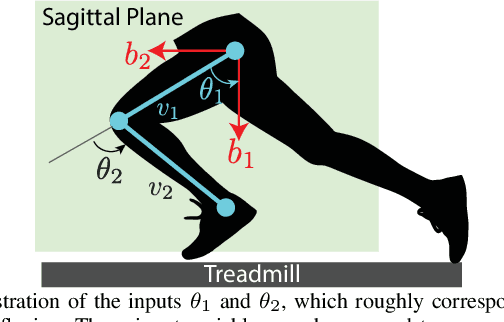

This paper introduces a data-dependent approximation of the forward kinematics map for certain types of animal motion models. It is assumed that motions are supported on a low-dimensional, unknown configuration manifold $Q$ that is regularly embedded in high dimensional Euclidean space $X:=\mathbb{R}^d$. This paper introduces a method to estimate forward kinematics from the unknown configuration submanifold $Q$ to an $n$-dimensional Euclidean space $Y:=\mathbb{R}^n$ of observations. A known reproducing kernel Hilbert space (RKHS) is defined over the ambient space $X$ in terms of a known kernel function, and computations are performed using the known kernel defined on the ambient space $X$. Estimates are constructed using a certain data-dependent approximation of the Koopman operator defined in terms of the known kernel on $X$. However, the rate of convergence of approximations is studied in the space of restrictions to the unknown manifold $Q$. Strong rates of convergence are derived in terms of the fill distance of samples in the unknown configuration manifold, provided that a novel regularity result holds for the Koopman operator. Additionally, we show that the derived rates of convergence can be applied in some cases to estimates generated by the extended dynamic mode decomposition (EDMD) method. We illustrate characteristics of the estimates for simulated data as well as samples collected during motion capture experiments.
Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline
Jun 09, 2021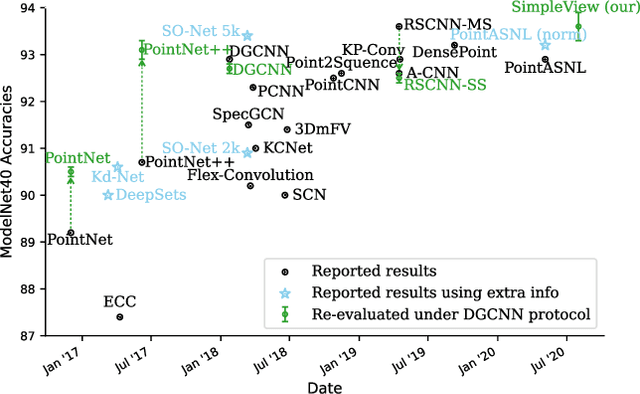

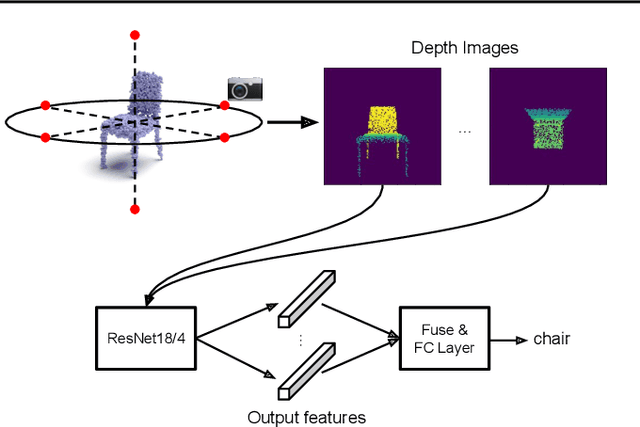
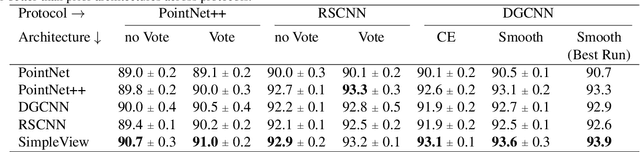
Processing point cloud data is an important component of many real-world systems. As such, a wide variety of point-based approaches have been proposed, reporting steady benchmark improvements over time. We study the key ingredients of this progress and uncover two critical results. First, we find that auxiliary factors like different evaluation schemes, data augmentation strategies, and loss functions, which are independent of the model architecture, make a large difference in performance. The differences are large enough that they obscure the effect of architecture. When these factors are controlled for, PointNet++, a relatively older network, performs competitively with recent methods. Second, a very simple projection-based method, which we refer to as SimpleView, performs surprisingly well. It achieves on par or better results than sophisticated state-of-the-art methods on ModelNet40 while being half the size of PointNet++. It also outperforms state-of-the-art methods on ScanObjectNN, a real-world point cloud benchmark, and demonstrates better cross-dataset generalization. Code is available at https://github.com/princeton-vl/SimpleView.
Learning Hash Codes via Hamming Distance Targets
Oct 01, 2018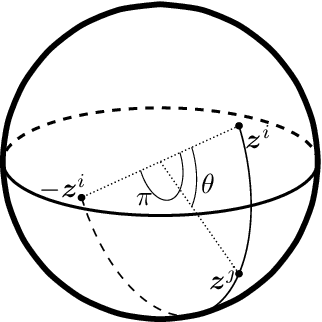
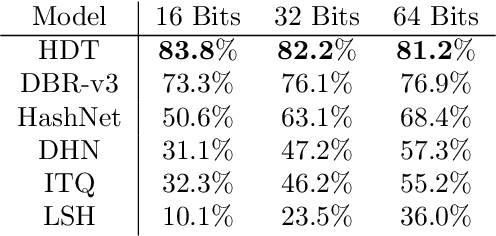
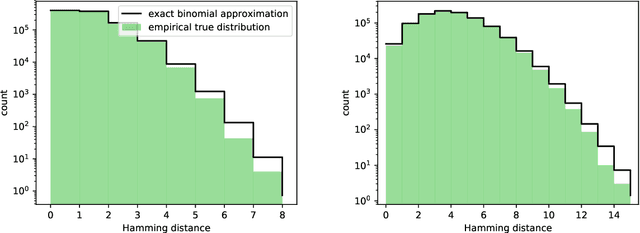
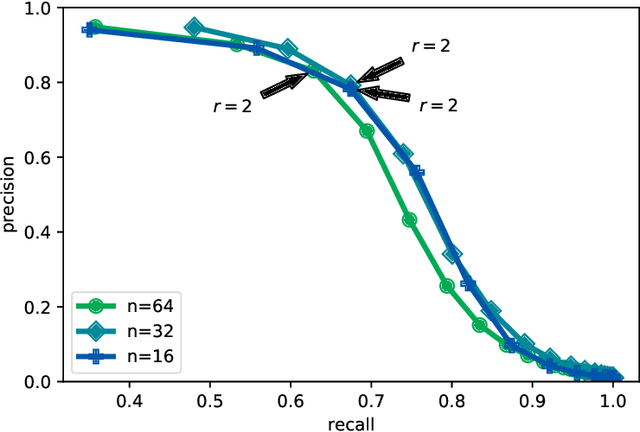
We present a powerful new loss function and training scheme for learning binary hash codes with any differentiable model and similarity function. Our loss function improves over prior methods by using log likelihood loss on top of an accurate approximation for the probability that two inputs fall within a Hamming distance target. Our novel training scheme obtains a good estimate of the true gradient by better sampling inputs and evaluating loss terms between all pairs of inputs in each minibatch. To fully leverage the resulting hashes, we use multi-indexing. We demonstrate that these techniques provide large improvements to a similarity search tasks. We report the best results to date on competitive information retrieval tasks for ImageNet and SIFT 1M, improving MAP from 73% to 84% and reducing query cost by a factor of 2-8, respectively.
Convolutional Hashing for Automated Scene Matching
Feb 09, 2018

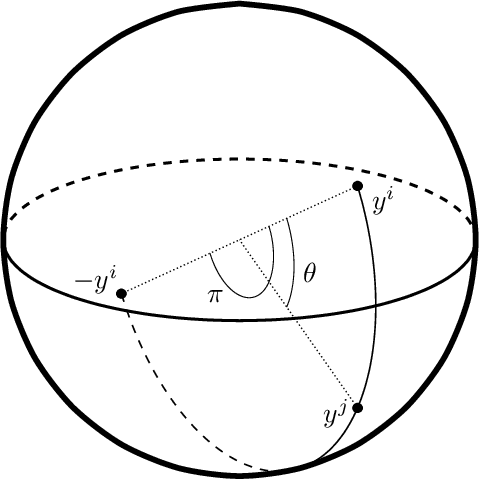
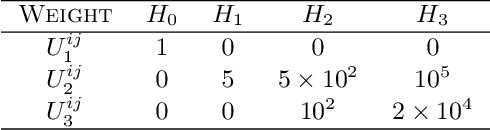
We present a powerful new loss function and training scheme for learning binary hash functions. In particular, we demonstrate our method by creating for the first time a neural network that outperforms state-of-the-art Haar wavelets and color layout descriptors at the task of automated scene matching. By accurately relating distance on the manifold of network outputs to distance in Hamming space, we achieve a 100-fold reduction in nontrivial false positive rate and significantly higher true positive rate. We expect our insights to provide large wins for hashing models applied to other information retrieval hashing tasks as well.